
01 AI"卷" 进实时互动
2021 年,元宇宙概念席卷全球,国内各大厂加速赛道布局,通过元宇宙为不同的应用场景的相关内容生态进行赋能。针对 “身份”、“沉浸感”、“低延迟”、“随时随地” 这四个元宇宙核心基础,ZEGO 即构科技基于互动智能的业务逻辑,提出并落地了 ZegoAvatar 解决方案,将 AI 视觉技术应用至虚拟形象,完成了业务和技术的无缝衔接。

图 1:Avatar 产品 AI 能力矩阵
ZegoAvatar 基础能力包括:面部表情随动、语音驱动表情、AI 人脸特征识别(AI 捏脸)、骨骼捏脸等,涉及的 AI 技术点包括人脸检测、人脸跟踪、人脸关键点检测、头部姿态检测、3D 人脸重建、AI 特征识别等。
本文重点针对 ZegoAvatar 中面部表情随动这一技术点进行解读。
02 ZegoAvatar 面部表情随动效果展示
在技术分享前首先让我们通过一组具体的数字和视频来看下 ZegoAvatar 的面部表情随动效果,我们分别在配置从低到高四种不同安卓设备上进行实际推理开销测试,取 1000 次推理结果求平均:
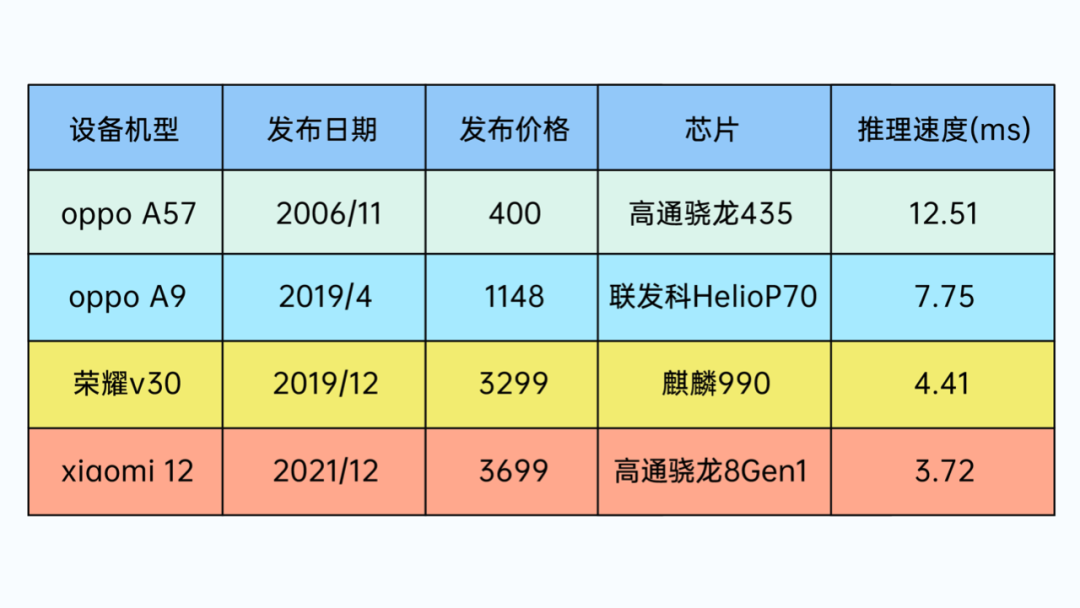
图 2:测试数据
从上述的数据中可以看到,ZegoAvatar 在不同机型上均以极低的延迟实现了实时推理的效果,在保证表情精准稳定的同时,为用户带来了流畅极致的使用体验。可以看下下方的面部表情随动效果:
ZegoAvatar 面部表情随动效果展示
03 面部表情随动技术方案解析
面部表情捕捉(Facial Expression Capture)技术被广泛应用于电影、游戏、动漫制作等领域,而目前的面部动作捕捉依托于相机或激光扫描仪将人脸转换为一系列参数数据,然后用于生成计算机图形、电影、游戏或实时化身的计算机动画。
与捕捉由关节点构成、较为稳定的人体动作相比,面部表情更为细微复杂,因此对数据精度的要求也更高。现在主流的 3D 面部表情捕捉主要有基于相机阵列和基于结构光两种方法,存在拍摄难度大,设备成本高的问题。

