
查询语句
1.基础查询:
SELECT * FROM 表
解析:此语句会将表中所有的字段查询出来,SQL执行的顺序:FROM 表 (找到表)=>SELECT * (查询所有字段*代表所有字段)
SELECT ID,NAME FROM 表
解析:此语句会将表中所有的字段查询出来,SQL执行的顺序:FROM 表 (找到表)=>SELECT ID,NAME (查询 ID和NAME字段)
2.带条件的查询
SELECT * FROM 表 WHERE ID=1
解析:此语句找到表中ID字段等于1的数据
SELECT * FROM 表 WHERE ID>1
解析:此语句找到表中ID字段大于1的数据
SELECT * FROM 表 WHERE ID<1
解析:此语句找到表中ID字段小于1的数据
SELECT * FROM 表 WHERE ID IN (1,2,3)
解析:此语句找到表中ID字段等于1或者2或者3的数据
SELECT * FROM 表 WHERE ID NOT IN (1,2,3)
解析:此语句找到表中ID字段不等于1或者2或者3的数据
SELECT * FROM 表 WHERE NAME LIKE '%内容%'
解析:此语句找到表中NAME字段出现内容数据,这个%代表任意内容,放在前面代表前面可以出现或者不出现任意内容,比如:
NAME LIKE '%内容%',NAME中的数据是“这个内容是123” 他找到了内容就匹配了,
如果是NAME LIKE '内容%' 那就只能找内容开头的比如:NAME中的数据是“内容是123”,他就匹配了,
如果是NAME LIKE '%内容' 那就只能找内容结尾的比如:NAME中的数据是“这个内容”,他就匹配了
SELECT * FROM 表 WHERE ID BETWEEN 1 AND 10
解析:此语句找到表中ID字段1--10的内容,BETWEEN 是范围 1到10范围的数据 一般用于数据取范围
3.AND和OR
在我们查询的过程中有时候不仅仅只有一个调整 那么上述的条件都可以通过AND或者OR组合起来,如:
SELECT * FROM 表 WHERE NAME LIKE '%内容%' AND ID BETWEEN 1 AND 10
解析:AND 是且的意思 代表此查询既要满足NAME LIKE '%内容%' 又要满足ID BETWEEN 1 AND 10
SELECT * FROM 表 WHERE NAME LIKE '%内容%' OR ID BETWEEN 1 AND 10
解析:OR是或的意思 代表此查询只要满足NAME LIKE '%内容%' 或者ID BETWEEN 1 AND 10 其中一个就行
SELECT * FROM 表 WHERE (NAME LIKE '%内容%' OR NAME LIKE '%123%' ) AND ID BETWEEN 1 AND 10
解析:AND 和OR也可以搭配使用,此语句代表除了满足了ID BETWEEN 1 AND 10 还要满足 NAME LIKE '%内容%' 和 NAME LIKE '%123%' 其中一个
4.多表联查
多表联查分为三类:内连接(inner join )、左连接(left join)、右连接(right join )
4.1内连接(inner join 、join )
SELECT * FROM 表A as a inner join 表B as b ON a.连接字段=b.连接字段
解析:inner join 和ON 是内连接的关键词,内连接是取得表A和表B能通过连接字段关联起来的数据。
连接字段可以有多个,用and或者or 关联 如:ON a.连接字段1=b.连接字段1 and a.连接字段2=b.连接字段2 or a.连接字段3=b.连接字段3
PS: as 是给表A,表B取个别名的方便ON关键词后面指定那张表的连接字段,也可以不用as,直接表A.连接字段,如:
SELECT * FROM 表A inner join 表B ON 表A.连接字段=表B.连接字段
示例:学生表student
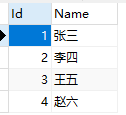
课程表Course
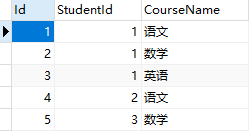
select* from Student s inner join Course c ON s.Id=c.StudentId

通过student表的id和Course表的StudentId 取到了能关联的张三李四王五的记录、赵六关联不上所以没有记录
4.2左连接(left join)
SELECT * FROM 表A as a left join 表B as b ON a.连接字段=b.连接字段
解析:left join和ON 是左连接的关键词,左连接是以左边表A为主表,表B为子表,先查询出表A中的数据,然后关联表B如果关联上了就将数据查询出来,如果表B中没有关联上数据则对应字段为null。
示例:学生表student
课程表Course
select* from Student s left join Course c ON s.Id=c.StudentId
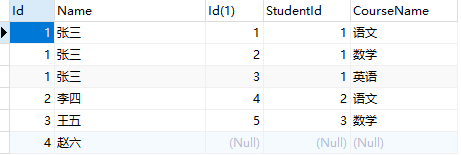
通过student表的id和Course表的StudentId 取到了能关联的张三李四王五的记录、赵六关联不上所以Course表对应的记录为null
4.3右连接(right join)
SELECT * FROM 表A as a right join 表B as b ON a.连接字段=b.连接字段
解析:right join和ON 是右连接的关键词,右连接是以右边表B为主表,表A为子表,先查询出表B中的数据,然后关联表A如果关联上了就将数据查询出来,如果表A中没有关联上数据则对应字段为null。
示例:学生表student
课程表Course
select* from Student s right join Course c ON s.Id=c.StudentId

