
前言
本篇文章主要介绍的关于本人在使用MySql记录笔记的一些使用方法和经验,温馨提示,本文有点长,约1.5w字,几十张图片,建议收藏查看。
一、MySql安装
下载地址:https://dev.mysql.com/downloads/
在安装MySql之前,查看是否以及安装过MySql,如果已经安装,但是不符合要求的话就卸载。
如果是windows安装的话,下载windows的安装包,一路next下去,设置好账号和密码就行了。
1,查找以前是否装有mysql
先输入:
rpm -qa|grep -i mysql
查看是否安装了mysql
2,停止mysql服务、删除之前安装的mysql
输入:
ps -ef|grep mysql
删除命令
输入:
rpm -e –nodeps 包名

如果提示依赖包错误,则使用以下命令尝试
rpm -ev 包名 --nodeps
如果提示错误:error: %preun(xxxxxx) scriptlet failed, exit status 1
则用以下命令尝试:
rpm -e --noscripts 包名
3、查找并删除mysql目录
查找结果如下:
find / -name mysql
删除对应的mysql目录
具体的步骤如图:查找目录并删除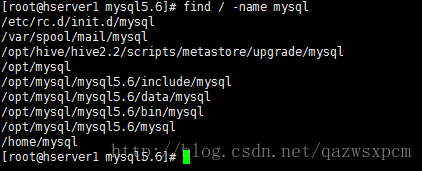
注意:卸载后/etc/my.cnf不会删除,需要进行手工删除
4、再次查找机器是否安装mysql
rpm -qa|grep -i mysql

Mysql有两种安装模式,可自行选择。
1.1 yum安装
首先查看mysql 是否已经安装
输入:
rpm -qa | grep mysql
如果已经安装,想删除的话
输入:
普通删除命令:
rpm -e mysql
强力删除命令:
rpm -e --nodeps mysql
依赖文件也会删除
安装mysql
输入:
yum list mysql-server
如果没有,则通过wget命令下载该包
输入:
wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
下载成功之后,再输入命令安装
yum install mysql-server
在安装过程中遇到选择输入y就行了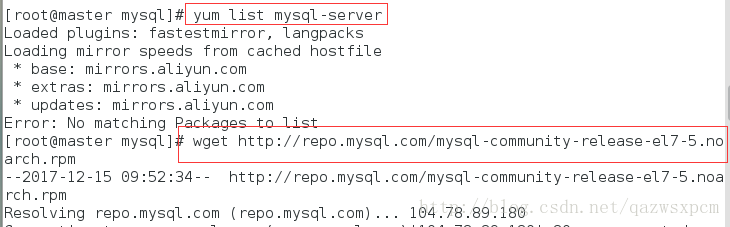

安装成功后,输入 service mysqld start 启动服务
输入:
mysqladmin -u root -p password '123456'
来设置密码
输入之后直接回车(默认是没有密码的)
然后再输入
mysql -u root -p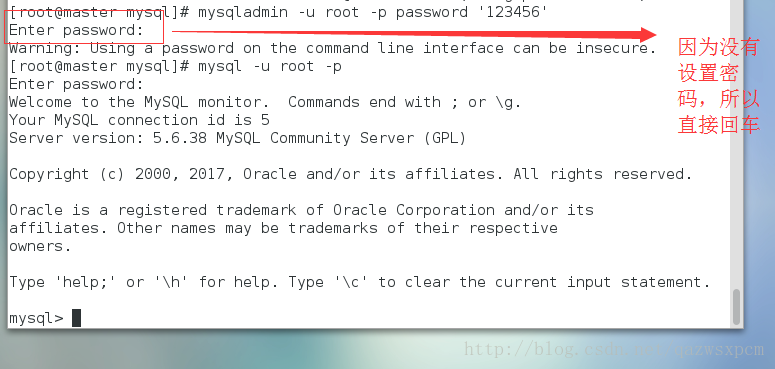
通过授权法更改远程连接权限
输入: grant all privileges on . to 'root'@'%' identified by '123456';
注:第一个’root’是用户名,第二个’%’是所有的ip都可以远程访问,第三个’123456’表示 用户密码 如果不常用 就关闭掉
输入:flush privileges; //刷新
在防火墙关闭之后,使用SQLYog之类的工具测试是否能正确连接
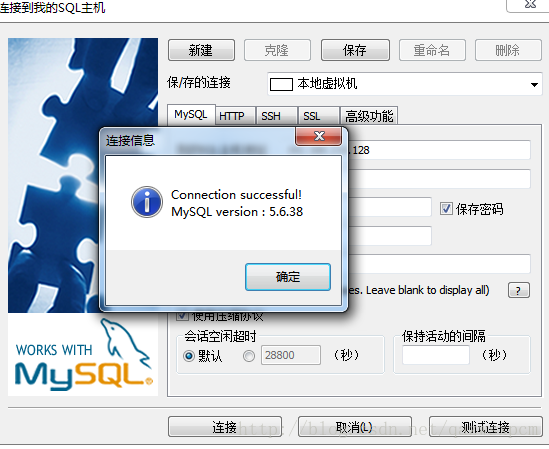
1.2 编译包安装
将下载好的mysql安装包上传到linux服务器
解压mysql解压包,并移动到/usr/local目录下,重命名为mysql。
命令:
tar -xvf mysql-5.6.21-linux-glibc2.5-x86_64.tar.gz
mv mysql-5.6.21-linux-glibc2.5-x86_64 /usr/local
cd /usr/local
mv mysql-5.6.21-linux-glibc2.5-x86_64 mysql
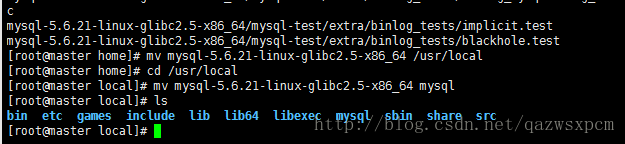
注: mysql默认的路径是就是/usr/local/mysql ,如果安装的地方更改,需要更改相应的配置文件。
安装mysql