图 3:表情捕捉示意图
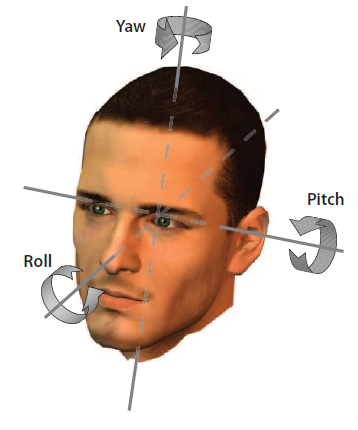
图 4:欧拉角示意图
ZegoAvatar 技术方案中的移动端面部表情随动是指通过移动端摄像头进行人脸检测以及跟踪,通过人脸位置、关键点信息定位出人脸在屏幕上的位置,并实时输出包含面部、舌头、眼球在内的 52 种基础面部表情维度的线性组合以及头部姿态的三个欧拉角,最后导入虚拟形象进行实时渲染驱动。
目前 ZegoAvatar 面部表情随动在不同性能的硬件设备上均实现了低延迟的落地效果,通过实时的虚实交互,为用户带来沉浸式的体验。本文将向大家详细解读 ZegoAvatar 的面部表情随动的算法整体架构以及如何在落地过程中做到面部表情随动效果的精确与自然。
ZegoAvatar 的移动端面部表情随动的技术方案分为模型训练和部署推理两部分。
在训练过程,我们设计了一个轻量化的全卷积神经网络,包括网络骨干(Backbone)和三个不同的任务分支(如图 5)。其中 Backbone 是由标准卷积 + MobileNetV2 Block + MobileViT Block 组成(如图 6),多个输出分支为:3D 面部特征点定位、面部表情识别、头部欧拉角姿态估计,其中不同的分支负责不同的任务。我们通过多任务学习的思想和迁移学习的技巧,给模型送入人脸特征和表情以及欧拉角标签,输出稳定的相关的映射关系。
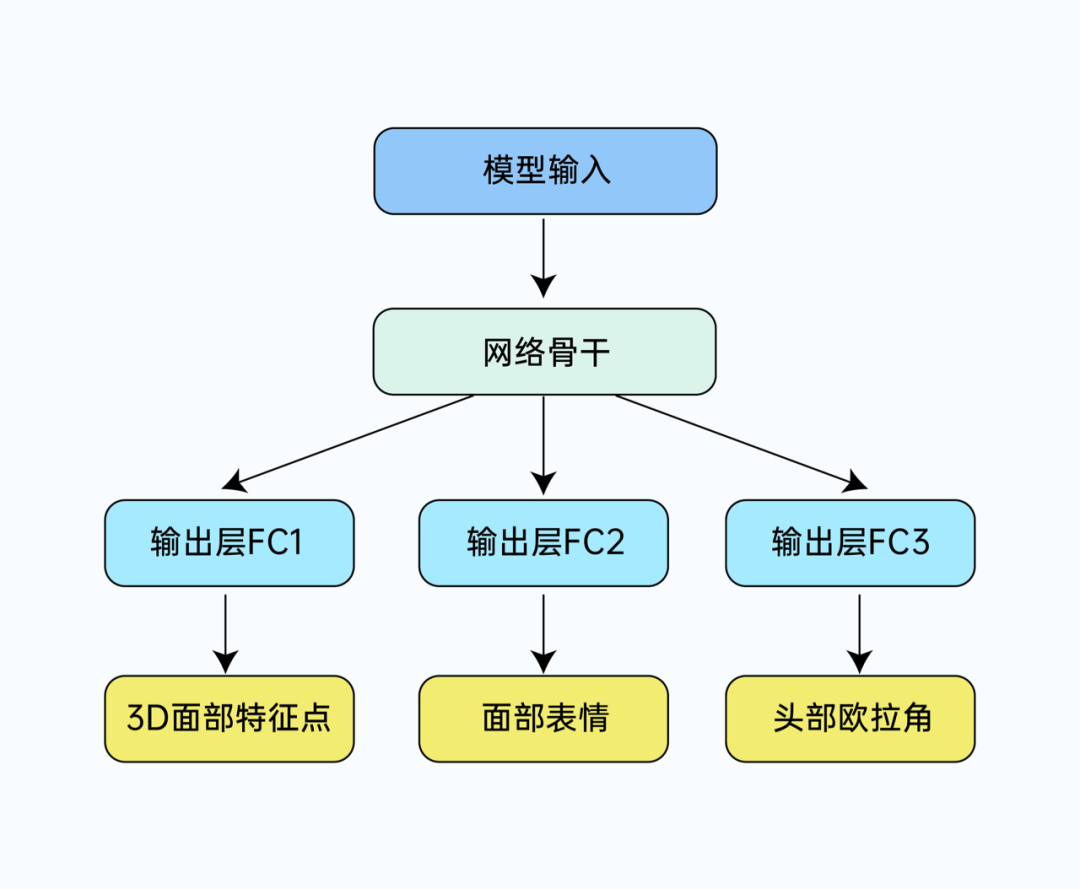
图 5:网络结构示意图

