
本文是深度学习入门: 基于Python的实现、神经网络与深度学习(NNDL)以及动手学深度学习的读书笔记。本文将介绍基于Numpy的卷积神经网络(Convolutional Networks,CNN)的实现,本文主要重在理解原理和底层实现。
一、概述
1.1 卷积神经网络(CNN)
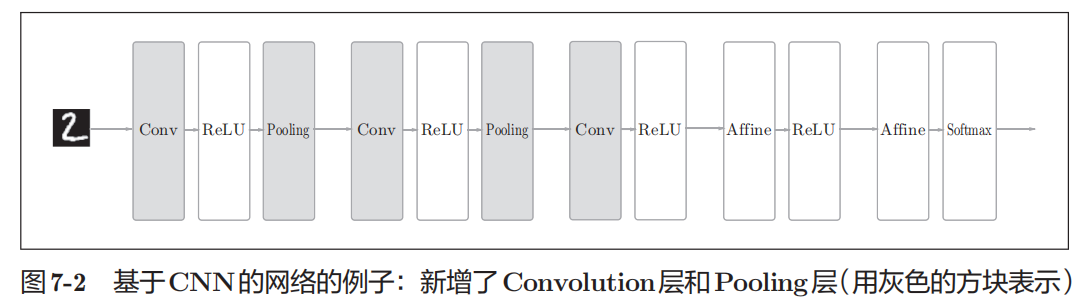
卷积神经网络(CNN)是一种具有局部连接、权重共享和平移不变特性的深层前馈神经网络。
CNN利用了可学习的kernel卷积核(filter滤波器)来提取图像中的模式(局部和全局)。传统图像处理会手动设计卷积核(例如高斯核,来提取边缘信息),而CNN则是数据驱动的。
在数学上,针对一维序列数据,卷积运算可以被理解为一种移动平均(利用历史信号对当前时刻信息进行平滑等处理,换句话说就是考虑当前时刻信息和以前时刻信息的按一定比例延迟的叠加)。而二维卷积运算,通常在图像处理中用于平滑信号达到滤波(例如高斯平滑,削峰填谷)或提取特征等。

1.2 卷积层
1.2.1 卷积运算

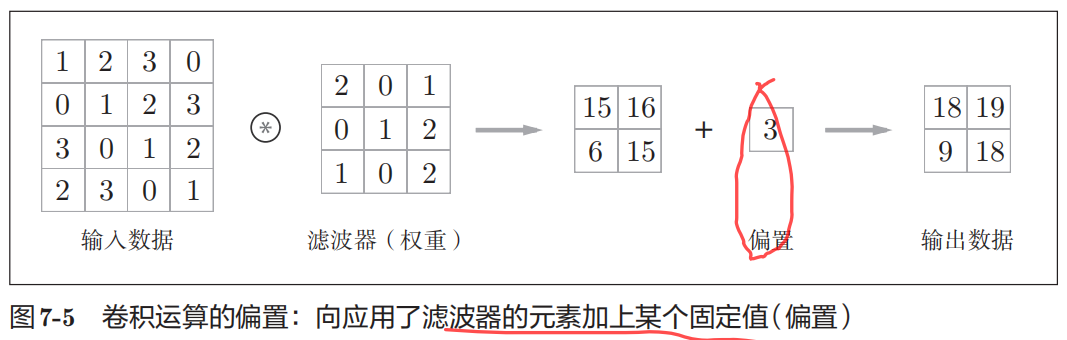
令输入数据(图片)的形状为(H, W),其中H为图片的高height, W为图片的宽width,卷积核(滤波器Filter)的形状为(FH, FW),其中FH代表Filter Height,FW代表Filter Width。
卷积运算将在输入数据上,以一定间隔(Stride步长或步幅)整体地滑动滤波器的窗口并将滤波器各个位置上的权重值和输入数据的对应元素相乘。然后,将这个结果保存到输出的对应位置。将这个过程在所有位置都做一遍,就能得到卷积运算的输出。此外,在卷积后,通常会在每个位置的数据上加偏置项。
1.2.2 填充和步幅

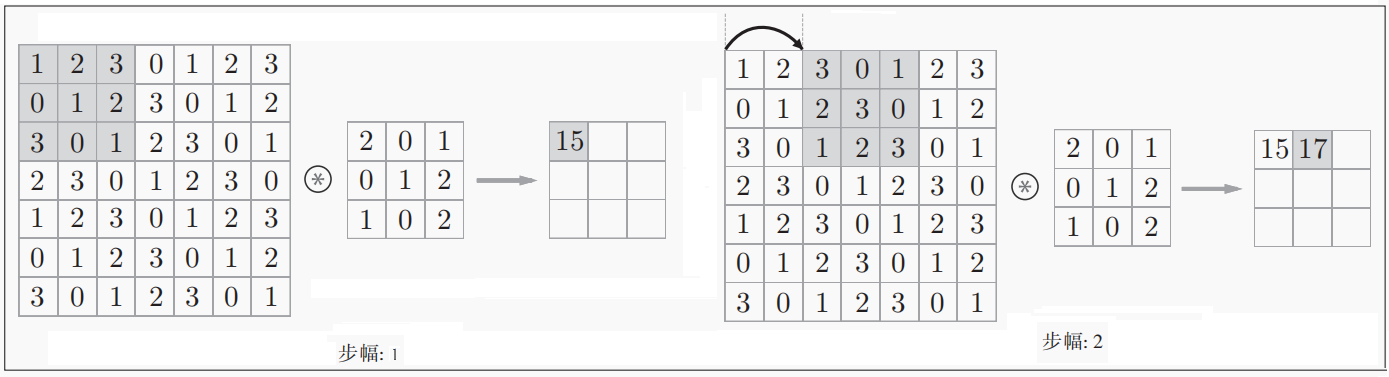
应用滤波器的位置间隔称为步幅(stride)。如上图所示,之前的例子中步幅S都是1,如果将步幅S设为2,应用滤波器的窗口的间隔变为2个元素。综上,增大步幅后,输出大小会变小。而增大填充后,输出大小会变大。对于填充和步幅,输出大小的关系如下式所示:

1.2.3 通道
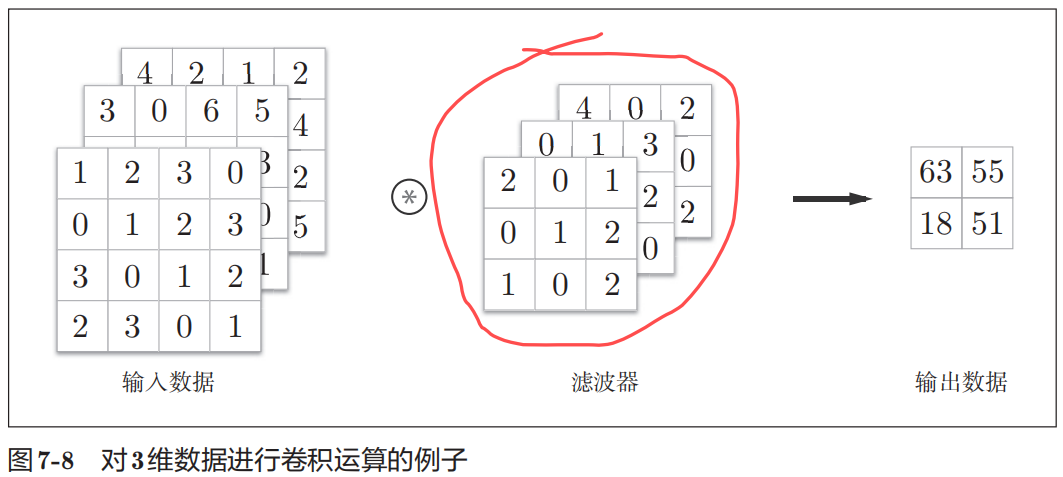
之前的卷积运算的例子都是以有高、长方向的2维形状为对象的。但是,图像是3维数据,除了高、长方向之外,还需要处理通道方向(例如,RGB)。上图以3通道的数据为例,展示了卷积运算的结果。和处理2维数据时相比,可以发现纵深方向(通道方向)上特征图增加了。通道方向上有多个特征图时,可以按通道进行输入数据和滤波器的卷积运算,并将结果相加,从而得到输出。不同通道的Kernel大小应该一致。

为了便于理解3维数据的卷积运算,我们这里将数据和滤波器结合长方体的方块来考虑。方块是上图所示的3维长方体。把3维数据表示为多维数组时,书写顺序为(channel, height, width)。比如,通道数为C、高度为H、长度为W的数据的形状可以写成(C, H, W)。滤波器也一样,要对应顺序书写。比如,通道数为C、滤波器高度为FH、长度为FW时,可以写成(C, FH, FW)。若使用FN个滤波器,输出特征图也将有FN个。如果将这FN个特征图汇集在一起,就得到了形状为(FN, OH, OW)的方块。
卷积运算中(和全连接层一样)存在偏置。如果进一步追加偏置的加法运算处理,要对滤波器的输出结果(FN, OH, OW)按通道加上相同的偏置值。