切换到mysql的目录 /usr/local/mysql
输入:
./scripts/mysql_install_db --user=mysql

成功安装mysql之后,输入
service mysql start 或 /etc/init.d/mysql start
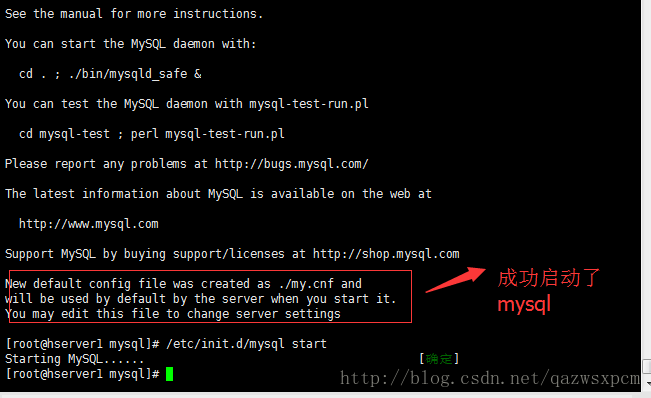
查看是否启动成功
输入:
ps -ef|grep mysql
切换到 /usr/local/mysql/bin 目录下
设置密码
mysqladmin -u root password '123456'入mysql
输入:
mysql -u root -p
设置远程连接权限
输入:
grant all privileges on *.* to 'root'@'%' identified by '123456';
然后输入:
flush privileges;
说明: 第一个’root’是用户名,第二个’%’是所有的ip都可以远程访问,第三个’123456’表示用户密码 如果不常用就关闭掉。
使用本地连接工具连接测试
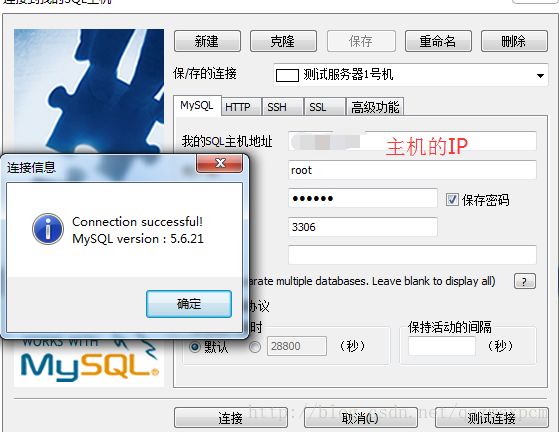
二、MySql排查问题的常用命令
1.查看mysql连接数
SHOW FULL PROCESSLIST;
2.查看mysql的配置
show variables like "%innodb%";
3.查看mysql事件是否开启
show variables like 'event_scheduler';
4.查看mysql锁的状态
是否锁表:
SHOW OPEN TABLES WHERE In_use > 0;
SHOW INNODB STATUS/G;
5.查看mysql data的存放位置
SHOW VARIABLES LIKE '%datadir%'
6.查看mysql 的超时时间设置
show variables like '%timeout%';
7.查看mysql 的日志存放
show variables like 'datadir';
mysql的日志分类
错误日志: -log-err
查询日志: -log
慢查询日志: -log-slow-queries
更新日志: -log-update
二进制日志: -log-bin
8.开启Mysql的操作日志记录
输入:
SHOW VARIABLES LIKE 'log_bin'
开启错误日志:
在my.cnf 或my.ini 中 添加 log-error=/home/mysql/logs/log-error.txt
开启查询日志:
在my.cnf 或my.ini 中 添加 log=/home/mysql/logs/mysql_log.txt
9.查看Mysql缓冲池大小
SHOW GLOBAL VARIABLES LIKE 'innodb_buffer_pool_size';
10.当前目录赋予mysql权限
chown -R mysql:mysql ./
11.查看mysql脏页比例
USE performance_schema;
SELECT VARIABLE_VALUE INTO @a FROM global_status WHERE VARIABLE_NAME = 'Innodb_buffer_pool_pages_dirty';
SELECT VARIABLE_VALUE INTO @b FROM global_status WHERE VARIABLE_NAME = 'Innodb_buffer_pool_pages_total';
SELECT @a/@b;
要合理的设置 innodb_io_capacity 的值,平时要多关注脏页比例,不让其接近 75%.
可以通过 innodb_flush_neighbors 来控制该行为,值为 1 打开上述机制,为 0 则关闭。
对于机械硬盘来说,是可以减少很多随机 IO ,因为机械硬盘 IOPS 一般就几百,减少随机 IO 就意味着性能提升。
但如果用 SSD 这类 IOPS 较高的设备,IOPS 往往不是瓶颈,关闭就好,减少 SQL 语句的响应时间。
