
为什么要写这篇笔记?
TiDB自3.0.8版本开始默认使用悲观事务模型(只限新建集群,从之前的版本升级上来的默认还是使用乐观事务模式)。
事务模型影响着数据库高并发场景下的写入性能并且关系到数据的完整性,如果不了解其中的差异那么在面对事务冲突引发的问题时就会比较盲目。
很多新人(包括我在内)在学习TiDB的最初阶段对于TiDB的事务模型不甚了解,官方文档的解释虽精辟但并不很人性化,这篇笔记从最初的悲观和乐观模式的概念出发来探究乐观模式与悲观模式的差异,以及优劣。
为了解决什么问题?
精通TiDB的事务模型可以帮助了解日常生产遇到的写冲突异常,并可以帮助决定是使用悲观锁还是乐观锁模式。
笔记正文:
完整的官网文档见上述链接,一些FAQ和具体细节就不复制粘贴了,本文主要通过一些描述来帮助理解这两种事务模型。
一、广义概念的悲观锁和乐观锁
乐观锁:并发场景下,数据库认为并发会话之间并不会互相影响,因此在事务的内存读写阶段不对数据加锁,只在事务提交时进行写冲突检测(例如数据版本是否过期,被删除等等)。
悲观锁:并发场景下,数据库认为并发会话之间的数据写入是有冲突的,因此在事务做更改的初始阶段就会对要修改的数据加锁,直到事务结束。
乐观锁与悲观锁模式的主要差异在于:到底是事务提交阶段加锁来检测事务冲突?还是在事务开始阶段就直接对数据加锁来阻塞其他写操作?
可以看到,乐观锁模式下,只有在事务提交阶段才会检测写入冲突,而悲观模式全程加锁,所以相对而言乐观模式的并发量会高于悲观锁模式,但是其数据一致性性却比悲观锁差,并且事务失败时需要依赖应用层进行重试。
主流的关系型数据库例如oracle、sqlserver、mysql等,大多采用悲观事务模型以保证高并发场景下事务的一致性。
但是这里要强调一下,主流关系型数据库在事务模型的处理上多采用悲观事务模型以保证数据一致性,但并不是所有场景都使用悲观模型,例如mysql的commit和锁获取阶段都是乐观事务模型,只有在针对数据的获取方面采用悲观模型,而且在RDBMS系统中也鲜少会有产品在所有场景中都采用悲观模式,因为代价太大,且谁都不能确保自己的网络、硬件等永远不出问题。
此外这里推几篇链接帮助理解乐观/悲观锁模式:
pessimistic locking vs optimistic locking - Ask TOM (oracle.com)
sql server - Optimistic vs. Pessimistic locking - Stack Overflow
Concurrency Control - SQL Server | Microsoft Docs
二、TiDB的乐观事务模型
这里可以直接用一幅图来描述TiDB的乐观事务模型:

略微解析一下上述的流程,这幅图需要按从左往右,从上往下顺序来看,其主要步骤为(详细解释参考官网链接):
1.客户端开启事务后,tidb向pd获取一个tso作为事务的start_ts, 理解为start timestamp即可,以下同理。
2.tidb从pd获取读取数据的路由(既数据存在哪些tikv节点上),然后从tikv读取数据,读取小于此start_ms的最新数据版本。
3.数据在tidb的内存中完成修改。
4.客户端发起commit操作,接下来就是TiDB的两阶段提交流程:
5.第一阶段(prewrite阶段,也可以叫做加锁阶段):
。tidb将要写入的数据按照key分类,然后从pd获取数据的写入路由(既数据应该写入到哪些tikv节点)。
。tidb并发的向所有涉及的tikv发起请求,tikv收到请求后检查对应记录是否过期或者存在版本冲突,正常的话会加锁。
。tidb收到所有prewrite成功的相应,至此第一阶段完成。
6.第二阶段(正式提交阶段)
。tidb向pd获取一个tso作为commit_ts
。tidb向tikv发起第二阶段的提交请求,tikv进行数据写入,然后清理第一阶段的锁。
。tidb收到两阶段提交成功的信息,客户端收到tidb反馈的事务成功的信息。
7.最后tidb异步的清理本次事务遗留的锁信息。
乐观事务的优点和缺陷:
乐观事务的优点在于无需在事务执行阶段加锁,减少了锁获取的消耗,这样可以略微增加并发的性能。但前提是并发之间不会互相影响。
乐观事务最大的缺陷在于出现写入冲突时,只有一个会话可以成功,其他的都只能失败,套用Tom Kyte的一句话就是:
“我特么花了那么多时间来更新数据,结果到提交的时候你告诉我说:对不起你更改的数据已被其他会话变更,请重新开始???”
