
我们在做采集数据的时候,过快或者访问频繁,或者一访问就给弹出验证码,然后就蚌珠了~

今天就给大家来一个简单处理验证码的方法
本文使用的是 Python和pycharm
这里需要用到一个 ddddocr 模块 ,这是别人开源写好的一个东西,简单又好用,但是精确度差一点点,但是还是非常好用的。
如果你追求精确度的话,可以调用别人写好的一些API 。
咱们直接 win+r 弹出搜索框后输入 cmd ,点击确定弹出命令提示符窗口, 输入pip install ddddocr 即可安装。
代码不多,非常简单。
模块安装好之后咱们先导入一下
import ddddocr
然后实例化一下,用一个 cor 接收一下这个数据。
ocr = ddddocr.DdddOcr()
我这里准备了四个验证码




分别实现一下验证码
首先我们用 with open 来读取一下这文件,读取方式使用 rb ,因为是图片的话就读取它的二进制数据
with open('img_3.png', 'rb') as f:
使用 f.read() 将数据读取出来,再自定义一个变量接收一下。
img_bytes = f.read()
然后我们通过 classification 将它传进去,把结果打印出来就可以了。
result = ocr.classification(img_bytes) print(result)
# 很多小伙伴经常因为在学习的过程中因为没有好的学习资料、不清楚学习方向要学什么知识点,以及遇到问题不能及时得到解决,所以导致学习坚持不下去。 # 我给大家准备了2022最新的Python学习路线图和学习资料、视频教程、电子书等等,都放在这个群里了,还有大佬不定时解答问题,同更多志同道合的伙伴一起学习、一起进步! # python学习交流1群:815624229 (一群已满 加2群)## # Python学习交流2群:279199867 ##
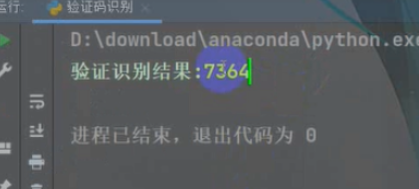
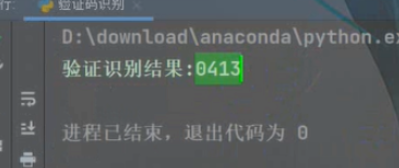
纯数字的
字母+数字的
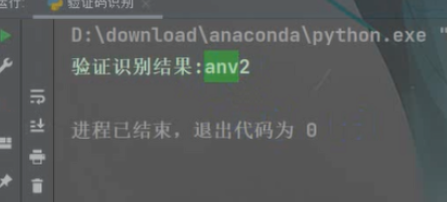
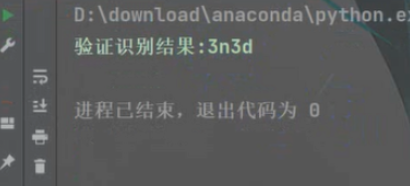
可以看到都完整的识别出来了,即使上面有一些花里胡哨的横线啥的。
import ddddocr ocr = ddddocr.DdddOcr() with open('img_3.png', 'rb') as f: img_bytes = f.read() result = ocr.classification(img_bytes) print(result)
大家可以自己去试试,也可以直接应用在采集数据实践当中~
创作不易,大家帮忙点个收藏吧~

内容来源于网络如有侵权请私信删除
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