在 8.0 中,已经默认是 0 了.
12.查看慢查询以及开启
SHOW VARIABLES LIKE 'slow_query%';
SET GLOBAL slow_query_log=ON;
set global long_query_time=1;
永久设置
[mysqld]
slow_query_log = ON
slow_query_log_file = /usr/local/mysql/data/slow.log
long_query_time = 1
long_query_time表示查询超过多少秒就记录
13. 开启mysql查询日志
开启会降低性能
查看日志配置
SHOW VARIABLES LIKE '%general_log%';
查询文件输出格式
SHOW VARIABLES LIKE 'log_output';
开启MySQL查询日志
SET GLOBAL general_log = ON;
关闭MySQL查询日志
SET GLOBAL general_log = OFF;
设置日志输出方式为表
SET GLOBAL log_output='table';
查询日志信息
select * from mysql.general_log;
14.数据库慢或数据库连接过多的命令排查
按客户端 IP 分组,看哪个客户端的链接数最多
SELECT client_ip,COUNT(client_ip) AS client_num FROM (SELECT
SUBSTRING_INDEX(HOST,':' ,1) AS client_ip FROM PROCESSLIST ) AS
connect_info GROUP BY client_ip ORDER BY client_num DESC;
查看正在执行的线程,并按 Time 倒排序,看看有没有执行时间特别长的线程
SELECT * FROM information_schema.processlist WHERE Command != 'Sleep'
ORDER BY TIME DESC;
找出所有执行时间超过 5 分钟的线程,拼凑出 kill 语句,方便后面查杀
SELECT CONCAT('kill ', id, ';') FROM information_schema.processlist
WHERE Command != 'Sleep' AND TIME > 300 ORDER BY TIME DESC;
批量kill的语句
select concat('KILL ',a.trx_mysql_thread_id ,';') from INFORMATION_SCHEMA.INNODB_LOCKS b,INFORMATION_SCHEMA.innodb_trx a where b.lock_trx_id=a.trx_id into outfile '/tmp/kill.txt';
三、MySql的优化建议
1.建表建议
1.1 选择索引的数据类型
MySQL支持很多数据类型,选择合适的数据类型存储数据对性能有很大的影响。通常来说,可以遵循以下一些指导原则:
1.越小的数据类型通常更好:
越小的数据类型通常在磁盘、内存和CPU缓存中都需要更少的空间,处理起来更快。
2.简单的数据类型更好:
整型数据比起字符,处理开销更小,因为字符串的比较更复杂。在MySQL中,应该用内置的日期和时间数据类型,而不是用字符串来存储时间;以及用整型数据类型存储IP地址。
3.尽量避免NULL:
应该指定列为NOT NULL,除非你想存储NULL。在MySQL中,含有空值的列很难进行查询优化,因为它们使得索引、索引的统计信息以及比较运算更加复杂。你应该用0、一个特殊的值或者一个空串代替空值。
4.一个表的索引最好不要超过6个:
索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引
1.2 选择主键类型
选择合适的标识符是非常重要的。选择时不仅应该考虑存储类型,而且应该考虑MySQL是怎样进行运算和比较的。一旦选定数据类型,应该保证所有相关的表都使用相同的数据类型。
- 整型:
通常是作为标识符的最好选择,因为可以更快的处理,而且可以设置为AUTO_INCREMENT。 - 字符串:
尽量避免使用字符串作为标识符,它们消耗更好的空间,处理起来也较慢。而且,通常来说,字符串都是随机的,所以它们在索引中的位置也是随机的,这会导致页面分裂、随机访问磁盘,聚簇索引分裂(对于使用聚簇索引的存储引擎)。
Mysql常见索引有:主键索引、唯一索引、普通索引、全文索引、组合索引
PRIMARY KEY(主键索引) ALTER TABLE table_name ADD PRIMARY KEY ( col )
UNIQUE(唯一索引) ALTER TABLE table_name ADD UNIQUE (col)
INDEX(普通索引) ALTER TABLE table_name ADD INDEX index_name (col)
FULLTEXT(全文索引) ALTER TABLE table_name ADD FULLTEXT ( col )
组合索引 ALTER TABLE table_name ADD INDEX index_name (col1, col2, col3 )
Mysql各种索引区别:
普通索引:最基本的索引,没有任何限制
唯一索引:与"普通索引"类似,不同的就是:索引列的值必须唯一,但允许有空值。
主键索引:它 是一种特殊的唯一索引,不允许有空值。
全文索引:仅可用于 MyISAM 表,针对较大的数据,生成全文索引很耗时好空间。
联合索引:为了更多的提高mysql效率可建立组合索引,遵循”最左前缀“原则。创建复合索引时应该将最常用(频率)作限制条件的列放在最左边,依次递减。
联合索引的好处:覆盖索引,这一点是最重要的,众所周知非主键索引会先查到主键索引的值再从主键索引上拿到想要的值。但是覆盖索引可以直接在非主键索引上拿到相应的值,减少一次查询。
复合索引和普通索引都是用一棵B+树表示的。
如果是单列,就按这列key数据进行排序。
如果是多列,就按多列数据排序,
例如有(1,1)(1,4)(2,2)(1,3) (2,1)(1,2)(2,3) (2,4)
那在索引中的叶子节点的数据顺序就是(1,1)(1,2)(1,3) (1,4)(2,1)(2,2)(2,3) (2,4)
这也是为什么查询复合索引的前缀是可以用到索引的原因
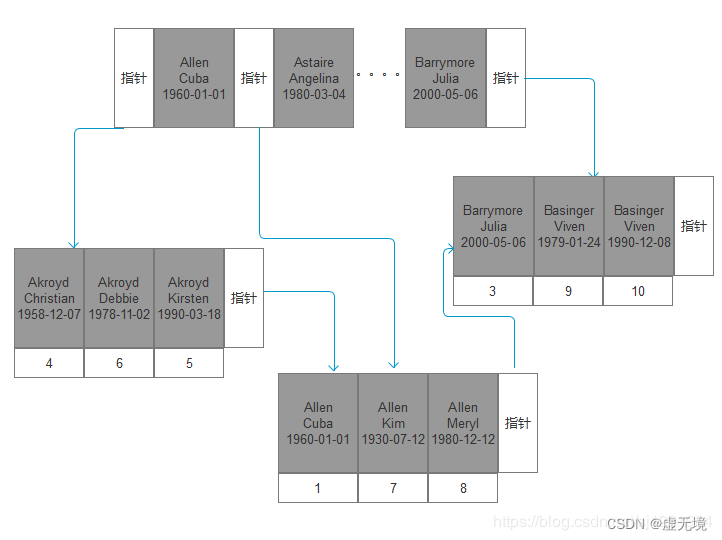
1.3 mysql索引方法hash和Btree区别
Hash仅支持=、>、>=、<、<=、between。BTree可以支持like模糊查询
索引是帮助mysql获取数据的数据结构。最常见的索引是Btree索引和Hash索引。
不同的引擎对于索引有不同的支持:Innodb和MyISAM默认的索引是Btree索引;而Mermory默认的索引是Hash索引。
我们在mysql中常用两种索引算法BTree和Hash,两种算法检索方式不一样,对查询的作用也不一样。
一、BTree
BTree索引是最常用的mysql数据库索引算法,因为它不仅可以被用在=,>,>=,<,<=和between这些比较操作符上,而且还可以用于like操作符,只要它的查询条件是一个不以通配符开头的常量,例如:
select * from user where name like ‘jack%’;
select * from user where name like ‘jac%k%’;
如果一通配符开头,或者没有使用常量,则不会使用索引,例如:
select * from user where name like ‘%jack’;
select * from user where name like simply_name;
二、Hash
Hash索引只能用于对等比较,例如=,<=>(相当于=)操作符。由于是一次定位数据,不像BTree索引需要从根节点到枝节点,最后才能访问到页节点这样多次IO访问,所以检索效率远高于BTree索引。
但为什么我们使用BTree比使用Hash多呢?主要Hash本身由于其特殊性,也带来了很多限制和弊端:
1.Hash索引仅仅能满足“=”,“IN”,“<=>”查询,不能使用范围查询。
