
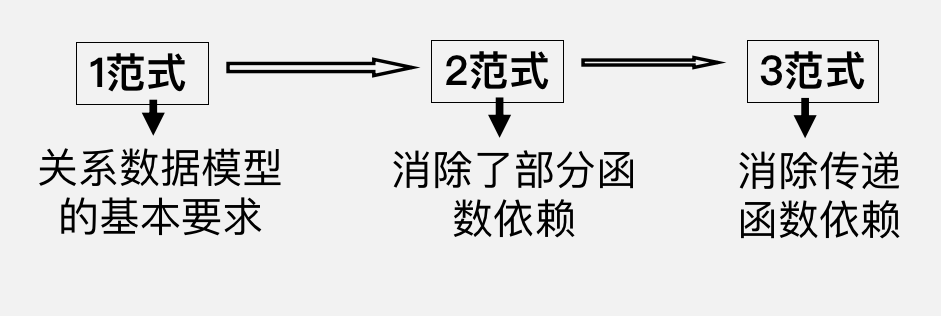
范式
范式理论是为了解决以上提到四种异常。
高级别范式的依赖于低级别的范式,1NF 是最低级别的范式。
1. 第一范式 (1NF)
属性不可分。
类似于成绩可以分为语文成绩,数学成绩,英语成绩等等,那么就说成绩这个属性是可分的,因此不能称之为第一范式1NF。
2. 第二范式 (2NF)
每个非主属性完全函数依赖于键码。
可以通过分解来满足。
分解前
| Sno | Sname | Sdept | Mname | Cname | Grade |
|---|---|---|---|---|---|
| 1 | 学生 - 1 | 学院 - 1 | 院长 - 1 | 课程 - 1 | 90 |
| 2 | 学生 - 2 | 学院 - 2 | 院长 - 2 | 课程 - 2 | 80 |
| 2 | 学生 - 2 | 学院 - 2 | 院长 - 2 | 课程 - 1 | 100 |
| 3 | 学生 - 3 | 学院 - 2 | 院长 - 2 | 课程 - 2 | 95 |
以上学生课程关系中,{Sno, Cname} 为键码,有如下函数依赖:
- Sno -> Sname, Sdept
- Sdept -> Mname
- Sno, Cname-> Grade
Grade 完全函数依赖于键码,它没有任何冗余数据,每个学生的每门课都有特定的成绩。
Sname, Sdept 和 Mname 都部分依赖于键码,当一个学生选修了多门课时,这些数据就会出现多次,造成大量冗余数据。
分解后
关系 - 1
| Sno | Sname | Sdept | Mname |
|---|---|---|---|
| 1 | 学生 - 1 | 学院 - 1 | 院长 - 1 |
| 2 | 学生 - 2 | 学院 - 2 | 院长 - 2 |
| 3 | 学生 - 3 | 学院 - 2 | 院长 - 2 |
有以下函数依赖:
- Sno -> Sname, Sdept
- Sdept -> Mname
关系 - 2
| Sno | Cname | Grade |
|---|---|---|
| 1 | 课程 - 1 | 90 |
| 2 | 课程 - 2 | 80 |
| 2 | 课程 - 1 | 100 |
| 3 | 课程 - 2 | 95 |
有以下函数依赖:
- Sno, Cname -> Grade
3. 第三范式 (3NF)
非主属性不传递函数依赖于键码。
上面的 关系 - 1 中存在以下传递函数依赖:
- Sno -> Sdept -> Mname
可以进行以下分解:
关系 - 11
| Sno | Sname | Sdept |
|---|---|---|
| 1 | 学生 - 1 | 学院 - 1 |
| 2 | 学生 - 2 | 学院 - 2 |
| 3 | 学生 - 3 | 学院 - 2 |
关系 - 12
| Sdept | Mname |
|---|---|
| 学院 - 1 | 院长 - 1 |
| 学院 - 2 | 院长 - 2 |
规范化理论是数据库逻辑设计的工具
使用范式设计数据库的目的是为了消除插入,删除异常,修改复杂以及数据冗余的问题。
4. BC范式 (BCNF)
若有(Rin BCNF)
- 所有非主属性对每一个码都是完全函数依赖
- 所有的主属性对每一个不包含它的码,也是完全函数依赖
- 没有任何属性完全函数依赖于非码的任何一组属性 -> 除了码之外没有其他的决定因素
关系R属于BCNF是R属于3NF的充分不必要条件。

逻辑蕴含
对于满足一组函数依赖 F 的关系模式 R<U,F> 其任何一个关系 r,若函数依赖 X→Y 都成立,(即r 中任意两元组 t,s,若 t[X]=s[X],则 t[Y]=s[Y]),则称 F 逻辑蕴含 X→Y.
