
Locust
Locust 是比较常见的性能测试工具,底层基于 gevent。官方介绍 它是一款易于使用、可编写脚本且可扩展的性能测试工具,可以让我们使用常规 Python 代码定义用户的行为,而不必陷入 UI 或限制性领域特定语言中.
Locust具有无限的可扩展性(只要提供客户端python 代码,适用于所有协议的性能测试).
本文为开发性能自动化对比平台时学习相关内容的记录整理。
我们为什么选择locust
| 特点 | 说明 |
|---|---|
| 开源免费 | Locust是一个开源项目,无需支付费用,可以自由使用和定制。 |
| 易于学习使用 | 使用Python编写,学习路线平缓,拥有丰富的库和社区支持。 |
| 可扩展性灵活性高 | 可以根据需要定制测试,以便更准确地评估应用程序的性能。第三方插件较多、 易于扩展。 |
| 实时统计 | 提供实时统计功能和Web界面,方便监控和分析测试结果。 |
| 易于集成 | 可以轻松地与持续集成和持续部署工具集成,自动运行性能测试。 |
| 适用大规模的性能测试 | 支持分布式,可以轻松地在多台机器上运行测试,以模拟大量用户。这使得它非常适合进行大规模的性能测试。 |
Locust的核心部件
Master节点
负责协调和管理整个测试过程,包括启动和停止测试、分发任务、收集和汇总测试结果等。
Worker节点
实际执行测试任务的节点,根据Master节点分配的任务进行模拟用户行为。
Web UI
提供可视化的测试界面,方便用户查看测试结果、监控测试进度等。
测试脚本(Load Test Script)
测试脚本,定义模拟用户行为的逻辑和参数,由Worker节点执行。
Locust内部运行调用链路
时序图如下:
点击查看时序图说明
- 在测试启动时,Runner 类的 start() 方法会被调用,该方法会依次调用 EventHook 类的 fire() 方法,触发测试开始事件。
- Runner 类会根据配置创建 Environment 类的实例,并将其作为参数传递给 User 类和 TaskSet 类的构造函数,同时将 User 类和 TaskSet 类添加到 Environment 类的 user_classes 属性中。
- 在测试运行期间,Runner 类会启动多个用户进程,每个用户进程都会创建一个 User 类的实例,并调用 User 类的 run() 方法,该方法会调用 TaskSet 类的 run() 方法,从而执行用户的任务。
- 在任务执行期间,User 类和 TaskSet 类会使用 Environment 类的 client 属性来发送请求,并使用 Environment 类的 stats 属性来记录统计信息。
- 在任务执行完成后,TaskSet 类的 run() 方法会返回,User 类的 run() 方法会进入等待状态,等待其他用户完成任务。
- 在测试结束时,Runner 类的 stop() 方法会被调用,该方法会依次调用 EventHook 类的 fire() 方法,触发测试结束事件。
注:fire() 方法是 Locust 中的 EventHook 类中的一个方法,用于触发事件。在 Locust 的测试生命周期中,有多个事件可以被触发,例如测试开始、测试结束、用户启动、用户完成任务等。当这些事件发生时,EventHook 类会调用 fire() 方法,将事件传递给所有注册了该事件的回调函数。
locust 实践
locust安装
| 步骤 | 说明 |
|---|---|
| 点击跳转安装 Python3.7+ | 新版本标注需要Python3.7 or later |
pip install locust |
安装 locust |
执行locust |
检查是否安装成功 |
$ locust -V
locust 2.15.1 from /Users/bingohe/Hebinz/venvnew/lib/python3.9/site-packages/locust (python 3.9.17)
入门示例
使用 locust 编写用例时,约定大于配置:
test_xxx (一般测试框架约定)
dockerfile (docker约定)
locustfile.py (locust约定)
# locustfile.py
from locust import HttpUser, task
class HelloWorldUser(HttpUser): # 父类是个User,表示要生成进行负载测试的系统的 HTTP“用户”。每个user相当于一个协程链接 ,进行相关系统交互操作
@task # 装饰器来标记为一个测试任务, 表示用户要进行的操作:访问首页 → 登录 → 增、删改查
def hello_world(self):
wait_time = between(1, 5)
# self.client发送 HTTP 请求,模拟用户的操作
self.client.get("/helloworld")
启动测试
GUI 模式启动 locust
在有locustfile.py文件的目录直接执行locust命令,然后访问:http://0.0.0.0:8089/ 即可看到下面的界面:
$ locust
[2023-07-06 16:15:16,868] MacBook-Pro.local/INFO/locust.main: Starting web interface at http://0.0.0.0:8089 (accepting connections from all network interfaces)
[2023-07-06 16:15:16,876] MacBook-Pro.local/INFO/locust.main: Starting Locust 2.15.1
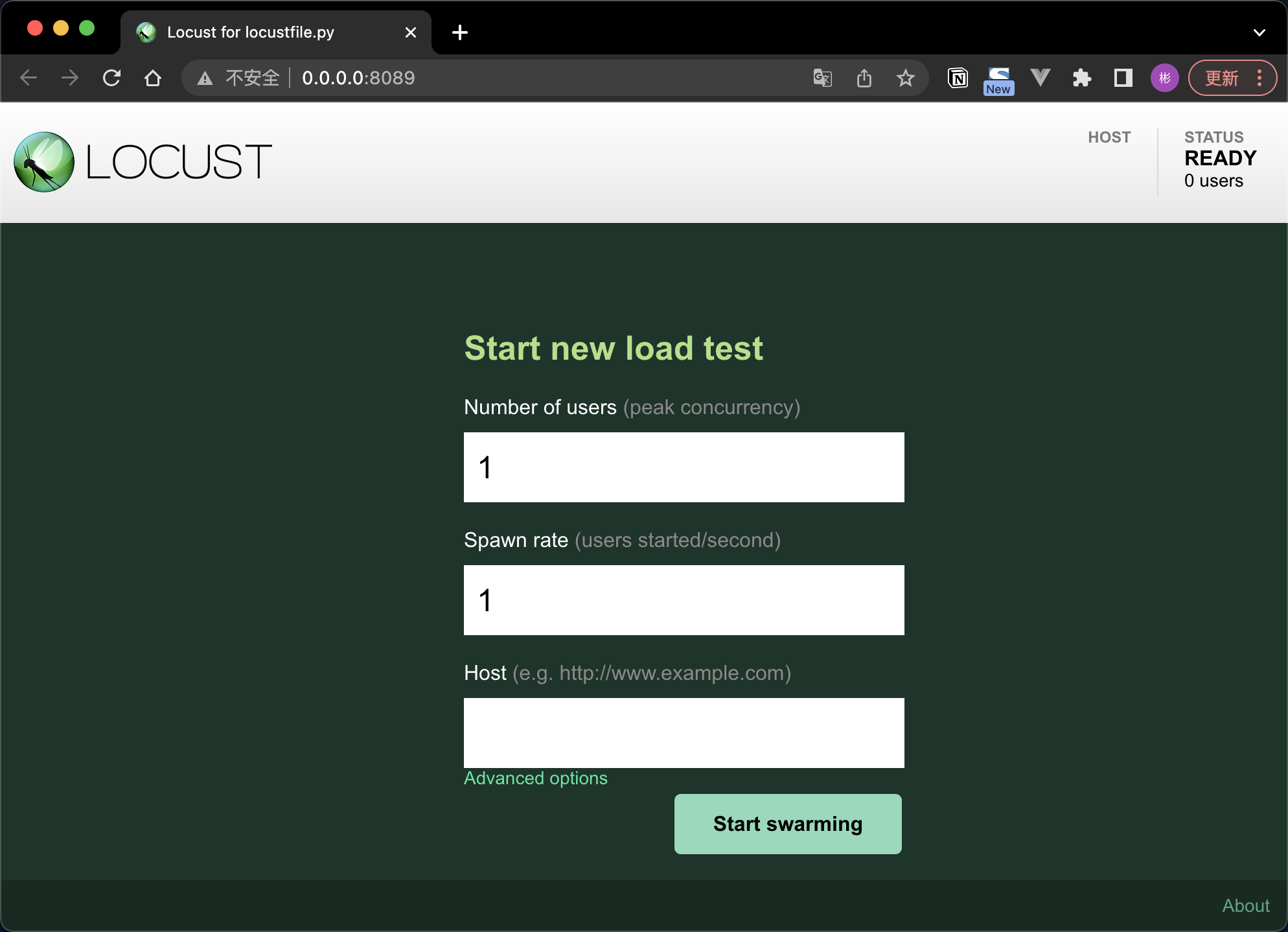
指标详解:
- Number of users 模拟用户数,默认 1
- Spawn rate : 生产数 (每秒)、 =>jmeter : Ramp-Up Period (in seconds), 默认 1
- Host (e.g. http://www.example.com) => 测试目标 svr 的 绝对地址
填写 host点击 start 之后就会对被测服务如http://{host}/helloworld 发起请求。请求统计数据如下:
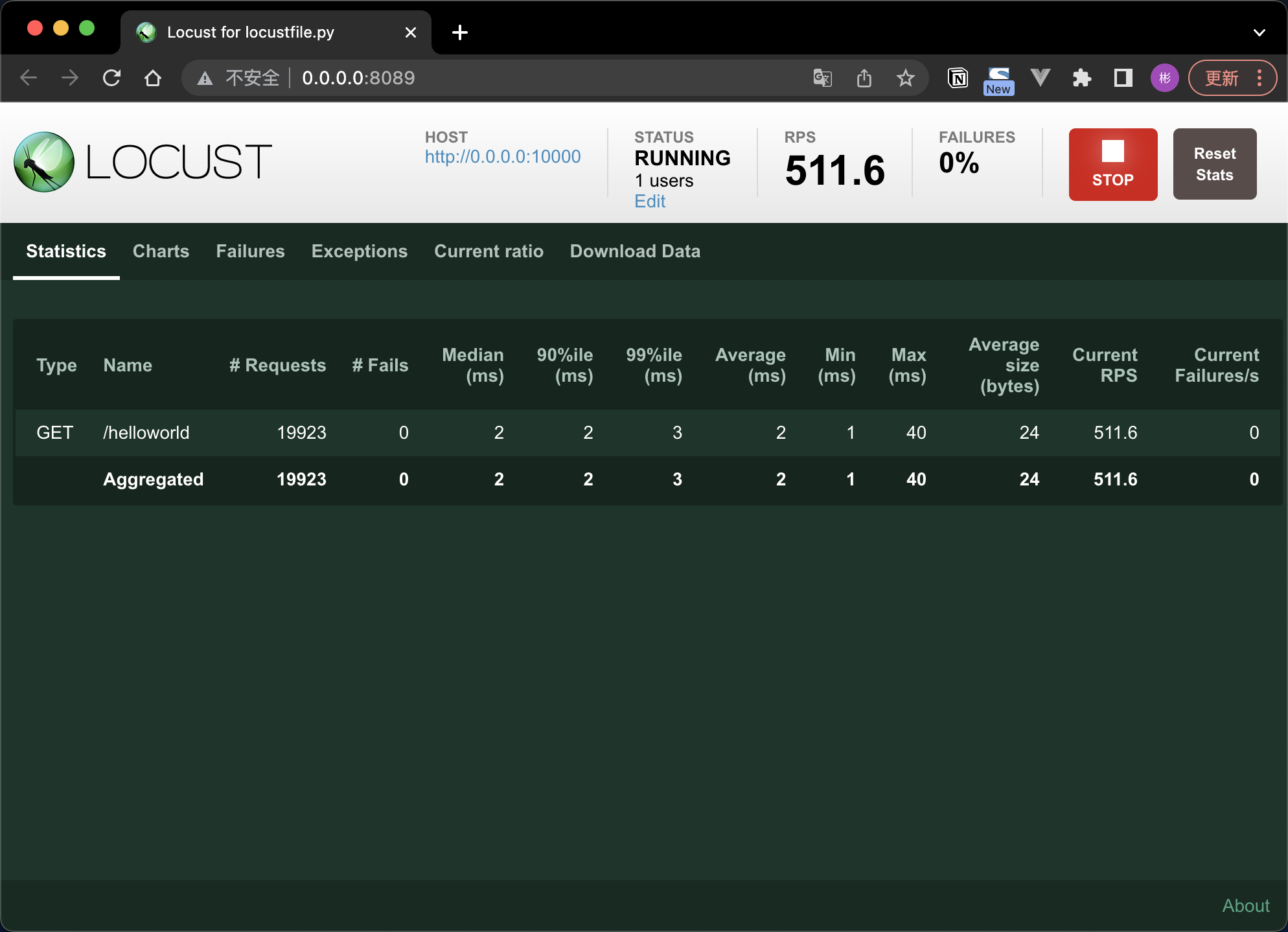
WebUI Tab说明:
| Tab名称 | 功能描述 |
|---|---|
| New test | 点击该按钮可对模拟的总虚拟用户数和每秒启动的虚拟用户数进行编辑 |
| Statistics | 类似于 JMeter 中 Listen 的聚合报告 |
| Charts | 测试结果变化趋势的曲线展示图,包括每秒完成的请求数(RPS)、响应时间、不同时间的虚拟用户数 |
| Failures | 失败请求的展示界面 |
| Exceptions | 异常请求的展示界面 |
| Download Data | 测试数据下载模块,提供三种类型的 CSV 格式的下载,分别是:Statistics、responsetime、exceptions |
需要说明的是webui 模式有很多限制,主要用于调试,下面将要介绍的命令行模式更为常用。
命令行模式启动 locust
locust -f locustfile.py --headless -u 500 -r 10 --host http://www.example.com -t 1000s
框架是通过命令locust运行的,常用参数有:
| 参数 | 含义 |
|---|---|
-f 或 --locustfile |
指定测试脚本文件的路径 |
--headless |
以非 GUI 模式运行测试 |
-u 或 --users |
指定并发用户数 |
-r 或 --spawn-rate |
指定用户生成速率(即每秒生成的用户数) |
-t 或 --run-time |
指定测试运行的最大时间 (单位:秒),与--no-web一起使用 |
--csv |
将测试结果输出到 CSV 文件中 |
--html |
将测试结果输出为 HTML 报告 |
--host或者 -H |
指定被测服务的地址 |
-L |
日志级别,默认为INFO |
检查点(断言)
Locust默认情况下会根据HTTP状态码来判断请求是否成功。对于HTTP状态码范围在200-399之间的响应,Locust会将其视为成功。对于HTTP状态码在400-599之间的响应,Locust会将其视为失败。
如果需要根据响应内容或其他条件来判断请求是否成功,需要手动设置检查点:
- 使用self.client提供的catch_response=True`参数, 添加locust提供的ResponseContextManager类的上下文方法手动设置检查点。
- ResponseContextManager里面的有两个方法来声明成功和失败,分别是
success和failure。其中failure方法需要我们传入一个参数,内容就是失败的原因。
from locust import HttpUser, task, between
class MyUser(HttpUser):
# 思考时间:模拟真实用户在浏览应用程序时的行为
wait_time = between(1, 5)
@task
def my_task(self):
# 基于Locust提供的ResponseContextManager上下文管理器,使用catch_response=True 参数来捕获响应,手动标记成功或失败,
with self.client.get("/some_page", catch_response=True) as response:
# 检查状态码是否为200且响应中包含 "some_text"
if response.status_code == 200 and "some_text" in response.text:
# 如果满足条件,标记响应为成功
response.success()
else:
# 如果条件不满足,根据具体情况生成错误信息
error_message = "Unexpected status code: " + str(response.status_code) if response.status_code != 200 else "Expected text not found in the response"
# 标记响应为失败,并报告错误信息
response.failure(error_message)
权重比例
如果需要请求有不同的比例,在Locust中,可以通过在@task装饰器中设置weight参数为任务分配权重来实现。权重越高,任务被执行的频率就越高。
from locust import HttpUser, task, between
class MyUser(HttpUser):
wait_time = between(1, 5)
# 设置权重为3,这个任务将被执行的频率更高
@task(3)
def high_frequency_task(self):
self.client.get("/high_frequency_page")
# 设置权重为1,这个任务将被执行的频率较低
@task(1)
def low_frequency_task(self):
self.client.get("/low_frequency_page")
在这个示例中,我们为high_frequency_task任务设置了权重为3,而为low_frequency_task任务设置了权重为1。这意味着在模拟用户执行任务时,high_frequency_task任务被执行的频率将是low_frequency_task任务的3倍。通过设置权重,我们可以根据实际需求调整不同任务在性能测试中的执行频率。
点击查看在Locust内部权重的实现原理
在Locust内部,权重是通过一个名为TaskSet的类来实现的。TaskSet类包含一个名为tasks的列表,该列表包含所有定义的任务。每个任务在列表中出现的次数等于其权重。当Locust选择要执行的任务时,它会从tasks列表中随机选择一个任务,这样权重较高的任务就有更高的概率被选中。
以下是一个简化的TaskSet类示例,以帮助理解权重是如何在Locust内部实现的:
import random
class TaskSet:
def __init__(self):
self.tasks = []
def add_task(self, task, weight=1):
for _ in range(weight):
self.tasks.append(task)
def get_random_task(self):
return random.choice(self.tasks)
task_set = TaskSet()
task_set.add_task("high_frequency_task", weight=3)
task_set.add_task("low_frequency_task", weight=1)
# 当我们调用 get_random_task() 方法时,权重较高的任务有更高的概率被选中
random_task = task_set.get_random_task()
在这个示例中,我们创建了一个简化的TaskSet类,它包含一个tasks列表和两个方法:add_task()用于添加任务及其权重,get_random_task()用于随机选择一个任务。权重较高的任务在tasks列表中出现的次数更多,因此它们更有可能被get_random_task()方法选中。
在实际的Locust实现中,这个概念稍微复杂一些,但基本原理是相同的:通过权重调整任务在内部列表中出现的次数,从而影响任务被选中的概率。
参数化
在现实世界中,用户的行为通常是多样化的。他们可能使用不同的设备、操作系统、网络条件等。为了更好地模拟这些场景,我们需要在测试中使用不同的参数。
在性能测试中,参数化是一种非常重要的技术手段。它允许我们使用不同的数据集运行相同的测试场景,从而更好地模拟真实世界的用户行为。常用的参数化方法有两种。
使用 Locust 的内置参数化功能
from locust import HttpUser, task, between
from locust.randoms import random_string, random_number
class MyUser(HttpUser):
wait_time = between(1, 5)
@task
def random_data(self):
random_str = random_string(10)
random_num = random_number(0, 100)
self.client.post("/random", json={"text": random_str, "number": random_num})
从外部文件读取参数
以已经配置成白名单的鉴权 session 为例:
import csv
from locust import HttpUser, task
class CSVReader:
def __init__(self, file, **kwargs):
try:
file = open(file)
except TypeError:
pass