2.联合索引中,Hash索引不能利用部分索引键查询。
对于联合索引中的多个列,Hash是要么全部使用,要么全部不使用,并不支持BTree支持的联合索引的最优前缀,也就是联合索引的前面一个或几个索引键进行查询时,Hash索引无法被利用。
3.Hash索引无法避免数据的排序操作
由于Hash索引中存放的是经过Hash计算之后的Hash值,而且Hash值的大小关系并不一定和Hash运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算。
4.Hash索引任何时候都不能避免表扫描
Hash索引是将索引键通过Hash运算之后,将Hash运算结果的Hash值和所对应的行指针信息存放于一个Hash表中,由于不同索引键存在相同Hash值,所以即使满足某个Hash键值的数据的记录条数,也无法从Hash索引中直接完成查询,还是要通过访问表中的实际数据进行比较,并得到相应的结果。
5.Hash索引遇到大量Hash值相等的情况后性能并不一定会比BTree高
对于选择性比较低的索引键,如果创建Hash索引,那么将会存在大量记录指针信息存于同一个Hash值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据访问,而造成整体性能底下。
- hash索引查找数据基本上能一次定位数据,当然有大量碰撞的话性能也会下降。而btree索引就得在节点上挨着查找了,很明显在数据精确查找方面hash索引的效率是要高于btree的;
- 那么不精确查找呢,也很明显,因为hash算法是基于等值计算的,所以对于“like”等范围查找hash索引无效,不支持;
- 对于btree支持的联合索引的最优前缀,hash也是无法支持的,联合索引中的字段要么全用要么全不用。提起最优前缀居然都泛起迷糊了,看来有时候放空得太厉害;
- hash不支持索引排序,索引值和计算出来的hash值大小并不一定一致。
1.4 mysql不走索引的情况
-
数据量太少:
如果表中的行数很少,MySQL可能会选择全表扫描而不是使用索引。 -
索引列被函数处理:
如果查询中对索引列进行了函数处理,MySQL就无法使用该索引进行优化,例如:
SELECT * FROM table WHERE YEAR(date_column) = 2021;
将无法使用date_column上的索引进行优化。
- 索引列被类型转换:
如果查询中对索引列进行了类型转换,MySQL也无法使用该索引进行优化,例如:
SELECT * FROM table WHERE int_column = '1';
将无法使用int_column上的索引进行优化。
-
索引列被模糊查询:
如果查询中对索引列进行了模糊查询(如使用LIKE, 非左匹配),MySQL也无法使用该索引进行优化。 -
多列索引未使用前缀:
如果使用了多列索引,并且查询中只使用了其中的一部分列,但是没有使用前缀,MySQL也无法使用该索引进行优化。 -
索引列存在NULL值:
如果索引列存在NULL值,MySQL可能无法使用该索引进行优化。 -
查询条件中包含OR、NOT、IN以及子查询的情况。
-
使用联合索引但是查询条件顺序不正确。
-
left join 字符集不一致
这种情况并非常见 可以通过以下语句查看: SHOW FULL COLUMNS FROM table1; SHOW FULL COLUMNS FROM table2;
2.查询优化建议
通过关键字 EXPLAIN 在查询语句前面加上可以查看索引走向
从上到下,性能从差到好
- all 全表查询
- index 索引全扫描
- range 索引范围扫描
- ref 使用非唯一或唯一索引的前缀扫描,返回相同值的记录
- eq_ref 使用唯一索引,只返回一条记录
- const,system 单表中最多只有一行匹配,根据唯一索引或主键进行查询
- null 不访问表或索引就可以直接得到结果
优化建议:
-
JOIN 后的的条件必须是索引,最好是唯一索引,否则数据一旦很多会直接卡死
-
一般禁止使用UNIION ON,除非UNION ON 前后的记录数很少
-
禁止使用OR