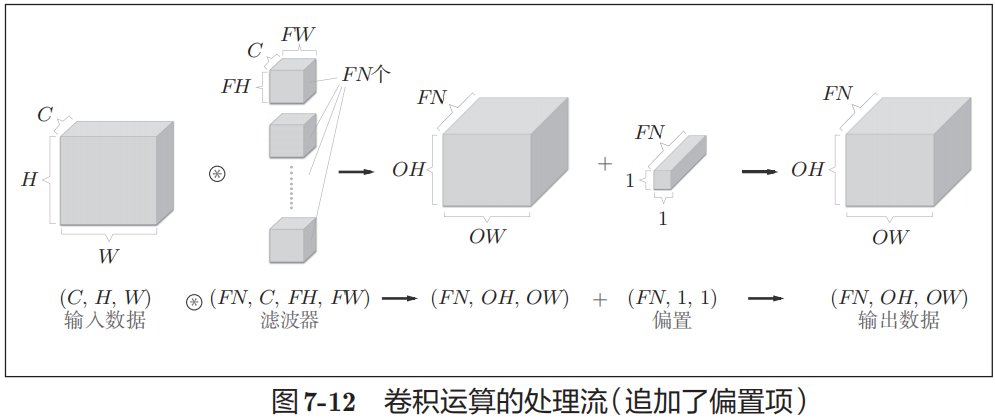
当前只是一个输入(单个3通道图像),还可以输入N个图像,构成一个Batch,以矩阵乘法加速。
1.3 池化层
池化层(汇聚层,Pooling Layer)也叫子采样层(Subsampling Layer),其作用是进行特征选择,降低特征数量,从而减少参数数量。具体来说,池化是缩小高、长方向上的空间的运算(多变少)。在卷积层之后加上一个汇聚层,可以降低特征维数,避免过拟合。
池化层的特性:
1)没有要学习的参数
池化层和卷积层不同,没有要学习的参数。池化只是从目标区域中取最大值(或者平均值),所以不存在要学习的参数
2) 通道数不发生变化
经过池化运算,输入数据和输出数据的通道数不会发生变化
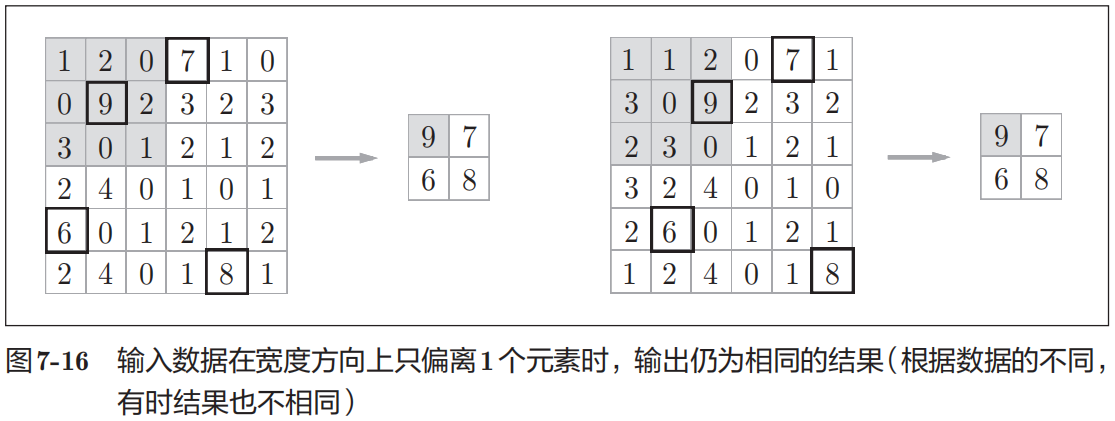
3) 对微小的位置变化具有鲁棒性(健壮,容噪)
当输入数据发生微小偏差时,池化仍会返回相同的结果。因此,池化对输入数据的微小偏差具有鲁棒性
二、CNN实现
卷积层和池化层的实现看起来很复杂,但实际上可通过使用技巧来简化实现。本节将介绍先im2col技巧,然后再进行卷积层的实现。
2.1 Im2col技巧
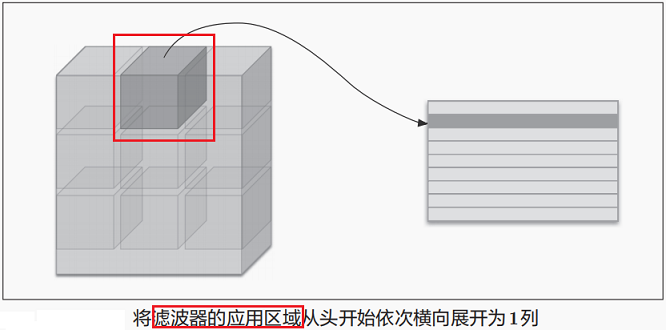

实际上,im2col函数就是将输入数据中所有滤波器需要处理的局部数据(即滑动窗口对应的数据)事先拿出来,展开为矩阵形式(每一行对应一个数据),然后将卷积核也展开为列向量,随后就可将两者做矩阵乘法运算来加速卷积操作(本质上,卷积核和对应数据的卷积运算就是在做内积)。这和全连接层的Affine层进行的处理基本相同(滤波器本质上仍是权重矩阵)。
此外,对于大小相同的一批数据,由于卷积层的滤波器没变,所以只需将数据按行拼接,计算后再reshape即可。im2col的实现如下,就是按卷积核来滑动窗口预先取出并展开数据:
1 def im2col(input_data, filter_h, filter_w, stride=1, pad=0):
2 """
3 把对应卷积核的数据部分拿出来,reshape为向量,进一步拼为矩阵
4 Parameters:
5 input_data (tensor): 由(数据量, 通道, 高, 宽)的4维张量构成的输入数据
6 filter_h (int): 滤波器的高
7 filter_w (int): 滤波器的宽
8 stride (int): 步幅
9 pad (int): 填充
10
11 Returns:
12 col (tensor): 2维数组
13 """
14 N, C, H, W = input_data.shape
15 out_h = (H + 2*pad - filter_h)//stride + 1
16 out_w = (W + 2*pad - filter_w)//stride + 1
17
18 img = np.pad(input_data, [(0,0), (0,0), (pad, pad), (pad, pad)], 'constant')
19 col = np.zeros((N, C, filter_h, filter_w, out_h, out_w))
20
21 for y in range(filter_h):
22 y_max = y + stride*out_h
23 for x in range(filter_w):
24 x_max = x + stride*out_w