self.file = file
self.reader = csv.reader(file, **kwargs) # iterator
def __next__(self):
try:
return next(self.reader)
except StopIteration:
# 如果没有下一行,则从头开始读
self.file.seek(0, 0)
return next(self.reader)
session = CSVReader("session.csv")
class MyUser(HttpUser):
@task
def index(self):
customer = next(ssn_reader)
self.client.get(f"/pay?session={customer[0]}")
Tag
在Locust中,标签(Tag)是用于对任务进行分类和筛选的一种方法。通过给任务添加标签,可以在运行Locust时只执行具有特定标签的任务。这在执行特定场景的性能测试或组织大量任务时非常有用。
使用场景
有时候我们会在同一个文件中写多个测试场景,但是运行的时候只想运行其中一部分,即当一个测试文件中的task不止一个时,我们可以通过@tag给task打标签进行分类,在执行测试时,通过--tags name执行指定带标签的task。
以下是一个使用标签的示例:
from locust import HttpUser, task, between, tag
class MyUser(HttpUser):
wait_time = between(1, 5)
# 给任务添加一个名为 "login" 的标签
@tag("login")
@task
def login_task(self):
self.client.post("/login", json={"username": "user", "password": "pass"})
# 给任务添加一个名为 "profile" 的标签
@tag("profile")
@task
def profile_task(self):
self.client.get("/profile")
# 给任务添加两个标签:"shopping" 和 "checkout"
@tag("shopping", "checkout")
@task
def checkout_task(self):
self.client.post("/checkout")
在这个示例中,我们为三个任务分别添加了不同的标签。login_task任务具有"login"标签,profile_task任务具有"profile"标签,而checkout_task任务具有"shopping"和"checkout"两个标签。
运行Locust时,可以通过使用--tags和--exclude-tags选项来指定要执行或排除的标签。例如,要仅执行具有"login"标签的任务,可以运行:
locust --tags login
要排除具有"shopping"标签的任务,可以运行:
locust --exclude-tags shopping
这样,我们就可以根据需要执行特定场景的性能测试,而不需要修改代码。
点击查看如何在Locust属性中指定 tag
在Locust中,可以使用tags属性来在HttpUser子类中指定标签。以下是一个示例:
from locust import HttpUser, task, between, tag
@tag("login")
class LoginTasks(HttpUser):
wait_time = between(1, 5)
@task
def login_task(self):
self.client.post("/login", json={"username": "user", "password": "pass"})
@tag("profile")
class ProfileTasks(HttpUser):
wait_time = between(1, 5)
@task
def profile_task(self):
self.client.get("/profile")
@tag("shopping", "checkout")
class CheckoutTasks(HttpUser):
wait_time = between(1, 5)
@task
def checkout_task(self):
self.client.post("/checkout")
在这个示例中,我们创建了三个不同的HttpUser子类,分别为LoginTasks、ProfileTasks和CheckoutTasks。我们在类级别使用@tag()装饰器为每个子类添加了标签。LoginTasks具有"login"标签,ProfileTasks具有"profile"标签,而CheckoutTasks具有"shopping"和"checkout"两个标签。
与之前的示例类似,可以使用--tags和--exclude-tags选项来指定要执行或排除的标签。在这种情况下,标签将应用于整个HttpUser子类,而不仅仅是单个任务。
集合点
什么是集合点?