-
查总数使用COUNT(*)就可以,不需要COUNT(ID),MYSQL会自动优化
-
数据库字段设置 NOT NULL,字段类型 INT > VARCHAR 越小越好
-
禁止SELECT * ,需要确定到使用的字段
-
一般情况不在SQL中进行数值计算
3. 总数查询优化 建议
1.如果未设置主键,也未设置索引,可以对整型的字段添加索引
2.通过一个中间表来记录数据库内各表记录总数,然后通过触发器进行监听该表,实时更新总条数.
触发器:
CREATE
TRIGGER 数据库名.触发器名 BEFORE/AFTER INSERT/UPDATE/DELETE
ON 数据库名.<Table Name>
FOR EACH ROW
BEGIN
事件发生后执行的代码
END
创建示例:
当test_count表添加了数据,就对MT_COUNT的总数进行更新。
DELIMITER $$
CREATE
TRIGGER `ROWS_COUNT` BEFORE INSERT
ON `test_count`
FOR EACH ROW BEGIN
UPDATE MT_COUNT SET rowcount=rowcount+1 WHERE tablename = 'test_count';
END$$
DELIMITER ;
3.分页查询只第一次查询总数,或者分页查询和总数查询分开。
4.提升MySql写入速度建议
innodb_buffer_pool_size
如果用Innodb,那么这是一个重要变量。相对于MyISAM来说,Innodb对于buffer
size更敏感。MySIAM可能对于大数据量使用默认的key_buffer_size也还好,但Innodb在大数据量时用默认值就感觉在爬了。
Innodb的缓冲池会缓存数据和索引,所以不需要给系统的缓存留空间,如果只用Innodb,可以把这个值设为内存的70%-80%。和
key_buffer相同,如果数据量比较小也不怎么增加,那么不要把这个值设太高也可以提高内存的使用率。
innodb_additional_pool_size
这个的效果不是很明显,至少是当操作系统能合理分配内存时。但你可能仍需要设成20M或更多一点以看Innodb会分配多少内存做其他用途。
innodb_log_file_size
对于写很多尤其是大数据量时非常重要。要注意,大的文件提供更高的性能,但数据库恢复时会用更多的时间。一般用64M-512M,具体取决于服务器的空间。
innodb_log_buffer_size
默认值对于多数中等写操作和事务短的运用都是可以的。如
果经常做更新或者使用了很多blob数据,应该增大这个值。但太大了也是浪费内存,因为1秒钟总会
flush(这个词的中文怎么说呢?)一次,所以不需要设到超过1秒的需求。8M-16M一般应该够了。小的运用可以设更小一点。
innodb_flush_log_at_trx_commit (这个很管用)
抱怨Innodb比MyISAM慢
100倍?那么你大概是忘了调整这个值。默认值1的意思是每一次事务提交或事务外的指令都需要把日志写入(flush)硬盘,这是很费时的。特别是使用电
池供电缓存(Battery backed up
cache)时。设成2对于很多运用,特别是从MyISAM表转过来的是可以的,它的意思是不写入硬盘而是写入系统缓存。日志仍然会每秒flush到硬
盘,所以你一般不会丢失超过1-2秒的更新。设成0会更快一点,但安全方面比较差,即使MySQL挂了也可能会丢失事务的数据。而值2只会在整个操作系统
挂了时才可能丢数据。
四、MySql遇到的问题以及解决办法
1. mysql离线安装出现:Can't change to run as user 'mysql' ; Please check that the user exists!
原因:没有该用户。
解决办法:创建该用户!
例如:
添加用户:
groupadd -g 315 mysql
用户加入mysql:
useradd -u 315 -g mysql -d /usr/local/mysql -M mysql
再次输入
./scripts/mysql_install_db --user=mysql