关系模式的推理规则
对于关系模式 (R<U,F>)有如下规律
- 自反律:若(Y⊆X⊆U),则 (X→Y) 为(F)所蕴含;
- 增光律:若(X→Y) 为$ F(所蕴含,且) Z⊆U(,则) X∪Z→Y∪Z$ 为 (F) 所蕴含.
- 传递律:若(X→Y) 及$ Y→Z$ 为 (F) 所蕴含,则(X→Z) 为 (F) 所蕴含.
由上面三条规律可以拓展出更多的规律
- 合并规则:由 (X→Y),(X→Z),有(X →Y U Z)
- 伪传递规则:由(X →Y),(W ∪ Y→Z),有(X ∪ W →Z)
- 分解规则:由(X→Y) 及$ Z subseteq Y(,有)X →Z$
函数闭包
在关系模式 (R<U,F>)中为$ F (所蕴涵的函数依赖的全体叫做)F$ 的闭包,记为 (F^+).
闭包中的每一个函数依赖都可以从F根据Armstrong公理推导出来。但可惜的是,其闭包是一个NP完全问题。
属性集 X 关于函数依赖集 F 的闭包(X_F^+):
求闭包的方法
求属性集 X 关于 U 上的函数依赖集F的闭包$ X_F^+$
输入: (X,F);
输出:$ X_F^+ $
- 令(X^i=X,i=0)
- 求 B,这里 $B={A|(∃V,∃W,V→W∈F∧V⊆X^i∧A∈W)} $;
- $X{i+1}=B⋃Xi $;
- 判断是否 $ X{i+1}=Xi $
- 若相等或 $ X^i=U(,则) X^i (就是) X_F^+$, 算法终止;
- 若否,则$ i=i+1$,返回第(2)步。
对于该算法, 令(a_i=|X^i|,{a_i})形成一个步长大于1的严格递增的序列,序列的上界是 (| U|),因此该算法最多 (| U | - |X|) 次循环就会终止。
极小函数依赖集
定义

极小化过程