集合点用以同步虚拟用户,以便恰好在同一时刻执行任务。在[测试计划]中,可能会要求系统能够承受1000 人同时提交数据,可以通过在提交数据操作前面加入集合点,这样当虚拟用户运行到提交数据的集合点时,就检查同时有多少用户运行到集合点,如果不到1000 人,已经到集合点的用户在此等待,当在集合点等待的用户达到1000 人时,1000 人同时去提交数据,从而达到测试计划中的需求。
注意:Locust框架本身没有直接封装集合点的概念 ,需要间接通过gevent并发机制,使用gevent的锁来实现。
在 Locust 中 实现集合点前,我们先了解两个概念:
gevent中的Semaphore信号量locust中的事件钩子all_locusts_spawned
Semaphore
信号量(Semaphore)是一种用于控制对共享资源访问的同步原语。它是计算机科学和并发编程中的一个重要概念,最早由著名计算机科学家Edsger Dijkstra于1960s提出。信号量用于解决多线程或多进程环境中的临界区问题,以防止对共享资源的竞争访问。
点击查看`Semaphore`实现原理
信号量的工作原理是通过维护一个计数器来表示可用资源的数量。当一个线程或进程想要访问共享资源时,它需要请求信号量。信号量会检查其计数器值:
如果计数器值大于0,表示有可用资源,信号量会减少计数器值并允许线程或进程访问共享资源。
如果计数器值等于0,表示没有可用资源,信号量会阻塞线程或进程,直到其他线程或进程释放资源。
当线程或进程完成对共享资源的访问后,它需要释放信号量。此时,信号量会增加计数器值,表示资源已释放并可供其他线程或进程使用。
信号量通常有两种类型:
二进制信号量(Binary Semaphore):计数器值只能为0或1。二进制信号量通常用于实现互斥锁(Mutex),以确保一次只有一个线程或进程访问共享资源。
计数信号量(Counting Semaphore):计数器值可以为任意正整数。计数信号量用于限制对共享资源的并发访问数量,以实现有限的资源池。
许多编程语言和库都提供了信号量的实现,例如Python中的threading.Semaphore和gevent.lock.Semaphore。使用信号量可以帮助解决并发编程中的同步和资源竞争问题。
gevent.lock.Semaphore是gevent库中提供的信号量实现。gevent是一个基于协程的Python并发库,使用轻量级的绿色线程(greenlet)提供高性能的并发。gevent.lock.Semaphore允许您在gevent协程中同步对共享资源的访问。
以下是gevent.lock.Semaphore的主要特点和使用方法:
- 初始化:要创建一个信号量,您可以实例化
gevent.lock.Semaphore类。在初始化时,可以选择设置信号量的初始值(默认值为1)。
from gevent.lock import Semaphore
# 创建一个具有默认初始值(1)的信号量
sem = Semaphore()
# 创建一个具有自定义初始值(5)的信号量
sem_with_initial_value = Semaphore(value=5)
- 请求资源(acquire):当协程需要访问共享资源时,它应该调用
Semaphore.acquire()方法。如果信号量的计数器值大于0,acquire()方法将减少计数器值并立即返回。如果计数器值为0,acquire()方法将阻塞协程,直到其他协程释放资源。
sem.acquire()
# 在此处访问共享资源
- 释放资源(release):当协程完成对共享资源的访问后,它应该调用
Semaphore.release()方法。这将增加信号量的计数器值,表示资源已释放并可供其他协程使用。
# 完成对共享资源的访问
sem.release()
- 使用上下文管理器:
gevent.lock.Semaphore还可以作为上下文管理器使用,以确保在访问共享资源的代码块结束时自动释放信号量。这可以简化代码并防止忘记释放信号量。
with sem:
# 在此处访问共享资源
# 信号量会在这里自动释放
总之,gevent.lock.Semaphore是gevent库中提供的信号量实现,用于在协程之间同步对共享资源的访问。通过使用Semaphore.acquire()和Semaphore.release()方法,您可以确保在gevent协程中正确处理并发访问。
all_locusts_spawned 事件
在 Locust 中,事件是一个非常重要的概念。事件允许我们在 Locust 的生命周期中的特定时刻执行自定义的操作。通过监听和处理这些事件,我们可以扩展 Locust 的功能,以满足测试需求。
spawning_complete 是 Locust 中的一个事件,表示所有的 Locust 用户(user)已经生成完成。当 Locust 开始运行测试并生成用户时,它会逐渐创建用户实例。一旦所有的用户都被创建,spawning_complete 事件就会被触发。你可以在这个事件中执行一些特定的操作,例如输出日志消息、收集统计信息或执行其他自定义操作。
要监听 spawning_complete 事件,你可以使用 locust.events.spawning_complete 事件钩子。例如:
from locust import events
@events.spawning_complete.add_listener
def on_spawning_complete():
print("All users have been spawned!")
