
计算虚拟化根据操作系统所组成的设备类型包含 CPU 虚拟化、内存虚拟化和 IO 虚拟化。
先简单介绍一下 KVM再说一下cpu、内存和IO是怎样虚拟化的。
KVM
KVM,全称是 Kernel-based Virtual Machine(基于内核的虚拟机),是一种典型 II 型全虚拟化,它之所以叫做基于内核的虚拟机,是因为 KVM 本身是一个 Linux 内核模块,当一个安装有 Linux 系统的物理机安装了这个模块以后,就变成了 Hypervisor(VMM),而且还不会影响原先在该 Linux 上运行的其它应用程序,而且每个虚拟机都是进程,可以直接使用 kill 命令杀掉。 一个普通的 Linux 安装了 KVM 模块以后,会增加三种运行模式:
User Mode:用户空间,此模式下运行的主要是 QEMU,它用来为虚拟机模拟执行 I/O 类的操作请求;
Kernel Mode:内核空间,在此模式下可以真正的操作硬件,当 Guest OS 执行 I/O 类操作或特权指令操作时需要向用户模式提交请求,然后由用户模式再次发起 硬件操作请求给内核模式从而真正操作硬件。
KVM 体系一般包括三部分:KVM 内核模块、QEMU 和管理工具,其中 KVM 内核模块和 QEMU 是 KVM 的核心组件,具体如下图所示。
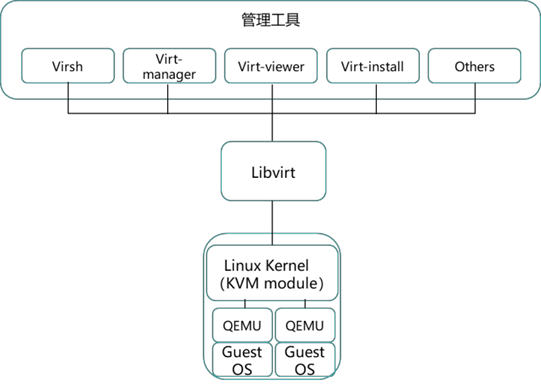
除了 KVM,其它的虚拟化产品基本几乎都是类似的架构。
KVM 内核模块是 KVM 虚拟机的核心部分,其主要功能是初始化 CPU 硬件,打开虚拟化模 式,然后将 Geust Machine 运行在虚拟机模式下,并对虚拟客户机的运行提供一定的支持。
KVM 模块中,实现虚拟化功能的是 kvm.ko,还包括一个和处理器强相关的模块如 kvm-intel.ko 或 kvm-amd.ko,KVM 本身不能实现任何模拟功能,它仅仅是提供了一个/dev/kvm 接口,这个接口可被宿主机用来主要负责 vCPU 的创建、虚拟内存的地址空间分配、vCPU 寄存 器的读写以及 vCPU 的运行。所以 kvm.ko 只提供了 CPU 和内存的虚拟化,但是一个虚拟机除 了 CPU 和内存外,还需要网卡、硬盘等其它的 IO 设备,这时候就需要另外一个组件——
QEMU 了,KVM 核心模块和 QEMU 在一起才能构成一个完整的虚拟化技术。
其实 QEMU 原本不是 KVM 的一部分,它是一个通用的开源的使用纯软件来实现的虚拟 化的模拟器,Guest OS 以为自己在和硬件进行交互,其实真正交互的是 QEMU,然后在通过 QEMU 去和硬件交互,这就意味着所有的和硬件交互都需要经过 QEMU,所以使用 QEMU 进 行模拟的性能比较低。QMEU 本身可以模拟 CPU 和内存,在 KVM 中,只使用 QEMU 来模拟 IO 设备,KVM 的开发者将其进行了改造,形成了 QEMU-KVM。
在 QEMU-KVM 中,KVM 运行在内核空间,QEMU 运行在用户空间,Guest OS 下发指令 的时候,和 CPU 和内存相关的指令会通过 QEMU-KVM 中的/ioctl 调用 /dev/kvm,从而将这 部分指令的部分交给内核模块来做,从 QEMU 的角度来看,这样做也可以提高虚拟化加速。其 它的 IO 操作则由 QEMU-KVM 中的 QEMU 部分实现,KVM 加上 QEMU 后就是完整意义上的 虚拟化。
