

写在前面的话
写在前面的话
有的同学问我,开始讲的很基础,节奏比较慢,这个是因为一个为了让大家慢慢进入状态,后面的节奏会越来越快的,大家不要着急,另一个是因为简单的东西重复,温故而知新,更希望给你们带来的是思想和观念的成长,这个需要铺垫。这个有点像练武功,要想练就高深的武功,需要循序渐进,不然很容易走火入魔的,所以要把根基打扎实,不能着急。这里剧透下,后面会给大家带来一个一个绝世功法:《HDFS成长记》、《ZK成长记》、《Spring Cloud Alibaba成长记》、《Spring Cloud 成长记》、《Kafka成长记》、《Redis成长记》、《MySQL成长记》等等。也会有一些基础心法,比如《Netty 成长记》、《JVM成长记》《OS 成长记》、《网络成长记》等等。
好了,不多说了,让我们开始吧!
通过之前的三节,相信你已经对ArrayList中大多方法的底层逻辑都有了很深入的了解,最为ArrayList的最后一节,这节跟大家看下ArrayList的遍历和一些高级方法的底层原理,最后让你可以对ArrayList底层了如执掌,面对各种ArrayList的面试题能对答如流,甚至可以手撸一个ArrayList的代码出来。
ArrayList的遍历到底有什么猫腻呢?
ArrayList的遍历到底有什么猫腻呢?
当你使用ArrayList的时候,最常用的除了add方法,是不是就是for循环的遍历。一般你遍历ArrayList,无非就是一下几种方法:
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class ArrayListDemo {
public static void main(String[] args) {
List<String> hostList = new ArrayList<>(3);
hostList.add("host1");
hostList.add("host2");
hostList.add("host3");
//方法1
for (int i = 0; i < hostList.size(); i++) {
System.out.println(hostList.get(i));
}
//方法2