25 col[:, :, y, x, :, :] = img[:, :, y:y_max:stride, x:x_max:stride]
26
27 col = col.transpose(0, 4, 5, 1, 2, 3).reshape(N*out_h*out_w, -1)
28 return col
此外,给出其逆操作,以便实现梯度反向传播:
1 def col2im(col, input_shape, filter_h, filter_w, stride=1, pad=0):
2 """
3 im2col的逆处理,将展开后的数据还原回原始输入数据形式
4 Parameters:
5 col (tensor): 2维数组
6 input_shape (int): 输入数据的形状(例:(10, 1, 28, 28))
7 filter_h (int): 滤波器的高
8 filter_w (int): 滤波器的宽
9 stride (int): 步幅
10 pad (int): 填充
11 Returns:
12 """
13 N, C, H, W = input_shape
14 out_h = (H + 2*pad - filter_h)//stride + 1
15 out_w = (W + 2*pad - filter_w)//stride + 1
16 col = col.reshape(N, out_h, out_w, C, filter_h, filter_w).transpose(0, 3, 4, 5, 1, 2)
17 img = np.zeros((N, C, H + 2*pad + stride - 1, W + 2*pad + stride - 1))
18
19 for y in range(filter_h):
20 y_max = y + stride*out_h
21 for x in range(filter_w):
22 x_max = x + stride*out_w
23 img[:, :, y:y_max:stride, x:x_max:stride] += col[:, :, y, x, :, :]
24 return img[:, :, pad:H + pad, pad:W + pad]
2.2 卷积层的实现
1 class Convolution:
2 def __init__(self, W, b, stride=1, pad=0):
3 # 卷积层的初始化方法将滤波器(权重)、偏置、步幅、填充作为参数
4 # 滤波器是 (FN, C, FH, FW), Filter Number滤波器数量、Channel、Filter Height、Filter Width
5 self.W = W # 每一个Filter(原本为3维tensor权重)将reshape为权重向量 [(C*FH*FW) X 1], 列向量
6 self.b = b # C一个Filter将拼接为为卷积核权重矩阵 [(C*FH*FW) X FN]
7 self.stride = stride
8 self.pad = pad
9 # 中间数据(backward时使用)
10 self.x = None
11 self.col = None
12 self.col_W = None
13 # 权重和偏置参数的梯度
14 self.dW = None
15 self.db = None
16
17 def forward(self, x):
18 FN, C, FH, FW = self.W.shape