除了进行各种设备的虚拟化外,QEMU-KVM 还提供了原生的工具可以对虚拟机进行创建、 修改和删除等管理,然而,Libvirt 是目前使用最为广泛的对 KVM 虚拟机进行管理的工具和 API。
Libvirt 也是一个开源项目,它是一个非常强大的管理工具,被管理的虚拟化平台可以是 KVM,也可以是 Xen 或者 VMware 以及 Hyper-V 等等。Libvirt 是一台由 C 语言开发的 API, 其它的语言,比如 Java、Python、Perl 等,可以通过调用 Libvirt 的 API 去管理各个虚拟化平 台。Libvirt 被很多的应用用到,除了自己本身的 virsh 命令集外,Virt-manager、Virt- viewer、Virt-install 都可以通过 Libvirt 管理 KVM 虚拟机。
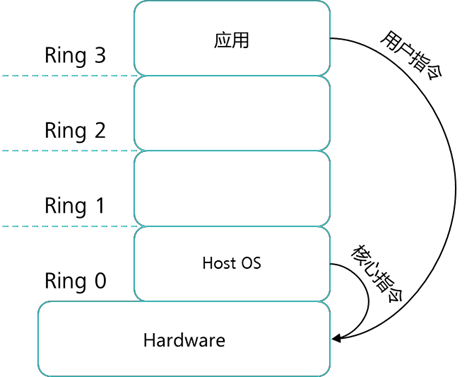
在讲 CPU 虚拟化前,我们先简单介绍一下 CPU 的分级保护域,在这种保护模式中,CPU 被分成 4 个环——Ring0、Ring1、Ring2 和 Ring3,Ring0 的权限最高,Ring1 次之,Ring2 再次之,Ring3 最低。Ring0 的权限可以直接操作硬件,一般只有操作系统和驱动会允许拥有此 权限。Ring3 的权限最低,所有的程序都可以拥有此权限。为了保护计算机,一些危险的指令只 能由操作系统执行,防止一些恶意软件随意地调用硬件资源,比如某个程序需要开启摄像头就必须向 Ring0 的驱动程序请求开启,否则会被拒绝此类操作。
在普通主机上的操作系统所发出的指令分为两种类型:特权指令和普通指令。
- 特权指令:是指用于操作和管理关键系统资源的指令,这些指令只有在最高特权级 上才能够运行,即必须在 Ring 0 级别上才能运行的指令。
- 普通指令:与特权指令相对的是普通指令,这些指令在 CPU 普通权限级别上就能够 运行,即在 Ring 3 级别上就可以运行的指令。
在虚拟化环境下,还有一种特殊指令被称为敏感指令。敏感指令是指修改虚拟机的运行模式或宿主机状态的指令,也就是说是将 Guest OS 中原本需要在 Ring 0 模式下才能运行的特权指 令剥夺特权后,交给 VMM 所执行的指令。
虚拟化技术首先出现在 IBM 大型机上,大型机如何解决 CPU 共享问题的呢?首先我们先了 解一下大型机的 CPU 虚拟化方式。大型机 CPU 虚拟化采取的是“特权解除(Privilege deprivileging)”和“陷入模拟(Trap-and-Emulation)”方法,这种方法也被称为经典虚拟化方 式。它的基本原理是,将 Guest OS 运行在非特权级(即特权解除),而将 VMM 运行于最高特 权级(即完全控制系统资源)。
这个时候就出现了一个问题:如果虚拟机 Guest OS 发出特权操作指令怎么执行呢?因为所有虚拟机的系统都被解除了特权,于是“陷入模拟”就发挥作用了,它解除了 Guest OS 的特权后,Guest OS 的大部分指令仍可以在硬件上直接运行,只有当执行到特权指令时,才会陷入到 VMM 模拟执行(陷入-模拟)。由 VMM 代替虚拟机向真正的硬件 CPU 发出特权操作指 令。
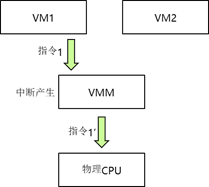
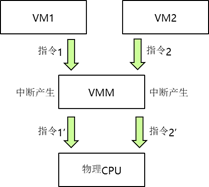