在这个示例中,当所有的用户生成完成时,我们会输出一条消息 "All users have been spawned!"。你可以根据需要替换为其他操作。
点击查看 `Locust` 生命周期中其他的事件
test_start:测试开始时触发。spawning_start:生成用户时触发。user_add:每个用户被添加时触发。spawning_complete:所有用户生成完成时触发。request:每个请求发生时触发。test_stop:测试停止时触发。
了解完上面两个概念,接下来我们只需要两步走:
- 在脚本启动时,使用all_locust_spawned.acquire() 阻塞进程
- 编写一个函数,在 用户全部创建完成时触发 all_locust_spawned.release()
示例代码:
from locust import HttpUser, task, between
from gevent.lock import Semaphore
from locust import events
all_locust_spawned = Semaphore()
all_locust_spawned.acquire() # 阻塞
class MyUser(HttpUser):
wait_time = between(1, 1)
def on_start(self):
global all_locust_spawned
all_locust_spawned.wait(3) # 同步锁等待时间
@task
def task_rendezvous(self):
self.client.get("/rendezvous")
# 添加集合点事件处理器
@events.spawning_complete.add_listener # 所有的Locust实例产生完成时触发
def on_spawning_complete(**_kwargs):
global all_locust_spawned
all_locust_spawned.release()
分布式
当我们需要大量的并发用户,而单个计算机可能无法生成足够的负载来模拟这种情况时,分布式压力测试可以解决这个问题,我们可以通过将压力测试分布到多个计算机上来生成更大的负载,并更准确地评估系统的性能。
Locust 的限制
Locust 使用 Python 的 asyncio 库来实现异步 I/O,这意味着它可以充分利用多核 CPU 的性能。然而,由于 Python 的全局解释器锁(GIL)限制,单个 Python 进程无法充分利用多核 CPU。
为了解决这个问题,Locust 支持在单个计算机上运行多个从节点(worker node),这样可以充分利用多核 CPU 的性能。
当在单台计算机上运行多个从节点时,每个从节点将运行在一个单独的进程中,从而避免了 GIL 的限制。这样,我们可以充分利用多核 CPU 的性能,生成更大的负载。
单机主从模式
注意: slave 的节点数要小于等于本机的处理器数
在单机主从模式下,主节点和从节点都运行在同一台计算机上。这种模式适用于在本地开发环境中进行压力测试,或者在具有多核 CPU 的单台服务器上进行压力测试。以下是在单机主从模式下实现分布式压力测试的步骤:
-
安装 Locust:在计算机上安装 Locust,使用
pip install locust命令进行安装。 -
编写 Locust 测试脚本:编写一个 Locust 测试脚本,这个脚本将在主节点和从节点上运行。将此脚本保存为
locustfile.py。 -
启动主节点:在计算机上运行
locust --master命令启动主节点,监听默认端口(8089)。 -
启动从节点:在计算机上运行
locust --worker --master-host 127.0.0.1命令启动一个从节点。根据需要,可以启动多个从节点。 -
运行分布式压力测试:访问 Locust 的 Web 界面(http://127.0.0.1:8089),开始测试。
单机模式下,如何让每个从节点都运行在不同的 CPU 上
点击查看如何单机模式下,每个从节点都运行在不同的 CPU 上
在单机主从模式下,确保启动的多个从节点运行在不同的 CPU 核心上,可以通过为每个从节点设置 taskset 命令来实现。taskset 是一个 Linux 命令,可以用来设置进程的 CPU 亲和性,即将进程绑定到特定的 CPU 核心上运行。
以下是在单机主从模式下,确保启动的多个从节点运行在不同 CPU 核心上的步骤:
-
启动主节点:在计算机上运行
locust --master命令启动主节点,监听默认端口(8089)。 -
启动从节点:在计算机上运行以下命令启动从节点,并将其绑定到特定的 CPU 核心上:
taskset -c CORE_NUMBER locust --worker --master-host 127.0.0.1
其中,CORE_NUMBER 是要将从节点绑定到的 CPU 核心编号(从 0 开始)。例如,要将从节点绑定到第一个 CPU 核心上,可以运行以下命令:
taskset -c 0 locust --worker --master-host 127.0.0.1
- 根据需要,可以启动多个从节点,并将它们分别绑定到不同的 CPU 核心上。例如,要将第二个从节点绑定到第二个 CPU 核心上,可以运行以下命令:
taskset -c 1 locust --worker --master-host 127.0.0.1
请注意,taskset 命令仅适用于 Linux 系统。在 Windows 或 macOS 上,可以尝试使用类似的工具,例如 Windows 上的 start /affinity 命令或 macOS 上的 cpulimit 工具。