19 N, C, H, W = x.shape
20 out_h = 1 + int((H + 2*self.pad - FH) / self.stride)
21 out_w = 1 + int((W + 2*self.pad - FW) / self.stride)
22 # 用im2col展开输入数据x,并用reshape将滤波器权重展开为2维数组。
23 col = im2col(x, FH, FW, self.stride, self.pad)
24 col_W = self.W.reshape(FN, -1).T
25 out = np.dot(col, col_W) + self.b # 计算展开后的矩阵的乘积
26 out = out.reshape(N, out_h, out_w, -1).transpose(0, 3, 1, 2) # (N, C, H, W)
27
28 self.x = x
29 self.col = col
30 self.col_W = col_W
31 return out
32
33 def backward(self, dout):
34 FN, C, FH, FW = self.W.shape
35 dout = dout.transpose(0,2,3,1).reshape(-1, FN)
36 self.db = np.sum(dout, axis=0)
37 self.dW = np.dot(self.col.T, dout) # 类似于Affine Transformation的参数梯度的计算
38 self.dW = self.dW.transpose(1, 0).reshape(FN, C, FH, FW)
39
40 dcol = np.dot(dout, self.col_W.T)
41 dx = col2im(dcol, self.x.shape, FH, FW, self.stride, self.pad)
42 return dx # 回传的梯度
2.3 池化层的实现


1 class Pooling:
2 def __init__(self, pool_h, pool_w, stride=1, pad=0):
3 # 池化层的实现和卷积层相同,都使用im2col展开输入数据
4 self.pool_h = pool_h
5 self.pool_w = pool_w
6 self.stride = stride
7 self.pad = pad
8 self.x = None
9 self.arg_max = None
10
11 def forward(self, x):
12 N, C, H, W = x.shape
13 out_h = int(1 + (H - self.pool_h) / self.stride)
14 out_w = int(1 + (W - self.pool_w) / self.stride)
15 col = im2col(x, self.pool_h, self.pool_w, self.stride, self.pad)
16 col = col.reshape(-1, self.pool_h*self.pool_w)
17 # X展开之后,只需对展开的矩阵求各行的最大值,并转换为合适的形状
18 arg_max = np.argmax(col, axis=1)
19 out = np.max(col, axis=1)