这就是传统RDBMS事务中使用悲观事务模型的原因,因为可以避免此类写冲突问题,且实际上有很多方法来极大减小悲观锁模型下的获取锁的消耗。
乐观事务下的重试机制:
从上边的描述我们知道,乐观锁模型下会出现写失败,全部依赖程序解决有点不现实,所以tidb内部增加了重试机制。
重试就相当于重新执行了事务,这样破坏了原本的事务一致性,可能产生更新丢失,不过一般情况下高并发时的更新丢失不会对业务造成什么影响,更新实际并未丢失,只是先后提交的问题。
以下两个参数控制重试的行为:
# 设置是否禁用自动重试,默认为 “on”,即不重试。
tidb_disable_txn_auto_retry = OFF
# 控制重试次数,默认为 “10”。只有自动重试启用时该参数才会生效。
# 当 “tidb_retry_limit= 0” 时,也会禁用自动重试。
tidb_retry_limit = 10
# 上述两个参数可以session或者global设置
三、TiDB的悲观事务模型
TiDB如何开启悲观事务模式:
SET GLOBAL tidb_txn_mode = 'pessimistic';
# 或者执行以下 SQL 语句显式地开启悲观事务:
BEGIN PESSIMISTIC;
在了解了乐观事务之后,我们再理解悲观事务就很简单了,乐观事务不是在提交阶段才加锁吗,悲观事务就是事务的起始阶段就加锁,
以上边乐观事务的图为例,加锁就发生在get data from TiKV or cache with start_ts阶段,如果事务中包含select语句(不带for update的)那么会在执行首个DML语句时加锁。
另外悲观模式下由于阻塞获取锁失败也有次数限制,默认256次,可以通过pessimistic-txn.max-retry-limit修改。
悲观事务下可以解决乐观事务模型下写入冲突的问题吗?
想啥呢......当然不可以,悲观事务模式下同一时刻依然只能有一个会话执行成功,但是其他会话并不是直接失败,而是被阻塞直到可以获取锁。这种模式更接近innodb的悲观锁模式。可以避免程序进行写冲突处理,或者避免事务重试时造成的更新丢失。
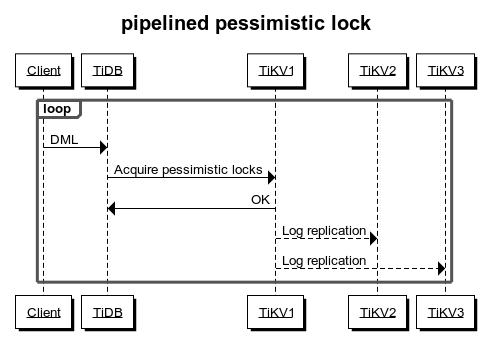
Pipelined加锁流程(默认关闭的):
悲观事务模型下事务加锁需要向tikv写入数据,经过raft提交ingapply之后才会返回,这样开销比较大,所以TiDB通过pipelined机制降低加锁消耗:
当数据满足加锁要求时,TiKV 立刻通知 TiDB 执行后面的请求,并异步写入悲观锁,从而降低大部分延迟,显著提升悲观事务的性能。但当 TiKV 出现网络隔离或者节点宕机时,悲观锁异步写入有可能失败,从而产生以下影响:
无法阻塞修改相同数据的其他事务。如果业务逻辑依赖加锁或等锁机制,业务逻辑的正确性将受到影响。
有较低概率导致事务提交失败,但不会影响事务正确性。
如果业务逻辑依赖加锁或等锁机制,或者即使在集群异常情况下也要尽可能保证事务提交的成功率,应关闭 pipelined 加锁功能。
四、为什么我们应该使用乐观/悲观事务模型?
回到最核心最迫切的问题上,我们的TiDB应该使用哪种事务模型?悲观or乐观?
官方的回答如下:
乐观事务模型下,将修改冲突视为事务提交的一部分。因此并发事务不常修改同一行时,可以跳过获取行锁的过程进而提升性能。但是并发事务频繁修改同一行(冲突)时,乐观事务的性能可能低于悲观事务。
启用乐观事务前,请确保应用程序可正确处理 commit语句可能返回的错误。如果不确定应用程序将会如何处理,建议改为使用悲观事务。
我的回答如下:
用悲观事务模型就好了,不要为了一丁点虚无缥缈的性能提升采用乐观事务模型,而且悲观事务模型下使用mysql driver访问tidb的BUG更少,行为更加贴近访问mysql本身。从我个人的观测看来,悲观事务下集群性能相比乐观事务模型并无下降。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!


 客服
客服