通过使用 taskset 命令或类似的工具,我们可以确保在单机主从模式下,启动的多个从节点运行在不同的 CPU 核心上。这有助于充分利用多核 CPU 的性能,生成更大的负载。
多机主从模式
操作与单机模式基本一样,访问 Locust 的 Web 界面时访问的时主节点的地址(http://MASTER_IP_ADDRESS:8089)。
因为主节点和从节点之间通过网络通信。因此,在选择主节点和从节点的计算机时,需要确保它们之间的网络连接畅通。此外,为了获得准确的测试结果,务必确保主节点和从节点之间的网络延迟较低。
分布式模式下的命令参数
| 命令参数 | 说明 |
|---|---|
--master |
将当前 Locust 实例作为主节点(master node)运行。 |
--worker |
将当前 Locust 实例作为从节点(worker node)运行。 |
--master-host |
指定主节点的 IP 地址或主机名。默认值为 127.0.0.1。 |
--master-port |
指定主节点的端口号。默认值为 5557。 |
--master-bind-host |
指定主节点绑定的 IP 地址或主机名。默认值为 *(所有接口)。 |
--master-bind-port |
指定主节点绑定的端口号。默认值为 5557。 |
--expect-workers |
指定主节点期望连接的从节点数量。默认值为 1。 |
--expect-workers 参数用于指定主节点期望连接的从节点数量。如果实际连接的从节点数量没有达到这个值,主节点会继续等待,直到足够的从节点连接上来。
在实际运行分布式压力测试时,主节点会在 Web 界面上显示连接的从节点数量。如果实际连接的从节点数量没有达到 --expect-workers 指定的值,你可以在 Web 界面上看到一个警告消息,提示你主节点正在等待更多从节点的连接。
docker 运行locust
使用 容器的方式运行 locust 的优势和缺点都非常明显:
| 优势 | 描述 |
|---|---|
| 环境一致性 | Docker 可以确保在不同计算机上运行的 Locust 环境是一致的。 |
| 便于部署 | 使用 Docker 可以简化 Locust 的部署过程。 |
| 易于扩展 | Docker 可以与容器编排工具结合使用,实现 Locust 从节点的自动扩展。 |
| 隔离性 | Docker 容器提供了一定程度的隔离性,将 Locust 运行环境与宿主机系统隔离。 |
| 缺点 | 描述 |
|---|---|
| 性能开销 | Docker 容器可能存在一定程度的性能损失,与在宿主机上直接运行 Locust 相比。 |
| 学习曲线 | 对于不熟悉 Docker 的用户,可能需要一定时间学习 Docker 的基本概念和使用方法。 |
| 系统资源占用 | 运行 Docker 容器需要消耗一定的系统资源(如 CPU、内存、磁盘空间等)。 |
但是以下这些场景使用 Docker 来运行 Locust 是一个更好的选择:
-
分布式压力测试:在分布式压力测试中,需要在多台计算机上运行 Locust 主节点和从节点。使用 Docker 可以确保所有节点的运行环境一致,简化部署过程。
-
云环境部署:如果你需要在云环境(如 AWS、Azure、GCP 等)中进行压力测试,使用 Docker 可以简化部署过程,并充分利用云平台提供的容器服务(如 Amazon ECS、Google Kubernetes Engine 等)。
-
CI/CD 集成:如果你需要将压力测试集成到持续集成/持续部署(CI/CD)流程中,使用 Docker 可以简化集成过程。许多 CI/CD 工具(如 Jenkins、GitLab CI、Travis CI 等)都支持 Docker 集成。
-
避免环境冲突:如果你的开发或测试环境中已经安装了其他 Python 应用程序,可能会出现依赖项冲突。使用 Docker 可以将 Locust 运行环境与宿主机系统隔离,避免潜在的环境冲突。
-
团队协作:在团队协作过程中,使用 Docker 可以确保每个团队成员都使用相同的 Locust 运行环境,从而避免因环境差异导致的问题。
具体使用步骤
-
首先,确保你已经安装了 Docker。如果尚未安装,请参考 Docker 官方文档 以获取适用于你的操作系统的安装说明。
-
编写一个 Locust 测试脚本。例如,创建一个名为
locustfile.py的文件,内容如下:
from locust import HttpUser, task, between
class MyUser(HttpUser):
wait_time = between(1, 5)
@task
def my_task(self):
self.client.get("/")
- 使用以下命令从 Docker Hub 拉取官方的 Locust 镜像:
docker pull locustio/locust
- 使用以下命令在 Docker 中运行 Locust。
docker run --rm -p 8089:8089 -v $PWD:/mnt/locust locustio/locust -f /mnt/locust/locustfile.py --host TARGET_HOST
在这个命令中,我们将当前目录(包含 locustfile.py 文件)挂载到 Docker 容器的 /mnt/locust 目录。然后,我们使用 -f 参数指定要运行的 Locust 测试脚本,并使用 --host 参数指定目标主机地址。