for (String host : hostList) {
System.out.println(host);
}
//方法3
for (Iterator<String> iterator = hostList.iterator(); iterator.hasNext();) {
String host = iterator.next();
System.out.println(host);
}
//方法4
hostList.forEach(host->System.out.println(host));
//方法5 这种遍历涉及stream底层源码,这里我们不做过多探索
hostList.stream().forEach(host->System.out.println(host));
}
}
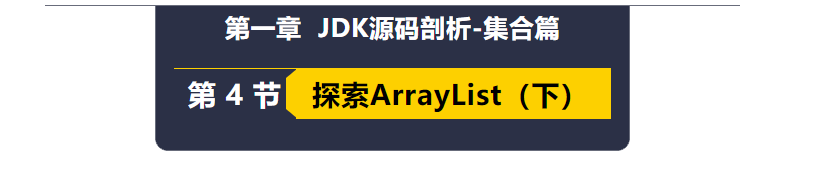
方法1,这种方式使用了for循环,通过get方法访问元素,你应该知道底层就是数组基本操作elementData[index]。
方法2底层其实和方法3是一模一样的,只不过方法2只是一种便捷的语法糖而已,方便让你使用。
方法4底层和方法1是一样的,都是用来for循环+数组基本操作elementData[index]。
方法5 是通过Java8 stream的API进行forEach,这里我们不做过多探索,一般也不建议这么使用,不如使用方法4有效率。
所以值得你探索的两个方法是方法3和方法4的源码,先看下forEach的源码:
@Override
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
final int expectedModCount = modCount;
@SuppressWarnings("unchecked")
final E[] elementData = (E[]) this.elementData;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
action.accept(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