图 6:网络骨干(Backbone)示意图

图 7:训练和推理流程示意图
1、训练模块
根据数据采集模块得到表情数据,并通过数据矫正和增强后训练得到 AI 表情模型,具体分为以下几个部分:
a、 数据采集:针对业务需求,我们开发了一套可用于捕捉人脸和动作的数据采集软件,用于 获取表情和欧拉角以及 3D 特征点位置数据;
b、模型训练:基于多任务学习和迁移学习的思想,我们尝试了多种轻量级的网络结构和训练策略,设计不同的任务分支如特征点定位和头部姿态估计以及面部表情检测,利用任务之间的相关性辅助目标任务学习。
c、数据增强:针对落地场景,设计了定制化的数据增强流程,丰富了训练数据的模式;
d、数据矫正:对采集的图片依次进行人脸检测,面部特征点对齐,通过仿射变换得到矫正后的图片;
对模型进行训练,模型分为三个分支,损失函数组成如下:

2、推理模块
推理模块根据输入数据进行推理,具体分为以下几个部分:
a、数据输入和矫正:用户使用时解析输入视频流,对图片中的人脸进行检测、跟踪以及面部特征点定位,然后计算出人脸位置与标准人脸之间的仿射矩阵,从而通过仿射变换得到矫正后的图像;
b、模型推理:对训练好的 AI 模型,进行剪枝和量化,在 FP16 半精度下,在移动端进行推理加速部署,最后将矫正后的图像送入模型,推理得到表情向量和欧拉角向量;
c、表情驱动和渲染:将表情向量和欧拉角向量送入驱动渲染模块解析,实时驱动虚拟人物形象。
04 “精确而自然” 的效果难点攻克
本技术旨在解决互动智能领域移动端虚拟人物表情实时驱动问题,在研发过程中需要解决以下问题:
-
移动端推理的实时性
-
面部表情和头部姿态的稳定性
-
不同用户在不同使用场景的鲁棒性
-
各个表情的协调性
这四个维度层层递进,而如何做到同时兼顾,是贯穿整个项目周期的重难点。
首先,受限于移动端的计算资源,不同设备的用户要正常体验,必须要做到各种机型上的低延迟,因此落地需要做到极致的轻量化,这对模型设计和部署有较高要求。
其次,实际体验过程中,用户的使用方式、用户场景光照、用户镜头脏污或遮挡都会影响模型的表现,如何在这些因素的综合作用下,让模型又快又稳的输出面部表情和头部姿态,是 ZegoAvatar 走向商业化不可回避的难题。
最后,考虑到不同的表情之间既有独立性又互相影响,如何让虚拟形象的表情更加拟人化,让用户的使用更有沉浸感,既是一个有挑战性的技术挑战,也是一个有价值的业务问题。
基于以上想法,我们设计了以下技术方案:
1、推理的实时性
一方面设计模型时遵循轻量化的原则,比如使用深度可分离卷积(Depthwise separable convolution)以及更少的卷积层数和通道数,可以减少模型的参数量,从而降低推理的计算开销。
这里补充一下一般的卷积和深度可分离卷积的示意图,并对计算量优化进行简单分析:

图 8
深度可分离卷积将一般的卷积过程分为了 depthwise convolution(逐深度卷积)和 pointwise convolution(逐点卷积),略牺牲精度的情况下,计算量大幅下降,速度更快,模型更小。