20 out = out.reshape(N, out_h, out_w, C).transpose(0, 3, 1, 2)
21
22 self.x = x
23 self.arg_max = arg_max # 仅对池化后的元素求梯度(相当于一个特殊的Relu,mask掉了其他元素)
24 return out
25
26 def backward(self, dout):
27 dout = dout.transpose(0, 2, 3, 1)
28 pool_size = self.pool_h * self.pool_w
29 dmax = np.zeros((dout.size, pool_size)) # 只将dout赋予那些池化后的得到元素的位置,其余元素梯度置为0
30 dmax[np.arange(self.arg_max.size), self.arg_max.flatten()] = dout.flatten()
31 dmax = dmax.reshape(dout.shape + (pool_size,))
32
33 dcol = dmax.reshape(dmax.shape[0] * dmax.shape[1] * dmax.shape[2], -1)
34 dx = col2im(dcol, self.x.shape, self.pool_h, self.pool_w, self.stride, self.pad)
35 return dx # 将column重新组织层图片输入形状,并回传梯度
2.4 CNN的实现
1 class SimpleConvNet:
2 """简单的ConvNet: conv - relu - pool - affine - relu - affine - softmax
3 Parameters:
4 input_size : 输入大小(MNIST的情况下为784)
5 hidden_size_list : 隐藏层的神经元数量的列表(e.g. [100, 100, 100])
6 output_size : 输出大小(MNIST的情况下为10)
7 activation : 'relu' or 'sigmoid'
8 weight_init_std : 指定权重的标准差(e.g. 0.01)
9 指定'relu'或'he'的情况下设定“He的初始值”
10 指定'sigmoid'或'xavier'的情况下设定“Xavier的初始值”
11 """
12 def __init__(self, input_dim=(1, 28, 28),
13 conv_param={'filter_num': 30, 'filter_size': 5, 'pad': 0, 'stride': 1},
14 hidden_size=100, output_size=10, weight_init_std=0.01):
15 filter_num = conv_param['filter_num']
16 filter_size = conv_param['filter_size']
17 filter_pad = conv_param['pad']
18 filter_stride = conv_param['stride']
19 input_size = input_dim[1]
20 conv_output_size = (input_size - filter_size + 2 * filter_pad) / filter_stride + 1