直接看到核心脉络就是for循环,通过数组基本操作elementData[index]访问数组获取到对应元素,传递给了Java8的Consumer函数表达式,执行对应的逻辑。这个和你自己写for循环,执行自己的逻辑是不是一样的,所以说这种方法和之前的方法1本质没有什么区别,也就是换了一个语法糖而已。
方法1和方法4的源码原理,如下图:
我们再看看方法3 Iterator的源码:
for (Iterator<String> iterator = hostList.iterator(); iterator.hasNext();) {
String host = iterator.next();
System.out.println(host);
}
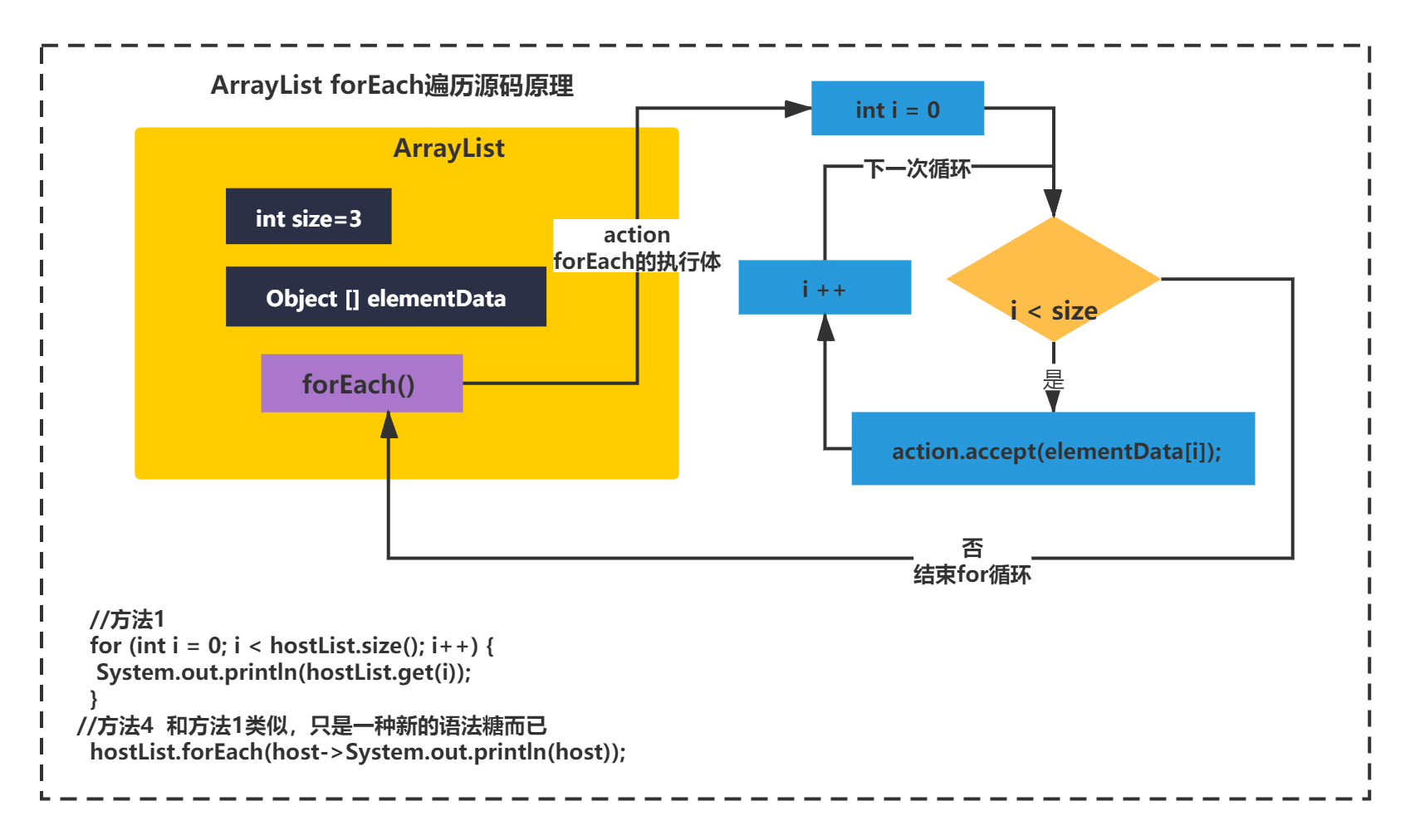
根据for循环执行逻辑,第一句执行的方法应该是hostList.iterator(),你可以在ArrayList的源码中看到这个方法:
public Iterator<E> iterator() {
return new Itr();
}
可以看到直接返回了一个new Itr()对象,这个类不知道你还有没有印象?记得第一节看ArrayList的源码脉络的时候,有几个内部类,其中是不是就有一个lrt类。如下图所示:
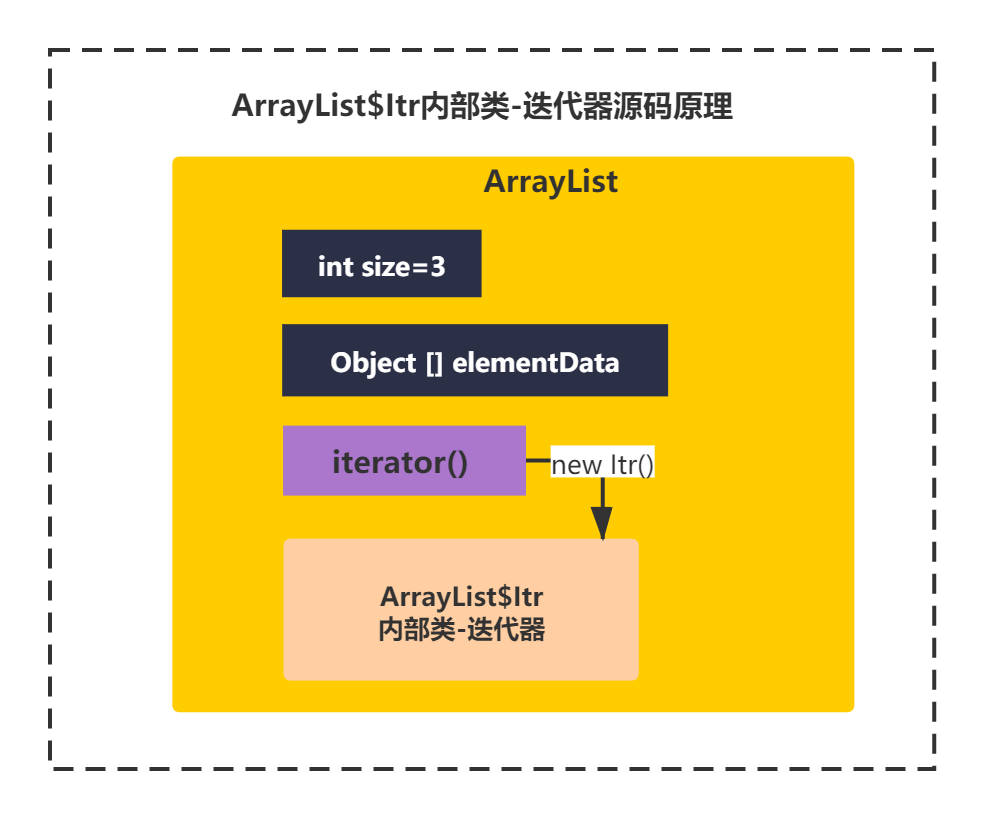
没错,这个就是我们常称的迭代器,他是集合中常见的遍历工具。你可以接着往下看:
private class Itr implements Iterator<E> {
Itr() {}
// 省略无关代码
}
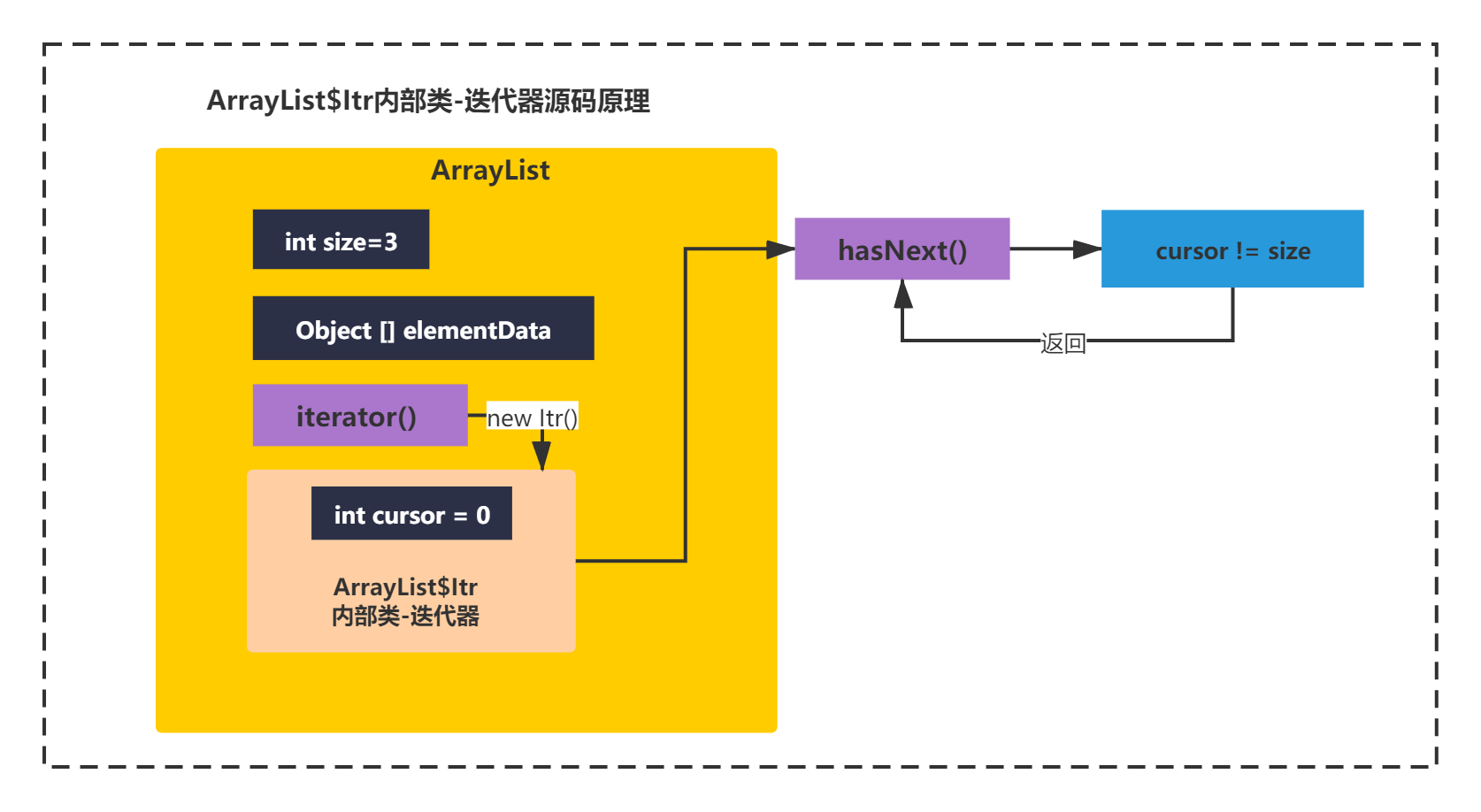
你会发现构造函数什么都没有做。那么for循环接着执行条件表达式iterator.hasNext();即如下代码:
private int size;
private class Itr implements Iterator<E> {
int cursor;
public boolean hasNext() {
return cursor != size;
}
// 省略无关代码
}