成功!
2,安装完mysql之后,输入service mysql start 提示 mysql: unrecognized service。
问题原因: 是因为/etc/init.d/ 不存在 mysql 这个命令,所以无法识别。
解决办法:
1.首先查找mysql.server文件在哪
输入:
find / -name mysql.server
2.将mysql.server 复制到/etc/init.d/目录下,并重命名为mysql或mysqld
输入:
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysql
3.测试是否可以使用该命令
输入:
service mysql status
或
service mysqld status
3. 打开mysql出现:Got error 28 from storage engine
原因:mysql服务器的存储空间不够了,清空不用的数据就可以使用了。
4. Data too long for column 异常
1.数据库中设置的字符长度不够
找到对应的字段,将字符长度加长一些。
2.编码导致的原因,一般是由于输入了中文,才会出现类似的错误
统一设置为UTF-8
5. Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)
登录出现此异常
原因: 没有找到该文件,可以在/etc/my.cnf 文件中确认该文件的位置,若确定,这查看此文件的权限,若权限也ok,则添加 软链,
例如:
ln -s /var/lib/mysql/mysql.sock /tmp/mysql.sock
若还不行,则通过 mysql -uroot -p -S /var/run/mysqld/mysqld.sock 直接登录,不输入密码 。登录成功之后,在通过添加软链重新启动。
6. 登录mysql报错-bash: mysql: 未找到命令
原因:这是由于系统默认会查找/usr/bin下的命令,如果这个命令不在这个目录下,当然会找不到命令,我们需要做的就是映射一个链接到/usr/bin目录下,相当于建立一个链接文件。
首先得知道mysql命令或mysqladmin命令的完整路径,比如mysql的路径是:/usr/local/mysql/bin/mysql,我们则可以这样执行命令:
ln -s /usr/local/mysql/bin/mysql /usr/bin
以下是补充:
linux下,在mysql正常运行的情况下,输入mysql提示:
mysql command not found
遇上-bash: mysql: command not found的情况别着急,这个是因为/usr/local/bin目录下缺失mysql导致,只需要一下方法建立软链接,即可以解决:
把mysql安装目录,比如MYSQLPATH/bin/mysql,映射到/usr/local/bin目录下:
cd /usr/local/bin
ln -fs /MYSQLPATH/bin/mysql mysql
还有其它常用命令mysqladmin、mysqldump等不可用时候都可按用此方法解决。
注:其中MYSQLPATH是mysql的实际安装路径。
7. initialize specified but the data directory has files in it. Aborting
报这个错误的原因是因为你的mysql数据库已经进行初始化了,所以不能用这种方式再进行初始化用户了,因为mysql在初始化的时候会自动创建一个root用户的。更改/etc/cnf 的配置就行。
8.The server quit without updating PID file
错误信息详细描述:
root@MyServer:~# service mysql start
Starting MySQL
..The server quit without updating PID file (/usr/local/mysql/var/MyServer.pid). ... failed!