这里之所以数据和内连接(inner join )数据一致,是因为右边表B所有的数据都能关联到左边,如果将student表放置在右边(Course c right join Student s)则和左连接一致
4.4三个表以上连接查询
SELECT * FROM 表A as a right join 表B as b ON a.连接字段=b.连接字段 INNER JOIN 表C as c ON c.连接字段=a.连接字段
4.5连接查询如果待条件语句:
SELECT * FROM 表A as a right join 表B as b ON a.连接字段=b.连接字段 WHERE a.条件字段=条件
5.排序(order by)
5.1单字段排序
SELECT * FROM 表 order by id asc SELECT * FROM 表 order by id
解析:上述2个语法效果一致,order by 和asc 是排序的关键字,代表着以ID字段正序(数字从小到大,a-z)排序
PS:第二条是简写语法,默认排序是正序所以可以不写asc
SELECT * FROM 表 order by id asc
解析:order by 和desc 是排序的关键字,代表着以ID字段倒序(数字从大到小,z-a)排序
5.2多字段排序
SELECT * FROM 表 order by id asc,Name desc SELECT * FROM 表 order by id,Name desc
解析:上述2个语法效果一致,首先我们以ID 进行正序排列,如果出现ID 相同的情况如:三个ID 为1,那么这三条数据将以Name 倒叙排列:
示例:课程表Course
select * from Course order by StudentId desc,CourseName
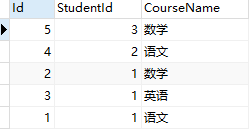
先以studentId 字段倒叙排列,如果studentId相同,则以CourseName字段正序排列
6.分组(group by)
group_by的意思是根据by对数据按照对应字段进行分组,所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理。
select 查询字段 from 表名 group by 分组字段
解析:简单点来说就是以 “分组字段” 为依据进行聚合操作,比如:很多门课和很多个学生,你如果想取得每个学生上了多少门客,那么我就以每个学生分组 ,来求课程数
示例:课程表Course
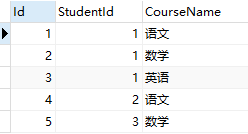
select StudentId,Count(*)CourseNumber from Course GROUP BY StudentId
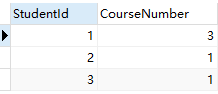
解析:首先我以学生ID 进行的分组,那么所有学生ID相同的数据都是一个组,然后我在组内进行取行数【count(*)】,然后的给个别名CourseNumber
这里要注意使用使用了group by 就不能用*,只能使用group by的字段,因为select的语句执行的先后顺序是先group by 再select ,这个时候其实数据已经分组了,所以你的“查询字段”里面只能出现【分组字段】和【分组聚合函数】
select 字段 from 表名 where 过滤条件 group by 字段 having 过滤条件
解析:having是分组之后再进行条件筛选的关键词,和where不同的是 where条件在分组之前执行和having条件在分组之后执行
7.常用聚合函数介绍
7.1求和 sum()
select sum(求和字段) from 表名 where 条件 select 分组字段,sum(求和字段) from 表名 where 条件 group by 分组字段
7.2平均值 avg()
select avg(求平均值字段) from 表名 where 条件 select 分组字段,avg(求平均值字段) from 表名 where 条件 group by 分组字段
7.3个数统计 count()
select count( ) from 表名 --包括空值 select count(*) from 表名 --不包括空值 select 分组字段,count(*) from 表名 where 条件 group by 分组字段
7.4最大值 max()
select max(取最大值字段) from 表名 select 分组字段,max(取最大值字段) from 表名 where 条件 group by 分组字段
7.5最小值min()
select min(取最小值字段) from 表名 select 分组字段,min(取最小值字段) from 表名 where 条件 group by 分组字段
8.查询去重
distinct去重
select DISTINCT * from 表
解析:distinct去重很简单只用在查询字段前面加入distinct关键字就行,但此做法有一个问题,就是必须要所有的查询字段一模一样才能去重,如果其中有一个字段不重复就无法去重
group by 去重
select 查询字段 from 表 where id in(select max(id) from 表 group by 去重分组字段)
解析:首先以要去重的字段分组 取得组内最大的id 然后根据id 查询的对应的信息就好,此方法需要有唯一字段,如:主键Id
没有唯一键group by 去重
select identity(int,1,1) as id,* into newtable(临时表) from 表 select * from newtable where id in (select max(id) from newtable group by 去重分组字段)
drop table newtable
解析:先将表into 写入到临时表newtable并加入自增Id,后续操作和group by 去重一致,然后删除(drop table)临时表