- 访问 Locust 的 Web 界面。在浏览器中打开
http://localhost:8089,你将看到 Locust 的 Web 界面。在这里,你可以开始压力测试并查看结果。
通过以上步骤,你可以在 Docker 中运行 Locust,无需在本地环境中安装 Locust。
总之,在需要确保环境一致性、简化部署过程、集成到 CI/CD 流程、避免环境冲突或团队协作的场景下,使用 Docker 来运行 Locust 是一个很好的选择。通过使用 Docker,你可以轻松地在不同的计算机或云环境中运行压力测试,从而实现更大规模的分布式压力测试。
高性能 FastHttpUser
Locust 的默认 HTTP 客户端使用http.client。如果计划以非常高的吞吐量运行测试并且运行 Locust 的硬件有限,那么它有时效率不够。
FastHttpUser 是 Locust 提供的一个特殊的用户类,用于执行 HTTP 请求。与默认的 HttpUser 不同,FastHttpUser 使用 C 语言库 gatling 编写的 httpclient 进行 HTTP 请求, 有时将给定硬件上每秒的最大请求数增加了 5 到 6 倍。在相同的并发条件下使用FastHttpUser能有效减少对负载机的资源消耗从而达到更大的http请求。
优势
-
性能:
FastHttpUser的主要优势是性能。由于它使用 C 语言库进行 HTTP 请求,它的性能通常比默认的HttpUser更高。这意味着在相同的硬件资源下,你可以使用FastHttpUser生成更大的负载。 -
资源占用:与默认的
HttpUser相比,FastHttpUser通常具有较低的资源占用(如 CPU、内存等)。这意味着在进行压力测试时,你可以在同一台计算机上运行更多的并发用户。 -
更高的并发能力:由于
FastHttpUser的性能和资源占用优势,它可以更好地支持大量并发用户的压力测试。这对于需要模拟大量并发用户的场景(如高流量 Web 应用程序、API 等)非常有用。
然而需要注意的是FastHttpUser 也有一些局限性。例如,它可能不支持某些特定的 HTTP 功能(如自定义 SSL 证书、代理设置等)。在选择使用 FastHttpUser 时,需要权衡性能优势和功能支持。如果测试场景不需要大量并发用户,或者需要特定的 HTTP 功能,使用默认的 HttpUser 可能更合适。
以下是一个使用 FastHttpUser 的 Locust 测试脚本示例:
from locust import FastHttpUser, task, between
class MyFastHttpUser(FastHttpUser):
wait_time = between(1, 5)
@task
def my_task(self):
self.client.get("/")
测试gRPC等其他协议
locust 并非 http 接口测试工具 , 只是内置了 “HttpUser” 示例 ,理论上来说,只要提供客户端,它可以测试任何协议。
如果有测试 gRPC、XML-RPC、requests-based libraries/SDKs等需求,可以参考:
https://docs.locust.io/en/stable/testing-other-systems.html
其他
主流性能测试工具对比
下面是 Locust、JMeter、Wrk 和 LoadRunner 四款性能测试工具的优缺点和支持的功能的对比表格:
| 工具名称 | 优点 | 缺点 | 支持的功能 |
|---|---|---|---|
| Locust | - 简单易用,支持 Python 语言 - 可以在代码中编写测试场景,灵活性高 - 可以使用分布式部署,支持大规模测试 - 支持 Web 和 WebSocket 测试 |
- 功能相对较少,不支持 GUI - 对于非 Python 开发人员不太友好 - 在大规模测试时需要手动管理分布式节点 |
- HTTP(S)、WebSocket 测试 - 支持断言、参数化、数据驱动等功能 - 支持分布式测试 |
| JMeter | - 功能丰富,支持多种协议 - 支持 GUI,易于使用 - 支持分布式部署,支持大规模测试 - 支持插件扩展,可以扩展功能 |
- 性能较差,不适合高并发测试 - 内存占用较高,需要较大的内存 - 学习曲线较陡峭 |
- HTTP(S)、FTP、JDBC、JMS、LDAP、SMTP、TCP、UDP 等多种协议的测试 - 支持断言、参数化、数据驱动等功能 - 支持分布式测试 |
| Wrk | - 性能优异,支持高并发测试 - 支持 Lua 脚本编写,灵活性高 - 支持多种输出格式,方便结果分析 |
- 功能相对较少,不支持 GUI - 只支持 HTTP 协议测试 - 学习曲线较陡峭 |
- HTTP(S) 测试 - 支持断言、参数化、数据驱动等功能 |
| LoadRunner | - 功能丰富,支持多种协议 - 支持 GUI,易于使用 - 支持分布式部署,支持大规模测试 - 支持插件扩展,可以扩展功能 |
- 价格较高,不适合小型团队使用 - 学习曲线较陡峭 - 对于非 Windows 平台的支持不够友好 |
- HTTP(S)、FTP、JDBC、JMS、LDAP、SMTP、TCP、UDP 等多种协议的测试 - 支持断言、参数化、数据驱动等功能 - 支持分布式测试 |
需要注意的是,这些工具的优缺点和支持的功能只是相对而言的,具体使用时需要根据实际需求和场景选择。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!
 客服
客服