这里意思是如果cursor的值和数组大小不相等,就返回false。cursor是int类型,所以默认值是0。上面的Demo中,size=3,第一次遍历肯定cursor=0 != size=3所以直接返回true。
源码原理如下所示:
之后for循环执行循环体,会执行Stringhost = iterator.next();这句话的源码如下:
private int size;
transient Object[] elementData;
private class Itr implements Iterator<E> {
int cursor;
int lastRet = -1;
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
// 省略无关代码
}
还是先看下脉络,首先checkForComodification应该是在做并发访问检查,使用i变量保存了cusor值,之后if在做了校验,再之后获取到了ArrayList的elementData数组,再次做了并发访问检查,之后修改了下cursor 值,将i的值赋值给了lastRet变量,并且通过下标访问了下数组,最后就返回了。看上去是不是有点找不到重点?让我们抓大放小下,其实去掉并发校验和普通校验,代码逻辑就很清楚了,就会变成如下所示:
private int size;
transient Object[] elementData;
private class Itr implements Iterator<E> {
int cursor;
int lastRet = -1;
public E next() {
int i = cursor;
Object[] elementData = ArrayList.this.elementData;
cursor = i + 1;
return (E) elementData[lastRet = i];
}
// 省略无关代码
}
只有四行代码是不是就个很清晰了?你还可以在画个图:
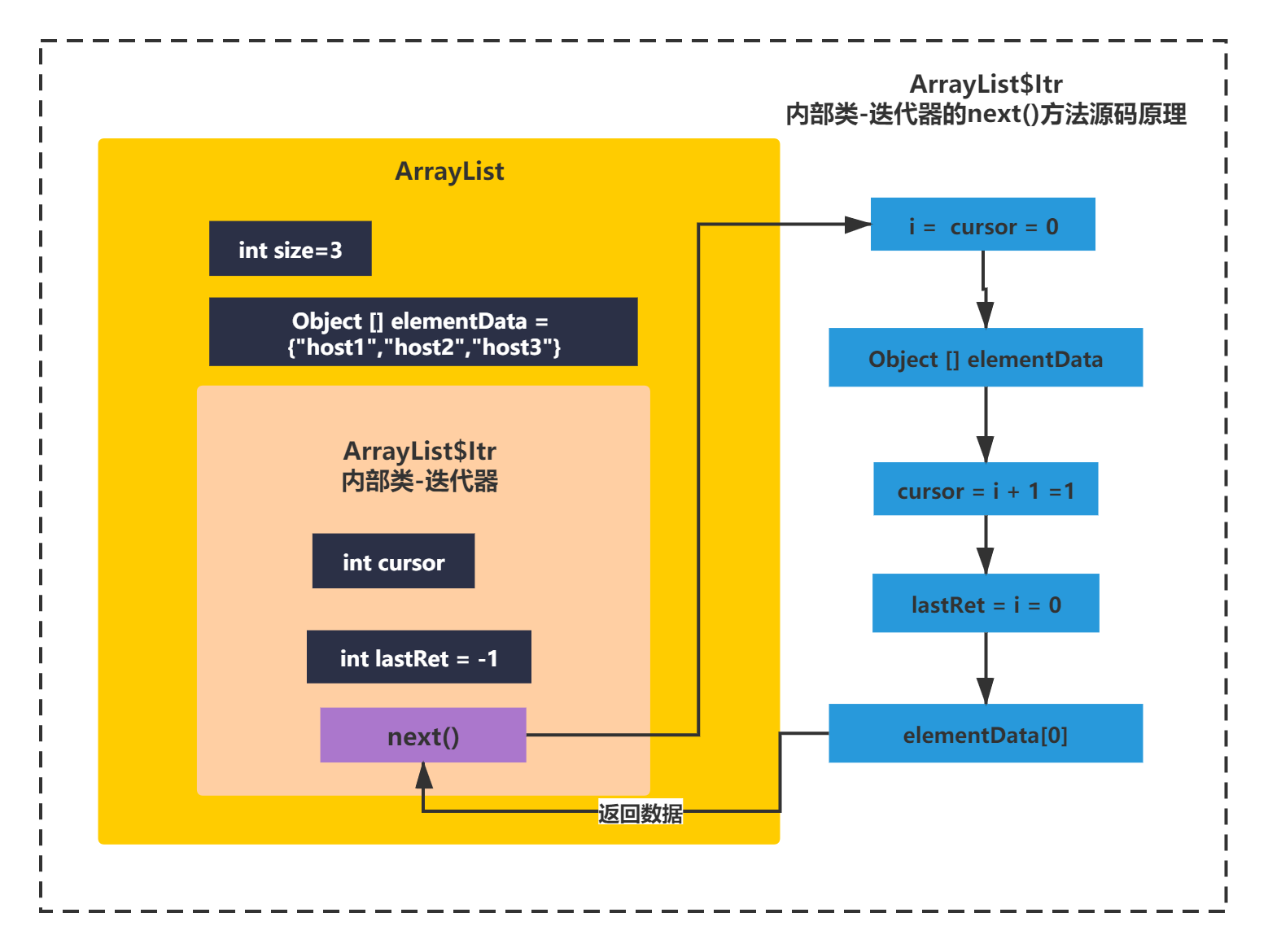
执行过程就如左边的图所示,结果就是如右图所示。通过抓大放小和画图,是不是对源码的思路就清晰很多了?