CPU 虚拟化经典方法结合原始操作系统具有的定时器中断机制,就完美解决了 CPU 虚拟化 的问题。如虚拟机 1 发送特权指令 1 到虚拟机监视器 VMM,此时触发中断,虚拟机监视器 VMM 会对虚拟机 1 发送的特权指令 1 陷入到虚拟机监视器 VMM 中进行模拟,再转换成 CPU 的特权指令 1’,虚拟机监视器 VMM 根据调度机制调度到硬件 CPU 上执行,并返回结果给 VM1,如下左图。当虚拟机 1 和虚拟机 2 同时发送特权指令到虚拟机监视器 VMM 时,指令 都被陷入模拟,虚拟机监视器 VMM 调度机制进行统一调度。首先执行指令 1’,然后再执行指 令 2’如下右图 。于是采用定时器中断机制以及特权解除—陷入模拟这些方法成功实现了 CPU 的虚拟化功能。
--------------------------------------------------------------------------------------
那为什么需要中断机制呢?CPU 在程序运行中系统外部、系统内部或者现行程序本身若出 现紧急事件,CPU 立即中止现行程序的运行,自动转入相应的处理程序(中断服务程序),待处 理完后,再返回原来的程序运行,这整个过程称为程序中断。例如你正在看视频时,QQ 突然有 信息弹出,在整个过程中就会触发中断机制。CPU 就会暂停视频播放进程,而专区执行 QQ 进 程。CPU 在处理完成 QQ 进程操作后,继续执行视频播放进程。当然,这个中断时间非常短 暂,用户是无感知的。
随着 x86 主机性能越来越强大,如何将虚拟化技术应用到 x86 架构成为实现 x86 服务器虚 拟化的主要问题。这个时候,人们自然而然想到曾经使用到大型机上的 CPU 虚拟化技术。那么 大型机 CPU 虚拟化所使用的经典虚拟化方法能否移植到 x86 服务器上呢?这个问题答案却是否 定的。这又是为什么呢?要回答这个问题,我们就需要了解 x86 架构的 CPU 和大型机 CPU 的 不同之处。
大型机(包括后来发展的小型机)是 PowerPC 架构,即精简指令集 RISC 计算机架构。 RISC 架构的 CPU 指令集中,虚拟机特有的敏感指令是完全包括在特权指令中的,如下右图所 示。在虚拟机操作系统解除特权后,特权指令和敏感指令都可被正常陷入-模拟并执行,因为特 权指令包含敏感指令,所以 RISC 架构的 CPU 采用特权解除和陷入模拟是没有问题的。但是 x86 架构的 CPU 指令集是不同于 RISC 架构的 CISC 架构,如下图所示。
 |
| 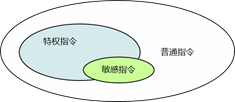
在上图中可以看到 CISC 架构的 CPU 指令集的特权指令和敏感指令并不完全重合,具体来 说,基于 x86 的 CISC 指令集有 19 条敏感指令不属于特权指令的范畴,这部分敏感指令运行在 CPU 的 Ring 1 用户态上。这会带来什么问题呢?显然,当虚拟机发出这 19 条敏感指令时,由 于指令不属于特权指令,因而这些敏感指令不能陷入-模拟被虚拟机监视器(VMM)捕获,因此 x86 无法使用“解除特权”“陷入-模拟”经典的虚拟化技术方式实现 X86 架构的虚拟化。这样的 问题被称为虚拟化漏洞问题。既然基于大型机的 CPU 虚拟化方案无法直接移植到 x86 平台上, 那么 x86 应该采用什么方式实现 CPU 虚拟化呢?