- 逐一检查 (F) 中各函数依赖(FD_i):(X→Y),若(Y =A_1 A_2 … A_k,k >2), 则用$ {X→A_j |j=1,2,…,k} $来取代 (X →Y);
- 逐一检查(F) 中各函数依赖(FD_i):(X→A),令 (G =F -{ X→A }),若(Ain X_{G^+}), 则从F 中去掉此函数依赖。(因为 (F)与$G (等价的充分必要 条件是)Ain X_G^+$ )
- 逐一取出F 中各函数依赖(FD_i):(X→A),设(X = B_1B_2…B_m) ,逐一考查(B_i (i=l,2,…,m)),若(A in(X - B_i )_{F^+}) ,则以$ X-B_i$ 取 代$ X(,(因为 F与)F-{X-A}⋃{Z-A}(等价的充要条件是)Ain Z _F^+$ ,其中$Z = X- B_i $)
模式的分解
无损连接性
分解之后可以用自然连接恢复原本的模式。
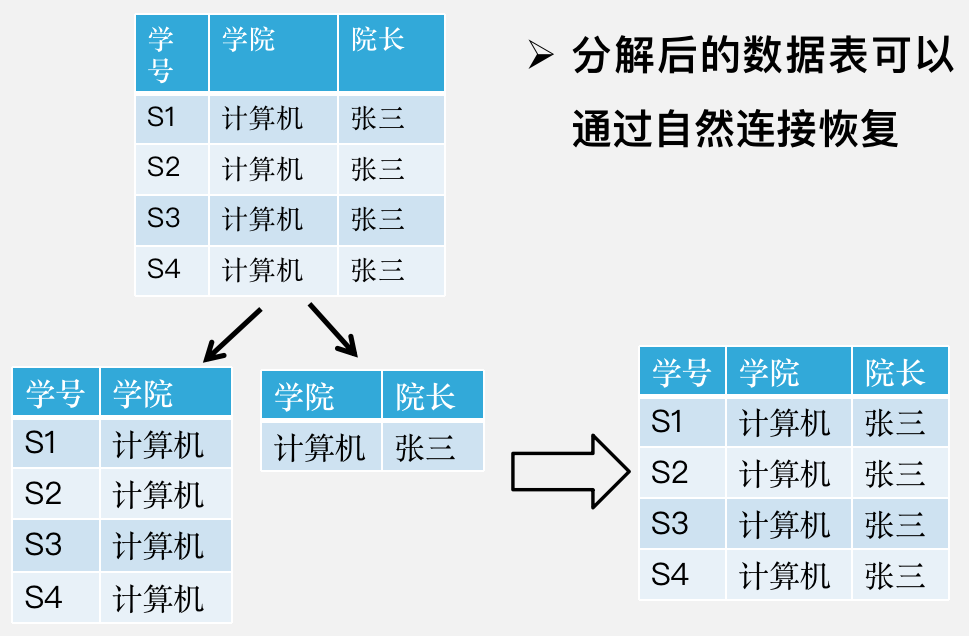
无损连接的判定

例如上图中,学院决定院长这个函数关系是存在的,满足了定理中的一个条件,所以该分解就是无损连接的分解。
保持函数依赖的分解
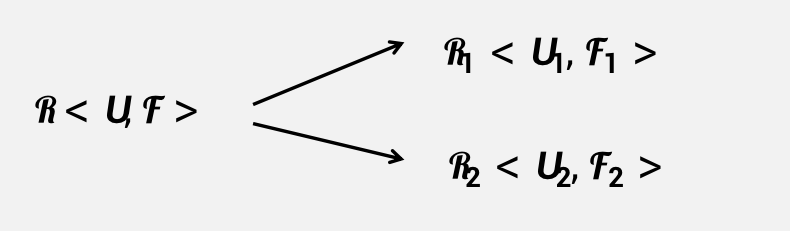
需要满足的条件
- (U=U_1cup U_2)
- (F^+=(F_1cup F_2)^+)
充分条件:如果F上的每一个函数依赖都在其分解后的某一个关系上成立,则这个分解是保持依赖的。
例子
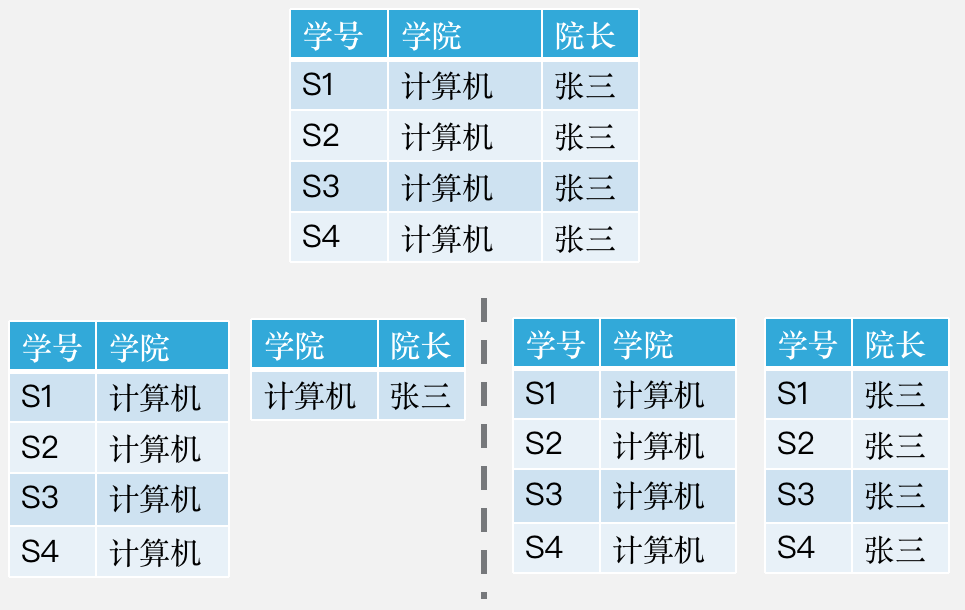
关于模式分解的几个重要事实
- 若分解要求保持函数依赖,总可以达到3NF,不一定能到BCNF;
- 若分解既保持函数依赖,又具有无损连接,可以到3NF,不一定到BCNF;
- 若分解只要求具有无损连接,一定可以达到4NF.

ER 图
Entity-Relationship,有三个组成部分:实体、属性、联系。