执行完成一次循环后,Itr变量如下图所示:
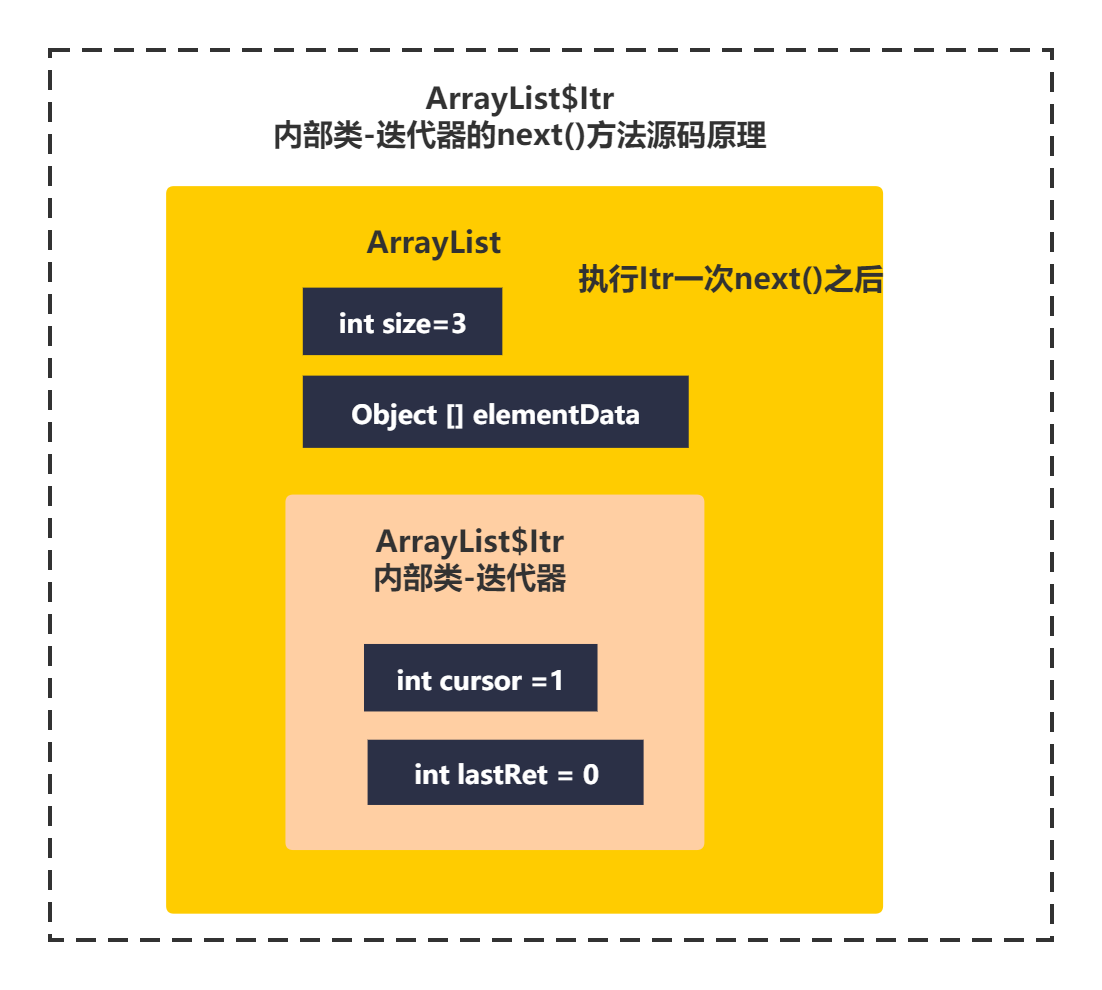
ltr的next()方法本质其实就是通过一个内部cursor变量,每次向后遍历数组时,保存遍历数组的位置,通过数组基本的下标访问元素返回而已,这下你就掌握了ArrayList迭代器的本质或者说是底层原理了吧。
ArrayList竟然有一个优化后的迭代器!
ArrayList竟然还有一个优化后的迭代器!
看过了各种遍历方式的源码,大家不知道有什么感觉?是不是感觉也没有神秘的,其实原理很简单,让你自己写一个类似的功能是不是就可以参考这个思路呢?但是不知道你有没有发现ArrayList还有一个迭代器叫做ListItr的内部类,它优势做什么的呢?