聪明的 IT 架构师想出了解决这个问题的方法,而且还是三种方法。它们分别是:全虚拟 化、半虚拟化以及硬件厂商提出的硬件辅助虚拟化。
CPU全虚拟化解决方案
经典虚拟化方案不适合 x86 架构的 CPU,其根本原因就在于那 19 条超出特权指令的敏感指 令,如何可以识别出这些敏感指令,并使其可以被 VMM 陷入——模拟,则 CPU 虚拟化就可以 被解决。但是如何识别出这 19 条指令呢?
有一种类似于“宁可错杀三千,绝不放过一个”的思路,也就是说将所有虚拟机发出的操作 系统请求转发到虚拟机监视器(VMM),虚拟机监视器对请求进行二进制翻译(Binary Translation),如果发现是特权指令或敏感指令,则陷入到 VMM 模拟执行,然后调度到 CPU 特权级别上执行;如果只是应用程序指令则直接在 CPU 非特权级别上执行。这种方法由于需要 过滤所有虚拟机发出的请求指令,因而被称为全虚拟化方式。全虚拟化的实现方式如下图。
全虚拟化方案最早是由 Vmware 提出并实现,运行时虚拟机监视器 VMM 对虚拟机操作系 统 Guest OS 二进制代码进行翻译,不修改虚拟机操作系统,虚拟机的可移植性和兼容性较强,但二进制翻译会带来虚拟机监视器(VMM)性能的开销。全虚拟化方式的优点是:不修改虚拟机操作系统,虚拟机的可移植性和兼容性较强,支持广泛的操作系统;但缺点是运行时修改 Guest OS 二进制代码,性能损耗较大,并且引入了新的复杂性,导致虚拟机监视器(VMM) 开发难度较大。正是因为全虚拟化具有上述的缺点,因此 Xen 提出半虚拟化解决方案。
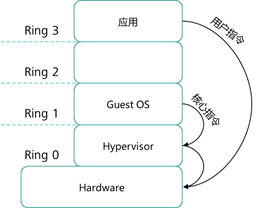 |
| 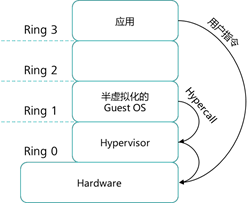
半虚拟化示意图 全虚拟化示意图
CPU半虚拟化解决方案
虚拟化漏洞的问题来源于 19 条敏感指令,如果我们可以修改虚拟机操作系统 Guest OS 规 避虚拟化漏洞,则问题就容易解决了。
修改虚拟机操作系统 Guest OS,让虚拟机系统 Guest OS 能够意识到自己是被虚拟化的, 虚拟机操作系统会通过“超级调用”(Hypercall)用 Hypervisor 层来替换虚拟化中的敏感指 令,从而实现虚拟化,而其它应用程序等非敏感或特权请求直接在 CPU 非特权级别上执行。半 虚拟化如上图二所示。半虚拟化所具有的优点是:半虚拟化中的 Guest OS 可以同时能支持多个 不同的操作系统.,虚拟化提供了与原始系统相近的性能。但缺点是:半虚拟化中的 Host OS 只 有针对开源的系统才能支持被修改,如 Linux,而对于未开源的诸如 Windows 系统,则无法实 现半虚拟化。此外,被修改过的虚拟机操作系统 Guest OS 可移植性较差。
CPU硬件辅助虚拟化解决方案
虚拟化漏洞问题的解决,无论全虚拟还是半虚拟,都默认一个前提,即物理硬件是不具备虚拟化识别功能的,因此必须识别出这 19 条敏感指令,并通过虚拟化监视器 VMM 进行陷入——模拟。如果物理 CPU 直接支持虚拟化功能,并且可以识别敏感指令,那么 CPU 虚拟化方式就将发生革命性的变革。
