
慎入,作者高并发搞得少(没搞过),这里面水太深,什么高并发,大流量的东西都是虚拟的,作者还太年轻,没有那个经历,把握不住。系统只有几QPS,开心快乐就行,不PK,文明PK。

我关注的大佬更新了,在干货文章的下面有这么一小条:

我承认我有赌的成分,点进去一看,果然是广告。说真的,内容看起来还是很有吸引力的,但是贫穷阻止了我消费的冲动。
作为一个高并发的门外汉,尝试结合学过的课程和一些网上的资料来整理一下对于高并发的认识。——实战是不可能实战的,只能动动嘴皮这样子。
什么是高并发
高并发指的是系统同时处理很多请求。
高并发是一个结果导向的东西,例如,常见的高并发场景有:淘宝的双11、春运时的抢票、微博大V的热点新闻等,这些典型场景并不是陡然出世,而是随着业务发展的发展而逐渐出现。像2020年淘宝双11全球狂欢季,订单创建峰值达到了惊人的58.3万笔/秒,4年前的2016年,这个数字大概是四分之一,再往前四年,这个数据不可考,但是肯定就没这么夸张了。
高并发的业务场景出现了,随之而来的就是要支持这个高并发业务场景的架构——技术要为业务服务,业务倒逼技术发展。高并发的架构也不是某个天才冥思苦想或者灵机一动,这个过程是随着业务的发展而演进。用一个比喻,先有了秋名山,才到了老司机。
那到底多大并发才算高并发呢?
这个本身是没有具体标准的事情,只看数据是不行的,要结合具体的场景。不能说10W QPS的秒杀是高并发,而1W QPS的信息流就不是高并发。信息流场景涉及复杂的推荐模型和各种人工策略,它的业务逻辑可能比秒杀场景复杂10倍不止。业务场景不一样,执行复杂度不一样,单看并发量也没有意义。
总结就是,高并发无定势,是要和具体的业务场景相结合的。无高并发场景,无高并发架构。
高并发目标
宏观目标
高并发绝不意味着只追求高性能。从宏观角度看,高并发系统设计的目标有三个:高性能、高可用,以及高可扩展。就是所谓的“三高”,三高不是孤立的,而是相互支撑的。
1、高性能:性能体现了系统的并行处理能力,在有限的硬件投入下,提高性能意味着节省成本。同时,性能也反映了用户体验,响应时间分别是100毫秒和1秒,给用户的感受是完全不同的。
2、高可用:表示系统可以正常服务的时间。一个全年不停机、无故障;另一个隔三差五出线上事故、宕机,用户肯定选择前者。另外,如果系统只能做到90%可用,也会大大拖累业务。
3、高扩展:表示系统的扩展能力,流量高峰时能否在短时间内完成扩容,更平稳地承接峰值流量,比如双11活动、明星离婚等热点事件。

这3个目标是需要通盘考虑的,因为它们互相关联、甚至也会相互影响。
比如说:考虑系统的扩展能力,你需要将服务设计成无状态的,这种集群设计保证了高扩展性,其实也间接提升了系统的性能和可用性。
再比如说:为了保证可用性,通常会对服务接口进行超时设置,以防大量线程阻塞在慢请求上造成系统雪崩,那超时时间设置成多少合理呢?一般,我们会参考依赖服务的性能表现进行设置。
具体目标
性能指标
性能指标通过性能指标可以度量目前存在的性能问题,也是高并发主要关注的指标,性能和流量方面常用的一些指标有
- QPS/TPS/HPS:QPS是每秒查询数,TPS是每秒事务数,HPS是每秒HTTP请求数。最常用的指标是QPS。
需要注意的是,并发数和QPS是不同的概念,并发数是指系统同时能处理的请求数量,反应了系统的负载能力。
-
响应时间:从请求发出到收到响应花费的时间,例如一个系统处理一个HTTP请求需要100ms,这个100ms就是系统的响应时间。
-
平均响应时间:最常用,但是缺陷很明显,对于慢请求不敏感。比如 1 万次请求,其中 9900 次是 1ms,100 次是 100ms,则平均响应时间为 1.99ms,虽然平均耗时仅增加了 0.99ms,但是 1%请求的响应时间已经增加了 100 倍。
-
TP90、TP99 等分位值:将响应时间按照从小到大排序,TP90 表示排在第 90 分位的响应时间, 分位值越大,对慢请求越敏感。