9.高级开窗函数row_number() over()和row_number() over(partition by)【mysql5.7及以下不支持,mysql8.0及sqlserver支持】
平常一般我们主键Id来进行排序,但是如果删除了数据,那么会导致Id不连贯,如果我们进行分页取数据的话那或导致数据出现少的情况,通过使用row_number() over()你将得到一个连续的列
select row_number() over(order by a.id)rowid,* from Student a inner join Course b ON a.Id=b.StudentId
解析:row_number() over(order by a.id) 这个是此语法的关键词,以表a(Student)的id正序构建以个新的连续唯一(每条自增+1)的字段,别名为rowid
select row_number() over(partition by b.StudentId order by b.id)rowid,* from Student a inner join Course b ON a.Id=b.StudentId
解析:与上面不同不同的是此语句加入了partition by 这代表组内排序,以b.StudentId分组,如果studentId 相同则 以b.id 正序排序【连续唯一(每条自增+1)】,如果组内只有一条则就是1
10.WITH AS 子查询部分【mysql5.7及以下不支持,mysql8.0及sqlserver支持】
子查询部分的好处是部分查询,不如有三个表连接在一条语句种出现多次
单个子查询部分
with a as (select * from Student a inner join Course b ON a.Id=b.StudentId )select * from a
解析:这样在此语句种每次查询a都是查询了student和course表的联查集合
多个查询部分语法
with a as (select * from Student), b as (select * from Course) select * from a inner join b on a.Id=b.StudentId
解析:这个多个查询部分语法的写法,原理和单个查询部分一致
11.UNION 和UNION ALL 数据连接查询
UNION 和UNION ALL 都表示将2个数据集拼接(说白了就是将后面查询的结果拼接到前面查询结果的尾部),但union是去掉重复的和distinct一样union all 是不去重的。
PS:2个查询结果集的字段名称和每个字段的类型要保持一致 不要一个int类型一个varchar类型
select `Id`,`Name` from Student union select `Id`,CourseName `Name` from Course select `Id`,`Name` from Student union all select `Id`,CourseName `Name` from Course
新增
1.单条参数新增
insert into 表(字段1,字段2)value (字段1值,'字段2值')
解析:insert into 和 value 是此新增语法的关键字 然后字段和值一一对应
注意字符串类型字段的值使用单引号括起来
2.单条参数新增
insert into 表(字段1,字段2)values (字段1值,'字段2值'), (字段1值,'字段2值'), (字段1值,'字段2值')
解析:insert into 和 values 是此新增语法的关键字 与单个新增不一样的是values 多了个复数s 代表能写入多个值
3.查表写入
insert into 表a(字段1,字段2)select 字段1,字段2 表b where id=1
解析:此语法会将select 语句查询的结果写入到表b对应的字段中,要注意此语句的字段顺序和查询结果字段顺序需要保持一致并且类型要保持一致,where和查询的where一致用于筛选数据
修改
1.单表修改
update 表 set 字段1=字段1的值,字段2=字段2的值 update 表 set 字段1=字段1的值,字段2=字段2的值 where id=1 update 表 set 字段1=字段2,字段2=字段2的值 where id=1
解析:update和set 是此语法的关键字,where和查询的where一致用于筛选数据,多个字段更新用逗号(,)隔开,也可以将另一字段的值更新到此字段直接写字段名就行。
2.多表修改
update 表1 set 字段1=b.字段2,b.字段2=a.字段2 from 表1 a,表2 b where a.id=b.id and a.id=1 update 表1 set 字段1=(select 字段1对应字段 from 表2 b where 表1.id=b.id ) where a.id=1
解析:update和set from 是此语法的关键字,多表语法在于多个表逗号分隔( 表1 a,表2 b)通过得到where a.id=b.id 条件进行关联表1和表2,where 条件后面也可以带其他条件
PS:语法有好几种每个数据库支持的语法不一样请大家具体尝试
删除
1.删除表中数据
delete table 表 delete table 表 where id=1
解析:delete table是此语法的关键词,代表删除表中的数据,where和查询的where一致用于筛选数据,特别要注意:此语法一般要带上where条件,如果不带将删除整个表的数据
2.删除表
drop table 表
解析:drop table 是关键词,此语法将从数据库中删除整个表的结构,也就是说无法在写入或者更新删除数据了,此表将不在数据库中存在了。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!
 客服
客服