幸运的是,目前主流的 x86 主机的 CPU 都支持硬件虚拟化技术,即 Intel 推出 VT-x 的 CPU,AMD 也推出了 AMD-V 的 CPU。Intel Virtualization Technology(VT-x)和 AMD 的 AMD-V,这两种技术都为 CPU 增加了新的执行模式 root 模式,可以让虚拟化监视器 VMM 运 行在 root 模式下,而 root 模式位于 CPU 指令级别 Ring 0 的下面。特权和敏感指令自动在 Hypervisor 上执行,从而无需全虚拟或半虚拟化技术。这种通过硬件辅助虚拟化解决虚拟化漏 洞,简化 VMM 软件,消除了半虚拟化和二进制翻译的方法,被称为 CPU 的硬件辅助虚拟化技术。但是需要在bios里把inter vt-x特性打开,不打开则不支持虚拟化特性。硬件辅助虚拟化技术如下图所示。
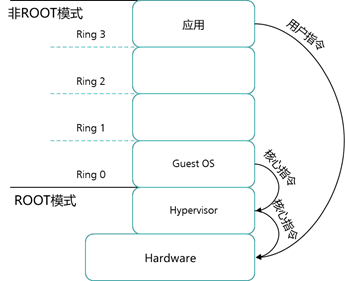
硬件辅助虚拟化
内存虚拟化
CPU 实现了虚拟化之后,与 CPU 关系极为密切的硬件——内存也将发生巨大的变化。为什 么 CPU 虚拟化后会导致内存虚拟化的出现呢?
随着 CPU 虚拟化的出现应用,运行在 VMM 层之上的虚拟机取代了物理主机,成为承载业 务和应用的载体。并且在一台物理主机之上有多台虚拟机同时运行着。那么问题就出来了,物理 主机通常只有一根或几根内存条,面对多个虚拟机对内存的需求,该如何分配内存资源呢?显然,解决问题的办法还是虚拟化技术,因此内存虚拟化技术就出现了。内存虚拟化所遇到的一个问题就是,如何分配内存地址空间呢?因为通常情况下物理主机在使用内存地址空间时,都按照 如下两点进行:
- 内存地址都是从物理地址 0 开始的
- 内存地址空间都是连续分配的 但引入虚拟化后显然就出现了问题:首先是要求内存地址空间都从物理地址 0 开始,显然物理地址为 0 的内存地址空间只有一个,无法同时满足所有虚拟机内存使用都要从 0 开始的要求;
其次,地址连续分配问题。即使可以为虚拟机分配连续的物理地址,但是内存使用效率不高,缺 乏灵活性。
解决内存共享问题的思路就在于引入内存虚拟化技术。内存虚拟化就是把物理机的真实物理 内存统一管理,包装成多份虚拟的内存给若干虚拟机使用。内存虚拟化技术的核心在于引入一层 新的地址空间——客户机物理地址空间,客户机(Guest)以为自己运行在真实的物理地址空间 中,实际上它是通过 VMM 访问真实的物理地址的,在 VMM 中保存客户机地址空间和物理机 地址空间之间的映射表,如下图所示。
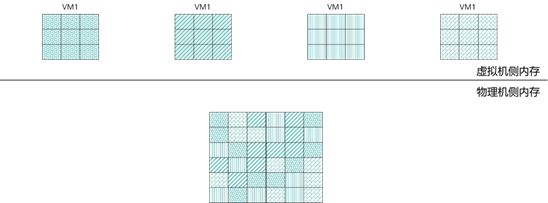