直接可以看下源码:
private class ListItr extends Itr implements ListIterator<E> {
ListItr(int index) {
super();
cursor = index;
}
public boolean hasPrevious() {
return cursor != 0;
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor - 1;
}
@SuppressWarnings("unchecked")
public E previous() {
checkForComodification();
int i = cursor - 1;
if (i < 0)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i;
return (E) elementData[lastRet = i];
}
// 省略无关代码
}
从可以发现它继承了Itr这个类,之后你可以根据方法名字连蒙带猜下,可以猜到它只是实现了向前遍历的功能而已,因为正常情况的迭代器是只能向后迭代,不能向前访问的。但是你可以通过这个ListItr迭代器实现向前访问。比如:
public static void main(String[] args) {
List<String> hostList = new ArrayList<>(3);
hostList.add("host1");
hostList.add("host2");
hostList.add("host3");
//方法3
for (ListIterator<String> iterator = hostList.listIterator(); iterator.hasNext();) {
System.out.println(iterator.next());
System.out.println(iterator.next());
System.out.println(iterator.previous());
break;
}
}
结果会输出如下:
host1
host2
host2
其实这是一个优化后的迭代器,可以向前向后移动cursor,previous()源码逻辑和next()向后移动没什么区别。你到这里就可以总结下:
1. ArrayList有两个迭代器Itr和ListItr,一个可以向后迭代,一个可以既向前又向后迭代访问ArrayList。(其实ArrayList父类AbstractList有2个通用的迭代器,和这个原理是一样的,大家有兴趣可以去看看,如果子类没有自定义自己的迭代器,会使用父类的迭代器。)
2. 这两个迭代器不是并发安全的,如果有别的线程修改modCount,通过fail-fast机制,迭代访问会抛出ConcurrentModificationException,并发修改的异常,中断迭代。
3. 遍历List的思想万变不离其宗,主要就是通过for循环+下标的方式或者指针移动的两种方式实现思路而已。
ArrayList的高级方法探索
ArrayList的高级方法探索
最后你还需要来看下ArrayList的一些高级方法的源码,这里建议你看下它内部提供的toArray方法、subList方法的源码。至于其他的addAll()、indexof()之类的方法大家可以自行去看下。这里主要看下toArray和subList相关的内部类和方法,它们主要有如下脉络:
可以先看下toArray方法的源码:
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}}
public <T> T[] toArray(T[] a) {
if (a.length < size)
// Make a new array of a's runtime type, but my contents:
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}
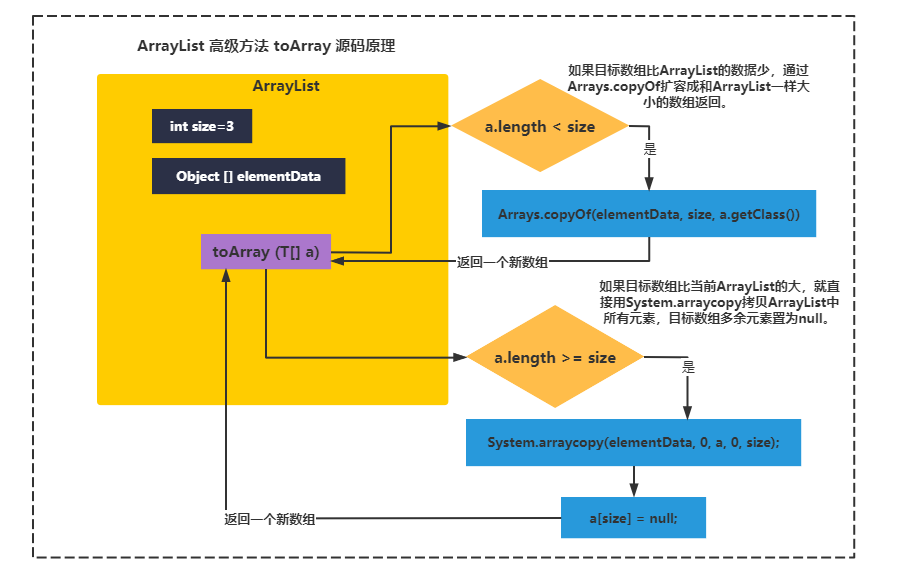
第一个toArray方法的源码,底层直接使用了Arrays.copyOf。你应该知道它底层其实就是使用System.arraycopy方法,拷贝的元素个数是size个,也就是全部元素到一个copy数组中,之后就直接返回了。
第二个T[]toArray(T[] a),需要你传递一个目标数组,它内部有两个if判断,根据目标数组大小,拷贝元素。
-
如果目标数组比ArrayList的数据少,通过Arrays.copyOf扩容成和ArrayList一样大小的数组返回。
-
如果目标数组比当前ArrayList的大,就直接用System.arraycopy拷贝ArrayList中所有元素,目标数组多余元素置为null。
toArray方法本质就是使用System.arraycopy从ArrayList的Obeject数组拷贝元素到新数组。
原理图如下:
之后我们再看下subList方法,可以先写个demo体验下:
public static void main(String[] args) {
List<String> hostList = new ArrayList<>(3);
hostList.add("host1");
hostList.add("host2");
hostList.add("host3");
List<String> subList = hostList.subList(1,2);
System.out.println(subList);
System.out.println(hostList);
subList.set(0, "host4");
System.out.println(subList);
System.out.println(hostList);
}

为什么呢?可以看源码来找下原因。这就是阅读源码的好处之一。因为很多时候当你线上遇到技术问题的时候,你对源码很熟悉,就能很快定位问题原因,解决问题。当你技术调研的时候,选型后,最好要摸下你选的技术的源码,当使用除了问题你也能hold住,是不是?