由此可见,深度可分离卷积可以显著减少一般卷积的计算量。
另一方面落地时,我们基于移动端推理引擎进行模型转换和部署,主要分为算子转换和推理优化两个部分。
a、算子转换:主要通过算子融合、算子替代、模型压缩、布局调整等方式对模型中的图进行基本的优化操作;
b、优化推理:主要进行算子级的优化包括:卷积和反卷积中应用 Winograd 算法、在矩阵乘法中应用 Strassen 算法、低精度计算、手写汇编、多线程优化、内存复用等。
此外我们通过分析模型在不同网络层的的计算量分布,对模型存在计算瓶颈的卷积层进一步剪枝,在 FP16 半浮点数精度下,进行模型转换,在保证模型表现的同时,显著的降低了推理开销,并减少了模型的尺寸。
2、模型精确性和鲁棒性
首先是数据采集阶段,基于 ZEGO 自身业务,自主开发了一套数据采集软件,并通过脚本对每一批数据进行可视化检查,确保原始数据的正确性。
在模型训练阶段,尝试了多种模型结构和训练策略,包括不同的输入形式和分支组成。最后采用 3D 面部特征点分支和面部表情分支与头部欧拉角分支结合的方式,利用多任务学习思想和迁移学习的训练技巧,通过特征点信息辅助表情和欧拉角输出,得到精确的模型表现。
在最后落地时,由于用户和场景的不同,我们遇到了模型泛化性(Generalization)问题,这也是几乎所有计算机视觉任务落地时都会遇到的问题。
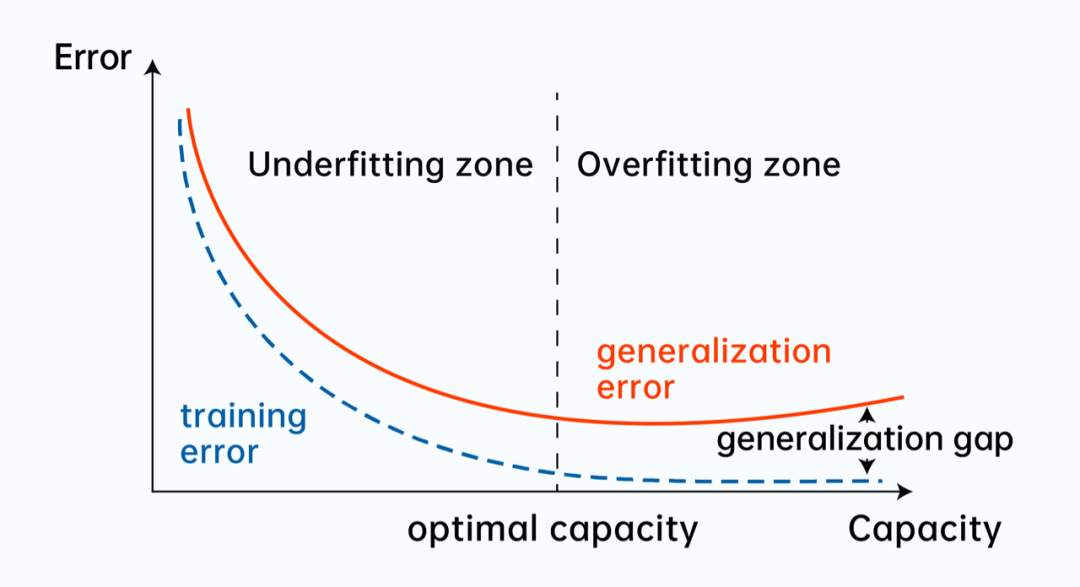
图 9:泛化性、欠拟合(underfitting)、过拟合(overfitting)示意图
泛化性指模型经过训练后,应用到新数据并做出准确预测的能力。一个模型在训练数据上如果被训练得太好往往会导致过拟合,以致泛化性降低。
针对此问题,一方面从网络结构和训练策略出发,增加必要的组件,比如一定强度的 DropOut,损失函数正则项,设计 EarlyStopping 机制,另一方面我们针对出现的场景问题,比如 “眼镜反光”,“阴阳脸”,“镜头模糊脏污” 等,进行多轮测试后去追溯和定位问题,然后设计了针对性的数据增强方案,通过完备性的消融实验(ablation experiment),确定了最优的流程和相应超参数,在训练过程中引入相应的数据模式,极大的提升了模型的精确性和鲁棒性,从而解决了这一难题。
3、表情的协调性
如何让虚拟形象不同的表情之间自然的联动,这是整个团队协作解决的问题。
一方面算法在网络 Backbone 的设计考量上,我们引入了 MobileViT 模块,因为尽管 CNN 网络在视觉任务上具有参数少效果好以及空间感知的优势,然而这种空间感知是局部的,全局感知可以通过注意力机制和 transformer 实现,然而普通的 transformer 无法部署在移动端,MobileViT 可以将 ViT 与 MobileNetV2 的结合起来,兼顾全局信息和轻量化的需求,让模型的推理效果又快又准。
另一方面,开发和设计同学持续的解决虚拟形象的各种材质渲染难题,最后才有了现在 ZegoAvatar 精确而自然的随动效果。
ZEGO
ZegoAvatar 面部表情随动是 ZEGO 基于已有业务,通过 AI 结合元宇宙赛道的一次成功的尝试和突破,我们从数据采集方案到模型架构设计再到训练策略整个算法闭环,以及虚拟形象和相关组件的开发实现了完全的自研,在实际的落地效果上,我们做到了行业领先水平。
对于落地遇到的各种问题,我们从本质出发,设计针对性的方案进行解决,整个项目用较少的数据,取得了很好的效果。基于 ZegoAvatar,不同业务切入点的新的算法开发也在进行中,后续会有更多新的项目孵化,ZEGO 即构科技将进一步在互动智能领域不断实现技术革新与突破,在元宇宙浪潮中扬帆起航!
获取更多帮助
获取 SDK 开发文档、demo,可访问 即构文档中心;
获取更多商务活动热门产品,可提交 信息联系商务;
注册即构 ZEGO 开发者帐号,快速开始;
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