21 pool_output_size = int(filter_num * (conv_output_size / 2) * (conv_output_size / 2))
22
23 # 初始化权重
24 self.params = {}
25 self.params['W1'] = weight_init_std *
26 np.random.randn(filter_num, input_dim[0], filter_size, filter_size)
27 self.params['b1'] = np.zeros(filter_num)
28 self.params['W2'] = weight_init_std *
29 np.random.randn(pool_output_size, hidden_size)
30 self.params['b2'] = np.zeros(hidden_size)
31 self.params['W3'] = weight_init_std *
32 np.random.randn(hidden_size, output_size)
33 self.params['b3'] = np.zeros(output_size)
34
35 # 生成层
36 self.layers = OrderedDict()
37 self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'],
38 conv_param['stride'], conv_param['pad'])
39 self.layers['Relu1'] = Relu()
40 self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2)
41 self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2'])
42 self.layers['Relu2'] = Relu()
43 self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3'])
44
45 self.last_layer = SoftmaxWithLoss()
46
47 def predict(self, x):
48 for layer in self.layers.values():
49 x = layer.forward(x)
50
51 return x
52
53 def loss(self, x, t):
54 """求损失函数。参数x是输入数据、t是教师标签
55 """
56 y = self.predict(x)
57 return self.last_layer.forward(y, t)
58
59 def gradient(self, x, t):
60 """求梯度(误差反向传播法)
61
62 Parameters:
63 x : 输入数据
64 t : 教师标签
65
66 Returns:
67 具有各层的梯度的字典变量
68 grads['W1']、grads['W2']、...是各层的权重
69 grads['b1']、grads['b2']、...是各层的偏置
70 """
71 # forward
72 self.loss(x, t)
73
74 # backward
75 dout = 1
76 dout = self.last_layer.backward(dout)