内存虚拟化的内存地址转换涉及到三种内存地址,即虚拟机内存地址(Virtual Memory Address,即 VA)、物理内存地址(Physical Memory Address,即 PA)和机器内存地址(Machine Memory Address,即 MA)。为了在物理主机上能够运行多个虚拟机,需要实现VA(虚拟内存)→PA(物理内存)→MA(机器内存)直接的地址转换。虚拟机 Guest OS 控 制虚拟地址到客户内存物理地址的映射 (VA→PA),但是虚拟机 Guest OS 不能直接访问实际 机器内存,因此 Hypervisor 需要负责映射客户物理内存到实际机器内存(PA→MA)。
注:这个地方可能有人要问 MA 和 PA 的区别,比如一台服务器一共有 16 根 16G 的内存 条,那么它的 PA 为 256G,而 MA 为 16 根分布在不同内存槽位的内存条。
内存全虚拟化
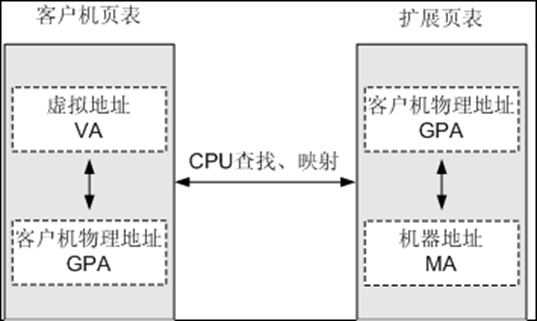
通过使用影子页表(Shadow Page Table)实现虚拟化。VMM为每个Guest都维护一个影子页表,影子页表维护虚拟地址(VA)到机器地址(MA)的映射关系。而Guest页表维护VA到客户机物理地址(GPA)的映射关系。当VMM捕获到Guest页表的修改后,VMM会查找负责GPA到MA映射的P2M页表或者哈希函数,找到与该GPA对应的MA,再将MA填充到真正在硬件上起作用的影子页表,从而形成VA到MA的映射关系。而Guest的页表则无需变动。如下图所示。

内存半虚拟化
通过使用页表写入法实现虚拟化。Guest OS在创建一个新的页表时,会向VMM注册该页表。之后在Guest运行的时候,VMM将不断地管理和维护这个表,使Guest上面的程序能直接访问到合适的地址。
内存硬件辅助虚拟化
通过扩展页表EPT(Extended Page Table)实现虚拟化。EPT通过使用硬件技术,使其能在原有的页表的基础上,增加一个EPT页表,用于记录GPA到MA的映射关系。VMM预先把EPT页表设置到CPU中。Guest修改Guest页表,无需VMM干预。地址转换时,CPU自动查找两张页表完成Guest虚拟地址到机器地址的转换,从而降低整个内存虚拟化所需的开销。如下图所示。
I/O 虚拟化
由于计算虚拟化的出现,物理服务器上会创建出许许多多的虚拟机,并且每台虚拟机都需要 访问物理主机的 IO 设备。但 I/O 设备的数量毕竟是有限的,为了满足多个虚拟机共同使用 I/O 设备的需求,就需要虚拟化监视器 VMM 参与。VMM 用于截获虚拟机对 I/O 设备的访问请求, 再通过软件去模拟真实的 I/O 设备,进而响应 I/O 请求。从而让多个虚拟机访问有限的 I/O 资 源。实现 I/O 虚拟化的方式主要有三种:全虚拟化、半虚拟化和硬件辅助虚拟化,其中硬件辅助虚拟化技术是目前 I/O 虚拟化的主流技术。
IO全虚拟化