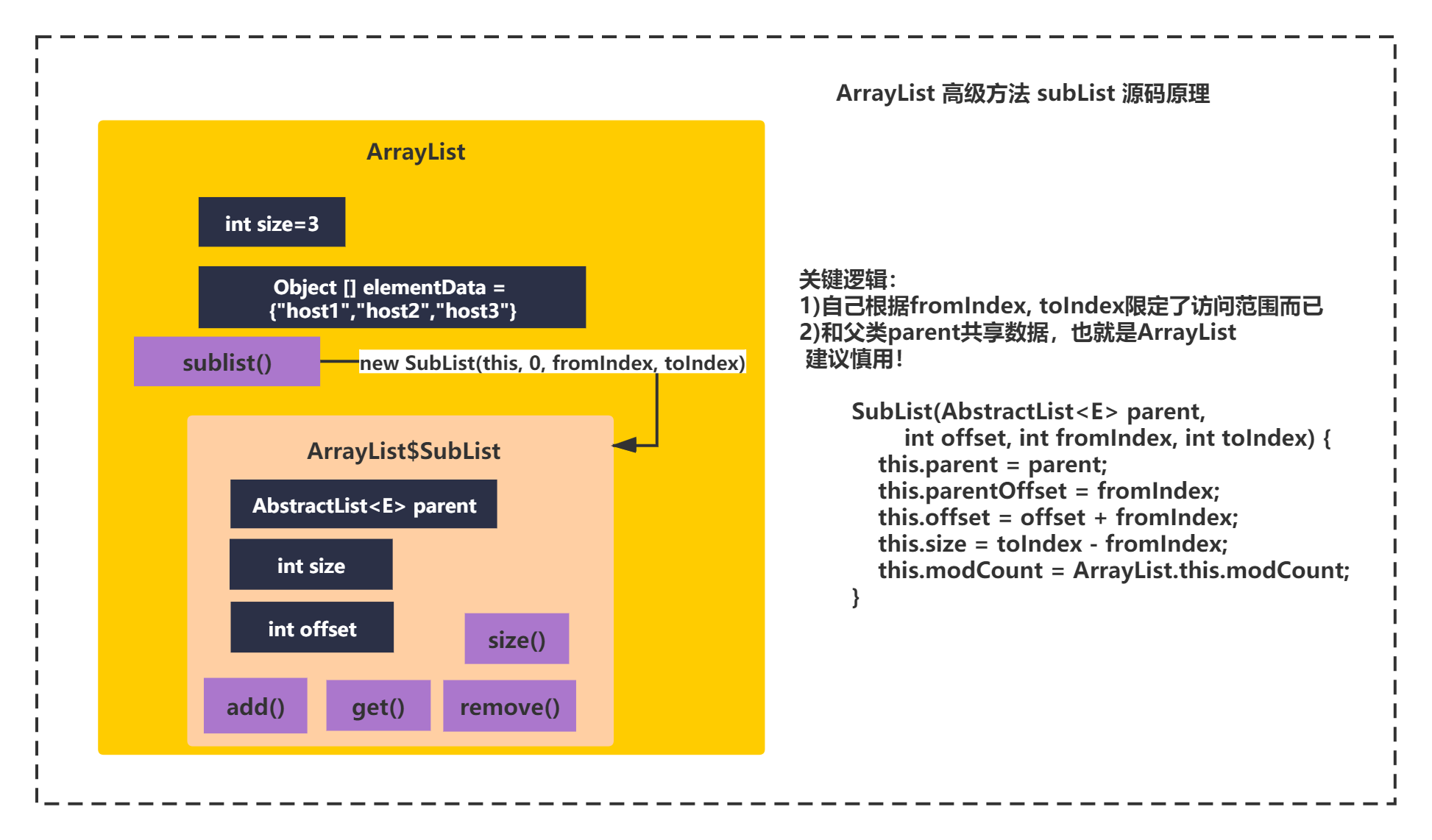
subList的源码如下:
public List<E> subList(int fromIndex, int toIndex) {
subListRangeCheck(fromIndex, toIndex, size);
return new SubList(this, 0, fromIndex, toIndex);
}
和Itr类似,创建了一个内部类SubList的对象。继续点进去看下:
private class SubList extends AbstractList<E> implements RandomAccess {
private final AbstractList<E> parent;
private final int parentOffset;
private final int offset;
int size;
SubList(AbstractList<E> parent,
int offset, int fromIndex, int toIndex) {
this.parent = parent;
this.parentOffset = fromIndex;
this.offset = offset + fromIndex;
this.size = toIndex - fromIndex;
this.modCount = ArrayList.this.modCount;
}
public E set(int index, E e) {
rangeCheck(index);
checkForComodification();
E oldValue = ArrayList.this.elementData(offset + index);
ArrayList.this.elementData[offset + index] = e;
return oldValue;
}
public E get(int index) {
rangeCheck(index);
checkForComodification();
return ArrayList.this.elementData(offset + index);
}
public int size() {
checkForComodification();
return this.size;
}
public void add(int index, E e) {
rangeCheckForAdd(index);
checkForComodification();
parent.add(parentOffset + index, e);
this.modCount = parent.modCount;
this.size++;
}
public E remove(int index) {
rangeCheck(index);
checkForComodification();
E result = parent.remove(parentOffset + index);
this.modCount = parent.modCount;
this.size--;
return result;
}
//省略其他方法
}
可以看出来在构造函数的传入了this, new SubList(this, 0, fromIndex, toIndex);而这个this就是ArrayList创建的对象本身,将this赋值给了Sublist的一个变量:private final AbstractList
