
1.布隆过滤器的概念
-
定义
布隆过滤器:是⼀种概率型数据结构,特点是⾼效的插⼊和查询,能明确告知某个字符串⼀定不存在或者可能存在;
-
优点和缺点
- 优点:布隆过滤器相⽐传统的查询结构更加⾼效,占⽤空间更⼩;
- 例如:hash,set,map等数据结构-》冲突率高的时候,插入和查询效率降低
- 缺点:是它返回的结果是概率性的,也就是说结果存在误差的(假阳率),虽然这个误差是可控的;同时它不⽀持删除操作;
- 优点:布隆过滤器相⽐传统的查询结构更加⾼效,占⽤空间更⼩;
-
组成:位图(bit数组)+ n个hash函数

-
工作原理
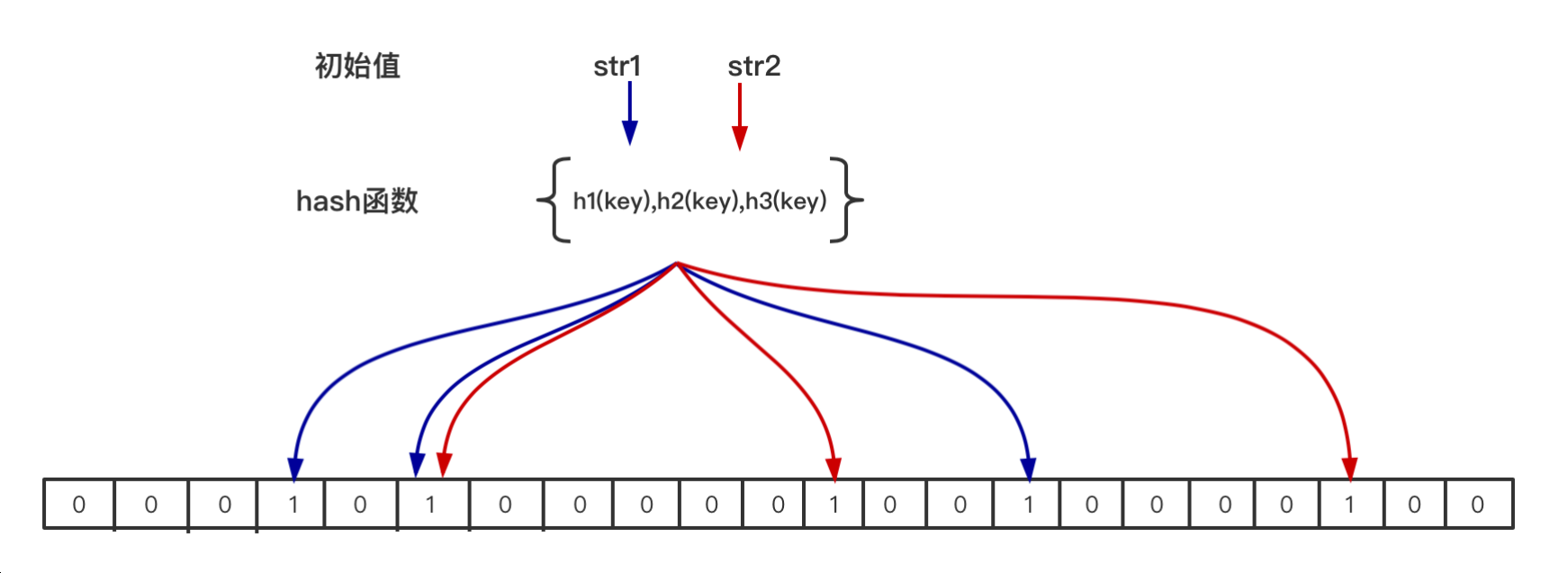
- 插入:当⼀个元素加⼊位图时,通过k个hash函数将这个元素映射到位图的k个点,并把它们置为1;
- 检索:当检索时,再通过k个hash函数运算检测位图的k个点是否都为1;
- 如果有不为1的点,那么认为不存在;如果全部为1,则可能存在(存在误差);
- 删除不支持:在位图中每个槽位只有两种状态(0或者1),⼀个槽位被设置为1状态,但不明确它被设置了多少次;
- 也就是不知道被多少个str1哈希映射以及是被哪个hash函数映射过来的;所以不⽀持删除操作;
-
实际中使用布隆过滤器
-
确定n和p,网站计算出m和k -》https://hur.st/bloomfilter
n -- 布隆过滤器中元素的个数,如上图 只有str1和str2 两个元素 那么 n=2 p -- 假阳率,在0-1之间 0.000000 m -- 位图所占空间 k -- hash函数的个数 公式如下: n = ceil(m / (-k / log(1 - exp(log(p) / k)))) p = pow(1 - exp(-k / (m / n)), k) m = ceil((n * log(p)) / log(1 / pow(2, log(2)))); k = round((m / n) * log(2)); -
对于k个哈希函数的选择 -》在双重hash的基础上进行扩展
// 采⽤⼀个hash函数,给hash传不同的种⼦偏移值 // #define MIX_UINT64(v) ((uint32_t)((v>>32)^(v))) uint64_t hash1 = MurmurHash2_x64(key, len, Seed); uint64_t hash2 = MurmurHash2_x64(key, len, MIX_UINT64(hash1)); for (i = 0; i < k; i++) // k 是hash函数的个数 { Pos[i] = (hash1 + i*hash2) % m; // m 是位图的⼤⼩ } // 通过这种⽅式来模拟 k 个hash函数