用来进行关系型数据库系统的概念设计。
E-R有意思的一点在于其将实体之间的关系也实例化了,同时关系也能拥有属性。
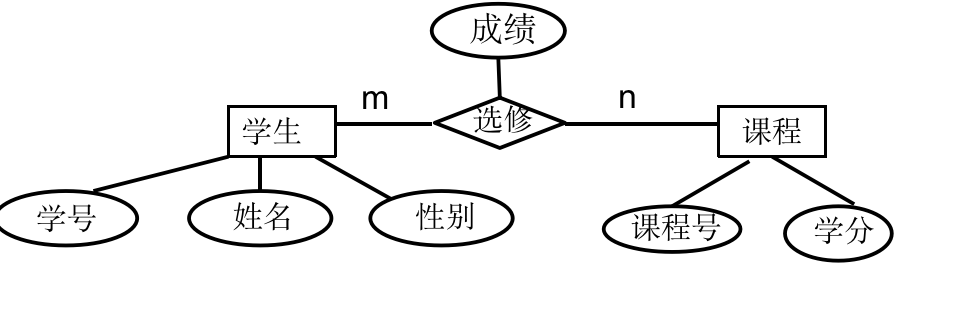
这里的选修关系就存在成绩属性。但也可以看成关系链接的实体所定义的属性是成绩。
实体的三种联系
包含一对一,一对多,多对多三种。
- 如果 A 到 B 是一对多关系,那么画个带箭头的线段指向 B;
- 如果是一对一,画两个带箭头的线段;
- 如果是多对多,画两个不带箭头的线段。
下图的 Course 和 Student 是一对多的关系。

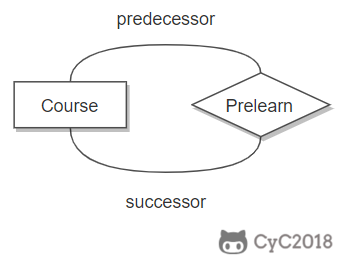
表示出现多次的关系
一个实体在联系出现几次,就要用几条线连接。
下图表示一个课程的先修关系,先修关系出现两个 Course 实体,第一个是先修课程,后一个是后修课程,因此需要用两条线来表示这种关系。
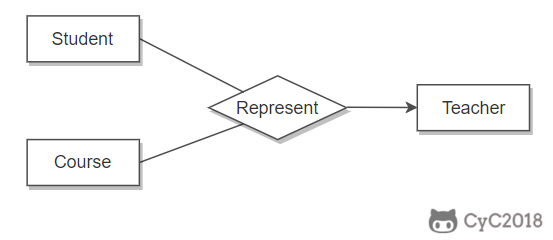
联系的多向性
虽然老师可以开设多门课,并且可以教授多名学生,但是对于特定的学生和课程,只有一个老师教授,这就构成了一个三元联系。
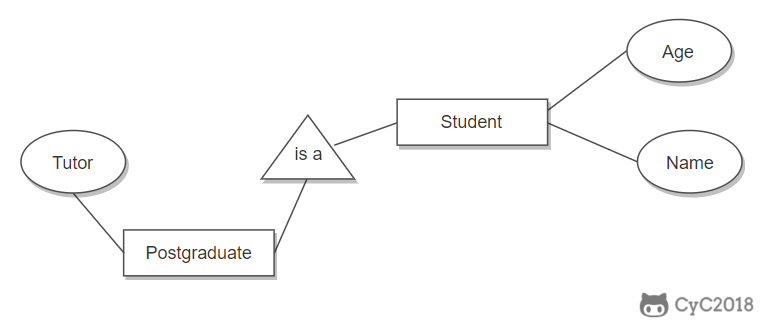
表示子类
用一个三角形和两条线来连接类和子类,与子类有关的属性和联系都连到子类上,而与父类和子类都有关的连到父类上。
实体与属性的划分原则:现实世界的事物能作为属性对待的尽量作为属性对待。
- 作为属性,不能再具有需要描述的性质
- 属性不能与其他实体有联系
ER图的集成
- 合并,解决各个分ER图之间的冲突,将分E-R图合并起来生成初步E-R图
- 修改和重构。消除不必要的冗余,生成基本E-R图
在合并E-R图的时候会遇到三种冲突:
- 属性冲突
- 命名冲突
- 结构冲突