77
78 layers = list(self.layers.values())
79 layers.reverse()
80 for layer in layers:
81 dout = layer.backward(dout)
82
83 # 设定
84 grads = {}
85 grads['W1'], grads['b1'] = self.layers['Conv1'].dW, self.layers['Conv1'].db
86 grads['W2'], grads['b2'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
87 grads['W3'], grads['b3'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
88 return grads
89
90 def save_params(self, file_name="params.pkl"):
91 params = {}
92 for key, val in self.params.items():
93 params[key] = val
94 with open(file_name, 'wb') as f:
95 pickle.dump(params, f)
96
97 def load_params(self, file_name="params.pkl"):
98 with open(file_name, 'rb') as f:
99 params = pickle.load(f)
100 for key, val in params.items():
101 self.params[key] = val
102
103 for i, key in enumerate(['Conv1', 'Affine1', 'Affine2']):
104 self.layers[key].W = self.params['W' + str(i+1)]
105 self.layers[key].b = self.params['b' + str(i+1)]
三、典型的深度CNN

LeNet-5是由Yann LeCun提出的第一个也是非常经典的卷积神经网络模型。LeNet-5的网络结构如上图所示。LeNet-5共有7层,接受输入图像大小为32 × 32 = 1 024,输出对应10个类别的得分。LeNet中使用了sigmoid函数,而现在的CNN中主要使用ReLU函数。
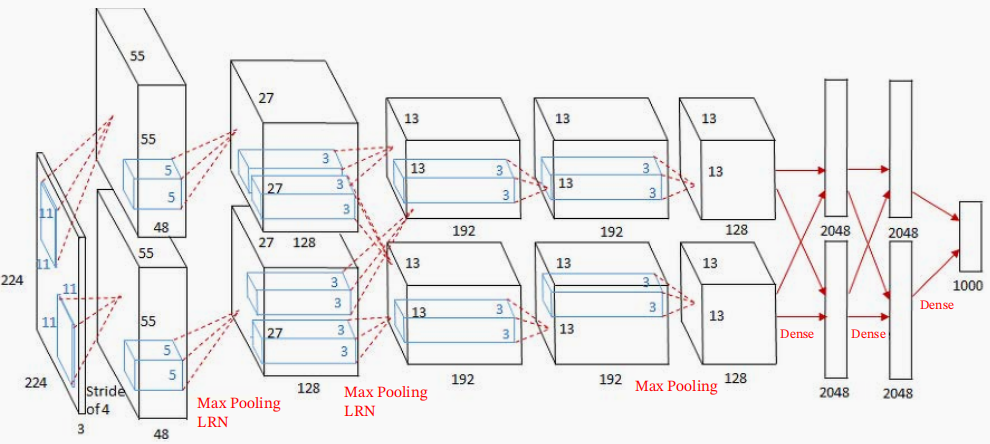
AlexNet堆叠了多个卷积层和池化层,最后经由全连接层输出结果。虽然结构上AlexNet和LeNet没有大的不同,但有以下几点差异。它的激活函数用了ReLU,应用了Dropout,并使用了局部正规化的LRN(Local Response Normalization)层来避免过拟合。
上述两个网络都可以用Numpy来实现,不过为了实现方便和避免重复造低效的轮子,可以直接用Pytorch或Tensorflow等框架来实现或使用现成的网络。例如, LeNet-5可以直接用如下几行pytorch代码实现:

文章来源: 博客园
原文链接: https://www.cnblogs.com/justLittleStar/p/16349725.html
- 还没有人评论,欢迎说说您的想法!



 客服
客服


