
本文为Thomas Simonini增强学习系列文章笔记或读后感,原文可以直接跳转到medium系列文章。
主要概念为:
Q-Learning,探讨其概念以及用Numpy实现
我们可以将二维游戏想象成平面格子,每个格子代表一个状态,并且对应了不同的动作,例如下图:

Q函数接收状态和动作两个参数并输出Q值,即在一个状态下各种动作各自未来的期望奖励。公式如下:

这里的未来期望奖励,就是当前状态下一直到结束状态(成功或失败)所获取的奖励。
Q-learning算法伪代码:

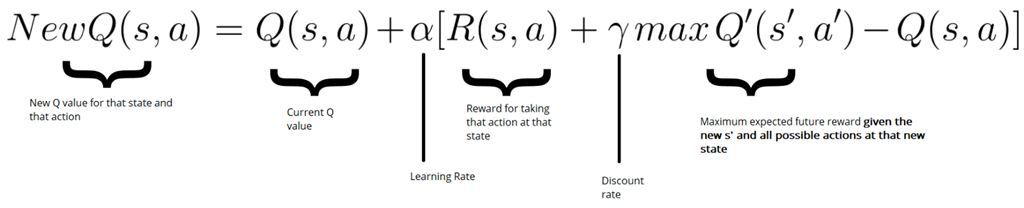
其中,更新Q值为bellman等式,如下描述:

这篇文章总体来说,非常简单,各种步骤也特别详细,告诉了我们如何计算Q-table的算法过程。但是为什么能迭代到最优,并没有给出一个比较明确的证明过程。主要也是因为采用的EE平衡问题,这个过程采用了greedy episolon的启发式算法,每次直接选取的是最大概率的action,而多次重复episode, 其实计算的是对未来的奖励积累的期望。所以从bellman等式到Q(s, a) state-value function 定义如何连接的呢?推导的公式如下:

Numpy具体实现
# -*- coding: utf-8 -*- # pkg need import numpy as np import gym import random import time # step 1. create the environment env = gym.make("Taxi-v2") env.render() # tick and run it to see # this game enviroment could be found detail documented at: # https://gym.openai.com/envs/#toy_text # pick and drop off the passenger right for -20 points, # fail for either one will lose 10 points # every step will decrease 1 points # step 2. create the q-table and initialize it. state_size = env.observation_space.n action_size = env.action_space.n qtable = np.zeros((state_size, action_size)) print("state size: %d, action size: %d" % qtable.shape) # tick and run # step 3. create the hyperparameters total_episodes = 50000 total_test_episodes = 100 max_steps = 99 learning_rate = 0.7 gamma = 0.618 # exploration parameter epsilon = 1.0 # exploration rate max_epsilon = 1.0 # exploration probability at start min_epsilon = 0.01 # minumum exploration probability decay_rate = 0.01 # exponential rate to decay exploration rate # step 4. The Q learning algorithm # 2 For life or until learning is stopped for episode in range(total_episodes): # reset the environment state = env.reset() step = 0 done = False # start the game for step in range(max_steps): # 3 choose an action a in the current world state (s) # first random a number ee_tradeoff = random.uniform(0, 1) # exploitation, taking the biggest Q value for this state if ee_tradeoff > epsilon: action = np.argmax(qtable[state, :]) else: action = env.action_space.sample() # exploration, randomly sample a action # take action and observe the outcome new_state, reward, done, info = env.step(action) # Update the Q(s, a) qtable[state, action] += learning_rate * ( reward + gamma * np.max(qtable[new_state, :]) - qtable[state, action]) # update state state = new_state # if done: finish episode if done: break # reduce epsilon -> we want less and less exploration epsilon = min_epsilon + (max_epsilon - min_epsilon) * np.exp(-decay_rate * episode) print(qtable) # use q table to play taxi def play(env, qtable, show=True, sec=None): state = env.reset() step = 0 done = False total_rewards = 0 for step in range(max_steps): # see agent to play if show: env.render() action = np.argmax(qtable[state, :]) new_state, reward, done, info = env.step(action) total_rewards += reward if done: break if sec: time.sleep(sec) state = new_state return total_rewards # play one test episode play(env, qtable) env.reset() rewards = [] for episode in range(total_test_episodes): total_rewards = play(env, qtable, show=False) rewards.append(total_rewards) env.close() print("Score over time: " + str(sum(rewards) / total_test_episodes))
参考文献:
1. bellman equation to state value function,berkeley的增强学习课程,讲的真详细。
内容来源于网络如有侵权请私信删除
- 还没有人评论,欢迎说说您的想法!



 客服
客服



{kind=link}