错误解决排查思路:
1.可能是/usr/local/mysql/data/rekfan.pid文件没有写的权限
解决方法 :给予权限,执行 “chown -R mysql:mysql /var/data” “chmod -R 755 /usr/local/mysql/data” 然后重新启动mysqld!
2.可能进程里已经存在mysql进程
解决方法:用命令“ps -ef|grep mysqld”查看是否有mysqld进程,如果有使用“kill -9 进程号”杀死,然后重新启动mysqld!
3.可能是第二次在机器上安装mysql,有残余数据影响了服务的启动。
解决方法:去mysql的数据目录/data看看,如果存在mysql-bin.index,就赶快把它删除掉吧,它就是罪魁祸首了。
4.mysql在启动时没有指定配置文件时会使用/etc/my.cnf配置文件,请打开这个文件查看在[mysqld]节下有没有指定数据目录(datadir)。
解决方法:请在[mysqld]下设置这一行:datadir = /usr/local/mysql/data
5.skip-federated字段问题
解决方法:检查一下/etc/my.cnf文件中有没有没被注释掉的skip-federated字段,如果有就立即注释掉吧。
6.错误日志目录不存在
解决方法:使用“chown” “chmod”命令赋予mysql所有者及权限
7.selinux惹的祸,如果是centos系统,默认会开启selinux
解决方法:关闭它,打开/etc/selinux/config,把SELINUX=enforcing改为SELINUX=disabled后存盘退出重启机器试试。
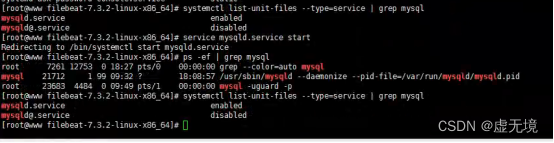
9.Failed to start mysql.service: Unit not found. Mysql
systemctl list-unit-files --type=service | grep mysql
service mysqld.service start
10.mysqldump: Got error: 1045: Unknown error 1045 when trying to connect
添加双引号
11.mysql 写入生僻字或特殊字符错误的解决办法
问题: 插入SQ语句出现 Incorrect string value: 'xF0xA1x8BxBExE5xA2...' for column 'name',这种错误,数据库编码设置已经是utf-8 ,插入其他的非特殊字符的语句正确。
解决办法 : mysql 版本5.5.3以后,有了一个utf8mb4编码,是utf8的超集,也兼容unicode 。所以将编码格式改为这个就可以了。
在my.cnf或my.ini中添加:
[client]
default-character-set = utf8mb4
[mysqld]
character-set-server=utf8mb4
collation-server=utf8mb4_unicode_ci
[mysql]
default-character-set = utf8mb4
其他
参考:
http://blog.csdn.net/zq199692288/article/details/78863737
https://blog.csdn.net/hjf161105/article/details/78850658
https://blog.csdn.net/everda/article/details/77476716
http://blog.itpub.net/29654823/viewspace-2150471
关于sql相关的文章:
https://www.cnblogs.com/xuwujing/category/1081197.html
非常好听的音乐~
原创不易,如果感觉不错,希望给个推荐!您的支持是我写作的最大动力!
版权声明:
作者:虚无境
博客园出处:http://www.cnblogs.com/xuwujing
CSDN出处:http://blog.csdn.net/qazwsxpcm
个人博客出处:https://xuwujing.github.io/
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