全虚拟化的实现原理是,通过 VMM 为虚拟机模拟出一个与真实设备类似 的虚拟 I/O 设备,当虚拟机对 I/O 设备发起 I/O 请求时,VMM 截获虚拟机下发的 I/O 访问请 求,再由 VMM 将真实的访问请求发送到物理设备进行处理。这种虚拟化方式的优点在于:虚拟 机无论使用任何类型的操作系统,操作系统都不需要为 I/O 虚拟化做任何修改,就可以让多个虚 拟机直接使用物理服务器的 I/O 设备。但这种方式的缺陷也在于,VMM 需要实时截获每个虚拟 机下发的 I/O 请求,截获请求后模拟到真实的 I/O 设备中。实时监控和模拟的操作都是通过CPU 运行软件程序来实现的,因此会对服务器带来较严重的性能损耗。
IO半虚拟化
半虚拟化方式与全虚拟化方式的明显区别在于,它需要建立一个特权级别的 虚拟机,即特权虚拟机。半虚拟化方式要求各个虚拟机运行前端驱动程序,当需要访问 I/O 设备 时,虚拟机通过前端驱动程序把 I/O 请求发送给特权虚拟机,由特权虚拟机的后端驱动收集每个 虚拟机所发出的 I/O 请求,再由后端驱动对多个 I/O 请求进行分时分通道处理。特权虚拟机运行真实的物理 I/O 设备驱动,将 I/O 请求发送给物理 I/O 设备,I/O 设备处理完成后再将结果返回给虚拟机。半虚拟化方式的优点在于,主动让虚拟机把 I/O 请求发送给特权虚拟机,再由特权虚 拟机访问真实的 I/O 设备。这就减少了 VMM 的性能损耗。但这种方式也有一个缺陷,即需要修 改虚拟机操作系统,改变操作系统对自身 I/O 请求的处理方式,将 I/O 请求全部发给特权虚拟机 处理。这就要求虚拟机操作系统是属于可以被修改的类型(通常都是 Linux 类型)。XEN就是典型的IO半虚拟化,如下图 所示。
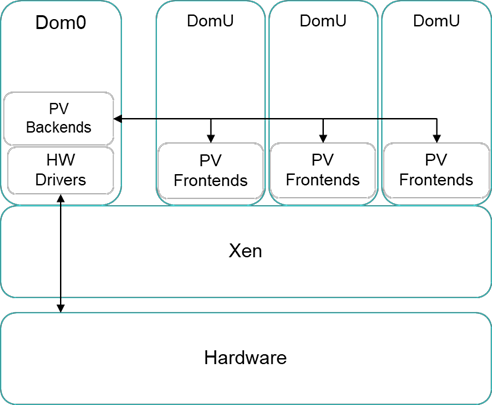
Xen 架构示意图
在上图中,Domain 0 就是特权虚拟机,Domain U 则为用户虚拟机。所有用户虚拟机 的设备信息保存在特权虚拟机 Domain0 的 XenSToRe 中,用户虚拟机中的 XenBus (为 Xen 开 发的半虚拟化驱动)通过与 Domain0 的 XenSToRe 通信,获取设备信息,加载设备对应的前端 驱动程序。当用户虚拟机有 I/O 请求时,前端设备驱动将数据通过接口全部转发到后端驱动。后 端驱动则对 I/O 请求的数据进行分时分通道进行处理。最终通过 Domain 0 的物理 I/O 设备驱 动,将 I/O 请求发送给物理 I/O 设备。
我们可以举例比较全虚拟化和半虚拟化两种方式,全虚拟化就相当于 VMM 扮演着一个调查员的角色,它需要自己去收集和归纳每一位客户的意见要求;而半虚拟化则相当于准备好了一个 意见收纳箱(即特权虚拟机),然后各个用户自行将意见要求放入收纳箱,VMM 再统一处理这 些意见请求。由于半虚拟化显著减少了 VMM 的性能损耗,因而能获得更好的 I/O 性能。但我们也注意到,全虚拟化和半虚拟化这两种方式都有一个共同的特点,即 I/O 访问处理都需要由VMM 介入,这势必造成虚拟机在访问 I/O 设备时的性能损耗。