-
RPS(吞吐量):单位时间内处理的请求量,通常由QPS和并发数决定。
通常,设定性能目标时会兼顾吞吐量和响应时间,比如这样表述:在每秒 1 万次请求下,AVG 控制在 50ms 以下,TP99 控制在 100ms 以下。对于高并发系统,AVG 和 TP 分位值必须同时要考虑。另外,从用户体验角度来看,200 毫秒被认为是第一个分界点,用户感觉不到延迟,1 秒是第二个分界点,用户能感受到延迟,但是可以接受。
因此,对于一个健康的高并发系统,TP99 应该控制在 200 毫秒以内,TP999 或者 TP9999 应该控制在 1 秒以内。 -
PV:综合浏览量,即页面浏览量或者点击量,一个访客在24小时内访问的页面数量。
-
UV:独立访客 ,即一定时间范围内相同访客多次访问网站,只计算为一个独立的访客。
-
带宽: 计算带宽大小需要关注两个指标,峰值流量和页面的平均大小。
日网站带宽可以使用下面的公式来粗略计算:
日网站带宽=pv/统计时间(换算到秒)*平均页面大小(单位kB)*8
峰值一般是平均值的倍数;
QPS不等于并发连接数,QPS是每秒HTTP请求数量,并发连接数是系统同时处理的请求数量:
可用性指标
高可用性是指系统具有较高的无故障运行能力,可用性 = 平均故障时间 / 系统总运行时间,一般使用几个 9 来描述系统的可用性。
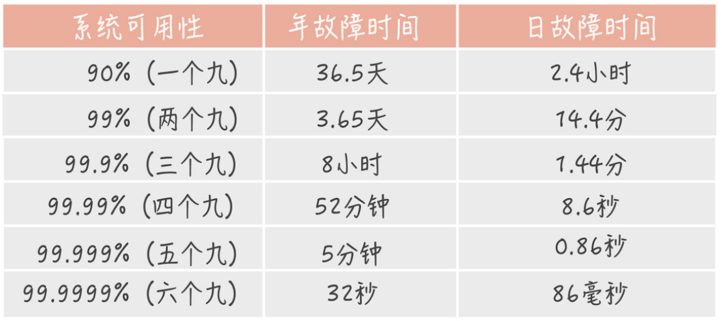
对于大多数系统。2个9是基本可用(如果达不到开发和运维可能就要被祭天了),3个9是较高可用,4个9是具有自动恢复能力的高可用。要想达到3个9和4个9很困难,可用性影响因素非常多,很难控制,需要过硬的技术、大量的设备资金投入,工程师要具备责任心,甚至还要点运气。
可扩展性指标
面对突发流量,不可能临时改造架构,最快的方式就是增加机器来线性提高系统的处理能力。
对于业务集群或者基础组件来说,扩展性 = 性能提升比例 / 机器增加比例,理想的扩展能力是:资源增加几倍,性能提升几倍。通常来说,扩展能力要维持在 70%以上。
但是从高并发系统的整体架构角度来看,扩展的目标不仅仅是把服务设计成无状态就行了,因为当流量增加 10 倍,业务服务可以快速扩容 10 倍,但是数据库可能就成为了新的瓶颈。
像 MySQL 这种有状态的存储服务通常是扩展的技术难点,如果架构上没提前做好规划(垂直和水平拆分),就会涉及到大量数据的迁移。
我们需要站在整体架构的角度,而不仅仅是业务服务器的角度来考虑系统的扩展性 。所以说,数据库、缓存、依赖的第三方、负载均衡、交换机带宽等等都是系统扩展时需要考虑的因素。我们要知 道系统并发到了某一个量级之后,哪一个因素会成为我们的瓶颈点,从而针对性地进行扩展。
高并发架构演进
谁不是生下来就是老司机,架构也不是架起来就支持高并发。我们来看一个经典的架构演进的例子——淘宝,真实诠释了“好的架构是进化来的,不是设计来的”。
以下是来自《淘宝技术这十年》描述的淘宝2003—2012年的架构演进。
个人网站
初代淘宝的团队人员只有十来个,而且面临千载难逢的商业机会,所以要求上线的时间越快越好(实际用了不到一个月),那么淘宝的这些牛人是怎么做到的呢?
——买一个。
初代淘宝买了这样一个架构的网站: LAMP(Linux+Apache+MySQL+PHP)。整个系统的架构如下:
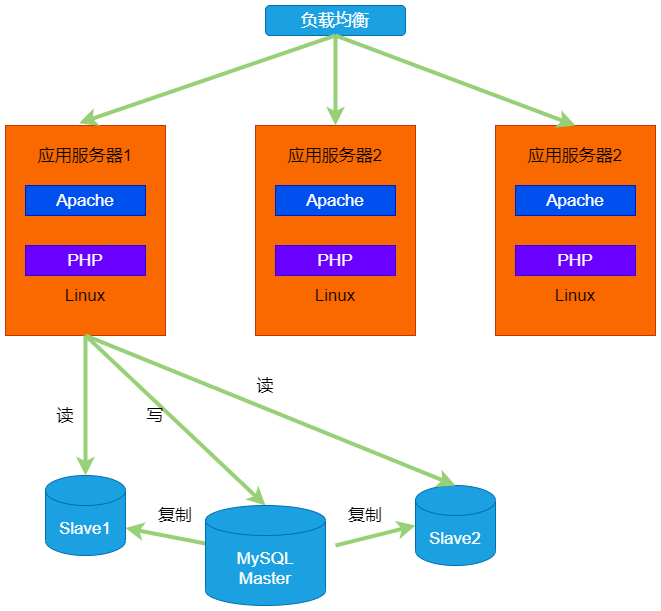
最后开发的网站是这样的:

由于商品搜索比较占用数据库资源,后来还引入了阿里巴巴的搜索引擎iSearch。
Oracle/支付宝/旺旺
淘宝飞速发展,流量和交易量迅速提升,给技术带来了新的问题——MySQL抗不住了。怎么办?要搞点事情吗?没有,淘宝买了Oracle数据库,当然这个也考虑到团队里有Oracle大牛的原因。
替换了数据库之后的架构:
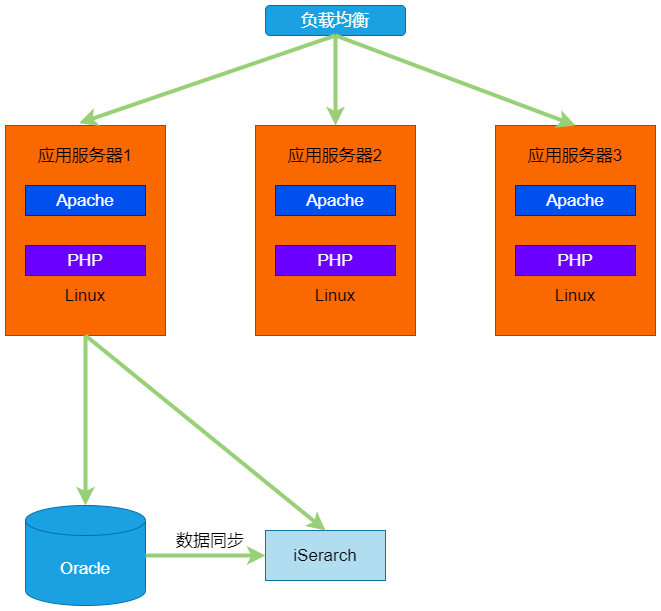
比较有意思的,当时由于买不起商用的连接池,所以用了一个开源的连接池代理服务SQLRelay,这个代理服务经常会死锁,怎么解决呢?人肉运维,工程师24小时待命,出现问题赶紧重启SQL Relay服务。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!
 客服
客服