数据库设计
数据库设计分为六个阶段
- 需求分析阶段
- 概念设计阶段
- 逻辑结构设计阶段
- 物理结构设计
- 数据库实施
- 数据库运行和维护
需求分析
准确了解和分析用户需求,包括数据处理,需求分析是整个设计过程的基础,是最困难和最耗费时间的一步。
数据字典
数据字典是进行详细的数据收集和数据分析所获得的主要成果,它是关于数据库中数据的描述,即元数据,而不是数据本身。数据字典是在需求分析阶段建立,在数据库设计的过程中不断的修改,充实,完善的。
数据字典多包括这么几个部分:
- 数据项:是数据的最小组成单位,若干个数据项可以组成一个数据结构。
- 数据结构:反映了数据之间的组合关系,一个数据结构可以由若干个数据项组成,也可以由若干个数据结构组成。
- 数据流:是数据结构在系统内的传输路径。
- 数据存储:是数据结构停留和保存的地方,也是数据的来源和去向。
- 处理过程:一般用判定表或者判定树来描述。
数据字典通过对数据项和数据结构的定义来描述数据流,数据存储的逻辑内容。
概念结构设计阶段
概念结构设计是整个数据库设计的关键,它通过对用户需求进行综合,归纳和抽象,形成一个独立于具体数据库管理系统之外的概念模型。
包括[ER图](#ER 图)的设计。
逻辑结构设计阶段
将概念结构模型转换为某个数据库管理系统 DBMS 支持的数据模型,并对其进行优化。
物理结构设计阶段
是为逻辑数据模型选取一个最适合应用环境的物理结构,包括存储结构和存储方法。
数据库实施阶段
在数据库实施阶段,设计人员运用数据库管理系统提供的数据库语言及其宿主语言,根据逻辑设计和物理结构设计的结果建立数据库,编写调试应用程序,组织数据入库,并进行试运行。
数据库运行和维护阶段
经过试运行之后即可投入正常使用。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