前面我们说过,QEMU 是一个软件实现 IO 虚拟化的模拟工具,性能较差,例如,如果使用 QEMU 模拟一个 Windows 虚拟机的网卡,我们在系统上看到的该网卡的速率仅为 100M,有 时候一些应用对网卡速率有要求时,就不能再使用 QEMU 了,我们需要引入一个新的技术,它 就是 Virtio,是用了 Virtio,同样是网卡,在 Windows 虚拟化上,该网卡的速率可以提升到 10G。
我们先了解一下,如果没有 Virtio 时,虚拟机磁盘操作如何实现:

默认 I/O 操作流程
1 、虚拟机中的磁盘设备发起一次 IO 操作请求;
2 、KVM 模块中的 I/O Trap Code(I/O 捕获程序)将这个 IO 操作请求捕获到,进行 相应的处理,然后将处理后的请求放到 I/O 共享页中;
3 、KVM 模块会通知 QEMU,告诉它有新的 I/O 操作请求放到了共享页中;
4 、QEMU 收到通知后,到共享页中获取该 I/O 操作请求的具体信息;
5 、QEMU 对该请求进行模拟,同时根据 I/O 操作请求的信息调用运行在内核态的设备驱动,去进行真正的 IO 操作;
6 、通过设备驱动去对物理硬件执行真正的 IO 操作;
7 、QEMU 将执行后的结果返回到共享页中,同时通知 KVM 模块已完成了此次的 I/O 操作;
8 、I/O 捕获程序从共享页中将返回的结果读取出来;
9 、I/O 捕获程序将操作结果返回给虚拟机;
10、虚拟机的将结果返回给发起操作的应用程序。
注:注意第 2、3、7 步,其实 KVM 除了捕获和通知,并没有对 I/O 操作做任何的修改,既 然什么都内有修改,那么我们都能不能把这一步去掉呢,所以就开发出了新的 virtio 技术。如果使用 Virtio 的时候,具体的操作流程如下:
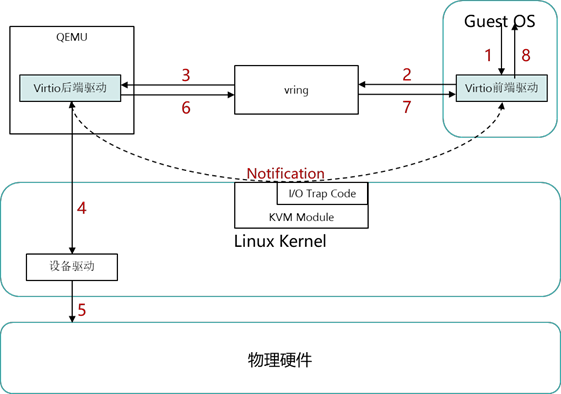 Virtio 下 I/O 操作流程
Virtio 下 I/O 操作流程
1 、第一步也是由虚拟机发起 I/O 操作请求;
2 、第二步的时候和使用默认模型不一样,这个 I/O 操作请求不会经过 I/O 捕获程序, 而是直接以前后端的形式放到环形缓冲区,同时 KVM 模块通知后端驱动;
3 、QEMU 到环形缓冲区获取到操作请求的具体信息;
4 、后端驱动直接调用真实的物理设备驱动进行具体的 I/O 操作;
5 、由真实的设备驱动完成此次操作;
6 、QEMU 将完成结果返回到环形缓冲区,并且由 KVM 模块通知前端驱动;
7 、前端驱动从环形缓冲区获取到此次 I/O 操作的结果;
8 、前端驱动将结果返回给具体发起该操作的应用程序。 通过对以上具体流程的介绍,我们可以得出使用 Virtio 的优点:
- 节省 QEMU 模拟时所需的硬件资源;
- 减少 I/O 请求的路径,提高了虚拟化设备的性能。
Virtio 也存在着一些缺点,有些比较老的或者不常用的设备,无法使用,只能使用 QEMU 方式进行模拟。
所以我们现在的虚拟化一般都叫QEMU-KVM,即QEMU实现IO虚拟化,KVM实现CPU和内存的虚拟化。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!
 客服
客服