-
2.为什么出现这项技术
-
需要对海量字符串类型的数据进行过滤,减少一些比对,或者剔除一些垃圾数据
-
背景1:缓存穿透问题如何解决
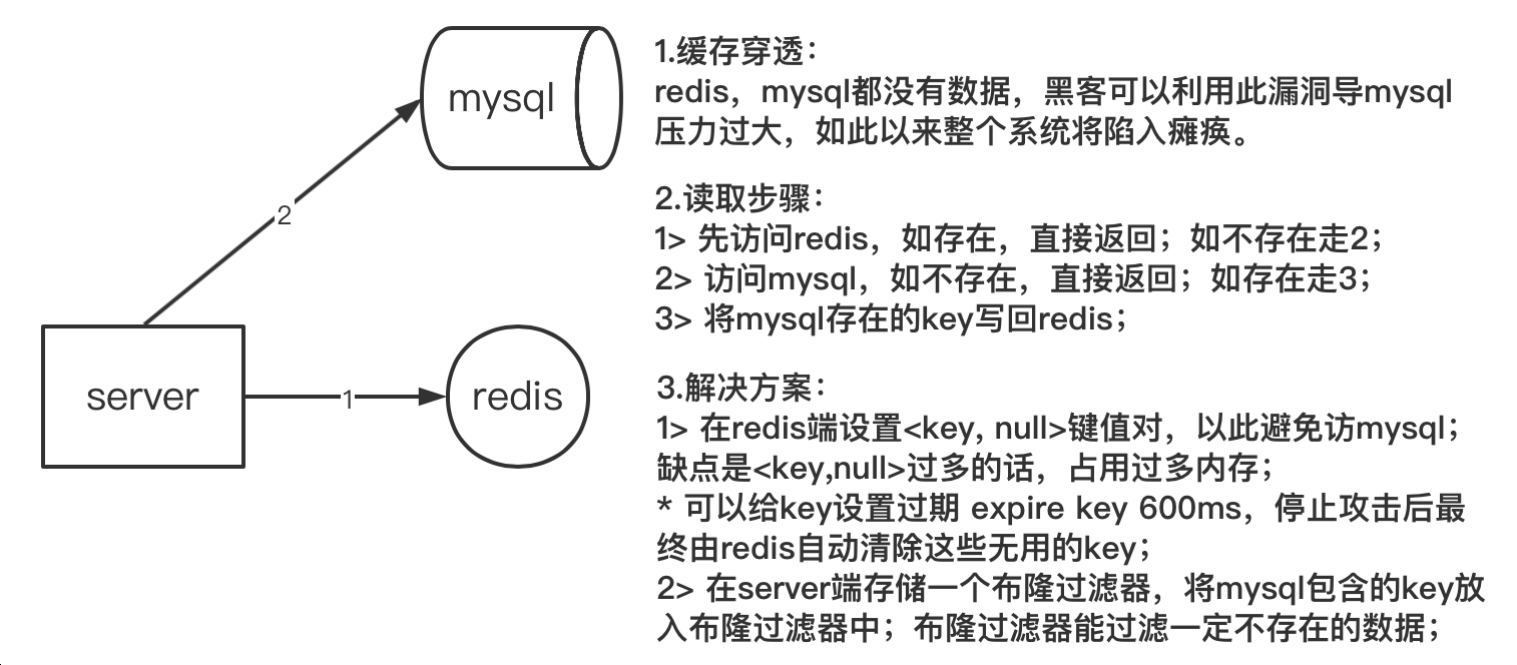
- 缓存场景:为了减轻数据库(mysql)的访问压力,在server端与mysql之间加⼊⼀层缓冲数据层(⽤来存放热点数据);
- 缓存穿透:server端向数据库请求数据时,缓存数据库(redis)和落盘数据库(mysql)都不包含该数据,大量的数据请求压⼒全部涌向落盘数据库(mysql),导致超出负载;
-
原因:⿊客利⽤漏洞伪造数据攻击或者内部业务bug重复⼤量请求不存在的数据;
-
解决方案:如图 3 的描述;
- 方案一:在redis设置key过期
- 方案二:在sever端使用布隆过滤器
-
-
背景2:从海量数据中查询某字符串是否存在
-
为什么不使用set/map或者unordered_map
- 即便set和map的查询效率如此之高,但是每一次比较都是比较的字符串,这样查询效率仍然是消耗效率
- 虽然unordered_map由于使用了hashtable不需要比较字符串,但是需要存储具体字符串(key值--》string),如果数据量⼤,提供不了⼏百G的内存;set/map也一样
- 并且hashtable在出现冲突的时候仍然需要比较字符串
-
因此使用布隆过滤器这种数据结构非常有用
-
3.常用使用形式----》用途
-
应用背景
- 在使⽤word⽂档时,word如何判断某个单词是否拼写正确?控制误差 假阳率
- ⽹络爬⾍程序,怎么让它不去爬相同的url⻚⾯?允许有误差
- 垃圾邮件(短信)过滤算法如何设计?允许有误差
- 公安办案时,如何判断某嫌疑⼈是否在⽹逃名单中?控制误差 假阳率
- 缓存穿透问题如何解决?允许有误差
4.总结
- 如果比较的key值是便于比较的类型(int...),支持插入查询删除操作,使用set/map
- 如果是少量字符串(冲突率低)的形式,且支持插入查询删除操作,使用unordered_map
- 如果数据量很大(冲突率高),字符串的形式,且不需要删除操作的时候,使用布隆过滤器
5.相关联的,相对比的技术
- set/map/unordered_map底层实现原理
内容来源于网络如有侵权请私信删除
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