那最终意思不就是说SubList和ArrayList共用了通过Object[]数组的数据么,所以当修改的时候都会变化。这是你使用subList一定要要注意的。
源码原理图如下所示:
到这里,ArrayList的源码你应该掌握了大部分了,但是记住还是那句话,重要的不是知识和技能本身,你更应该需学会的是看源码的思想和技巧,解决问题的思路和方法。
ArrayList的小结
ArrayList小结
对了这里,附加一个小结,总结也是非常重要的思想。后面我会逐渐讲到。学完ArrayList你如果已经掌握了如下内容,就非常好了。
知识和技能
- ArrayList底层数据结构是Objec[]数组,优点是便于随机访问,常用语向尾部添加元素后,遍历访问。缺点是频繁扩容或者中间增加数据,删除数据会造成拷贝,影响性能。
- ArrayList默认初始化大小为0,第一次添加元素时,大小初始为10。
- ArrayList第一次添加就会产生扩容,为10,之后每次扩容大小为原来的1.5倍。内部通过右移1位进行扩容大小的计算的。
- ArrayList add元素到尾部发生的扩容时或add元素到某个位置时,又或者删除元素时,会发生数组拷贝,底层通过system.copyOf实现拷贝功能。
- ArrayList不是线程安全的,多线程操作,在遍历和removeIf等时候,会触发fail-fast机制,通过modCount来实现的。
- 掌握了基本的基本方法和高级方法toArray、subList、迭代器Itr、ListItr等底层源码的原理
观念和思想
- 学会了先脉络后细节、抓大放小、连蒙带猜等阅读源码的思想
- 学会了画图、举例子分析问题的方法
- 有了成长比成功更重要、榜样比说服力更重要、改变自己比改变别人更重要、借力比努力更重要的观念
金句甜点
金句甜点
除了今天知识,技能的成长,给大家带来一个金句甜点,结束我今天的分享:借力比努力更重要。
一个人的努力固然很重要,但是很多时候借力更重要。就像有句名言所说:站在巨人的肩膀上。这个不是真的站在某个人的肩膀上,而是指的前人的智慧和经验上很重要。就比如有一次我参加公司的晋升演讲,自己做好了PPT,还练习了几次,觉得肯定没有问题了,就直接参加了晋升演讲评审。结果,很不幸的是,PPT右下角的公司log是去年的,公司已经更换了品牌log,最后一页的致谢的PPT,公司名称也写错了。导致有一位评审支出,后来我才知道他是人力部门的HR总监。很遗憾的由于错失了她这一票,刚好导致我落选了。其实演讲前,我的Leader跟我说过,写好了PPT要给他看一下,我当初觉得完全没必要。其实就是犯了很大一个错误,因为我的Leader的经验比我丰富,他晋升过很多次,汇报过很多次,在这方便很有见地,我没有借他的力,导致了这次失败。所以我吸取教训,下次晋升时,找了Leader,他帮我一页一页的过PPT,最终顺利的通过了晋升。
这个故事其实就告诉我们,借力比努力更重要。你一定要向比你有经验的人请教,他就是你的老师,这就是一种借力。当然选一个平台也是借力,就像大家通过成长记来成长自己,站在我的经验上少走弯路是不是一样在借力。所以欢迎大家继续关注成长记。
最后,你可以阅读完源码后,在茶余饭后的时候问问同事或同学,你也可以分享下,讲给他听听。
欢迎大家在评论区留言和我交流。
(声明:JDK源码成长记基于JDK 1.8版本,部分章节会提到旧版本特点)
本文由博客群发一文多发等运营工具平台 OpenWrite 发布
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


