
06_pytorch的autograd操作
pytorch完整教程目录:https://www.cnblogs.com/nickchen121/p/14662511.html
一、引言
上一篇文章简单的讲解了 tensor 的使用方法,虽然看起来很多,但还是很不全面的,不过对于接下来各种项目的搭建是足够的,而且一通百通,真遇到一个两个不太会的方法,百度是个好东西。
在使用 torch 搭建一个项目时,就好比在搭建一个房子,而 tensor 就相当于各种原料,对于房子的骨架结构,则更多的需要我们接下来要介绍的东西来实现。
也就是 autograd,autogra 的中文名叫做自动微分,顾名思义,就是让 torch 帮我们自动计算微分,它也是 torch 进行神经网络优化的核心。因此站在神经网络架构中讲,autograd 这个东西能够根据输入和前向传播过程自动构建计算图,并执行反向传播。
注:计算图可以简单的看做网络的架构图,只不过这个“架构图”转载的是各个流程单元的数据信息。
二、Variable
2.1 Variable 的数据结构
autograd 模块的核心数据结构是 Variable,它是对 tensor 的封装,并且会记录 tensor 的操作记录用来构建计算图。Variable 的数据结构如下图所示:

上图主要包含三个属性:
- data:保存 variable 所包含的 tensor
- grad:保存 data 对应的梯度,grad 也是 variable,而非 tensor,它与 data 形状一致
- grad_fn:指向一个 Function,记录 variable 的操作历史,即它是什么操作的输出,用来构建计算图。如果某一变量是用户创建的,则它为叶子节点,对应的 grad_fn 为 None
Variable 的构造函数需要传入 tensor,也有两个可选的参数:
- requires_grad(bool):是否需要对该 Variable 求导
- volatile(bool):设置为 True,构建在该 Variable 之上的图都不会求导
2.2 反向传播
Variable 支持大部分 tensor 支持的函数,但不支持部分 inplace 函数,因为它们会修改 tensor 自身,然而在反向传播中,Variable 需要缓存原来的 tensor 计算梯度。如果想要计算各个 Variable 的梯度,只需要调用根结点的 backward 方法,autograd 则会自动沿着计算图反向传播,计算每一个叶子节点的梯度。
variable.backward(grad_variable=None, retain_fraph=None, create_graph=None)的参数解释如下:
- grad_variables:形状与 Variable 一直,对于
y.backward(),grad_variables 相当于链式法则(frac{partial{z}}{partial{x}} = frac{partial{z}}{partial{y}}frac{partial{y}}{partial{x}})。grad_variables 也可以是 tensor 或序列 - retain_graph:反向传播会缓存一些中间结果,反向传播之后,这些缓存就会清除,可通过这个参数指定不清除缓存,用来多次反向传播
- create_graph:对反向传播过程中再次构建计算图
import torch as t
from torch.autograd import Variable as V
a = V(t.ones(3, 4), requires_grad=True)
a
tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]], requires_grad=True)
b = V(t.zeros(3, 4))
b
tensor([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
c = a.add(b) # variable 函数的使用和 tensor 一致,等同于 c=a+b
c
tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]], grad_fn=<AddBackward0>)
# 注:虽然没有指定 c 需要求导,但 c 依赖于 a,由于 a 需要求导,因此 c 的 requeires_grad 默认设置为 True
a.requires_grad, b.requires_grad, c.requires_grad
(True, False, True)
# 注:`c.data.sum()`是在去 data 后变为 tensor,从 tensor 计算sum;`c.sum()`计算后仍然是 variable
d = c.sum()
d.backward() # 反向传播
a.grad
tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
# 由用户创建的 Variable 属于叶子节点,对应的 grad_fn 是 None
a.is_leaf, b.is_leaf, c.is_leaf
(True, True, False)
# 虽然 `c.requires_grad=True`,但是它的梯度计算完之后就会被释放
c.retain_grad() # 对于非叶节点求导,需进行保存,否则会被自动释放,这里我们先保存然后再查看,如果没有这一行,会报错
c.grad is None
True
2.3 autograd 求导数和手动求导数
通过对函数(y=x^2e^x)求导,我们可以看看 autograd 求导数和自己写个方法求导数的区别。这个函数的导数如下:
def f(x):
"""计算 y"""
y = x**2 * t.exp(x)
return y
def grad_f(x):
"""手动对函数求导"""
dx = 2 * x * t.exp(x) + x**2 * t.exp(x)
return dx
x = V(t.randn(3, 4), requires_grad=True)
y = f(x)
y
tensor([[0.1456, 0.0344, 0.5350, 0.0165],
[0.9979, 0.3471, 0.5367, 0.4838],
[0.2595, 0.0010, 0.2002, 0.2058]], grad_fn=<MulBackward0>)
y_grad_variables = t.ones(
y.size()) # 由于dz/dy=1,并且grad_variables 形状需要与 y 一致,详解看下面的 3.4 小节
y.backward(y_grad_variables)
x.grad
tensor([[ 1.0434, -0.3003, -0.0624, 0.2895],
[ 3.8373, 1.8350, 0.0467, -0.2063],
[-0.4456, 0.0655, -0.4609, -0.4604]])
grad_f(x) # autograd 计算的结果和利用公式计算的结果一致
tensor([[ 1.0434, -0.3003, -0.0624, 0.2895],
[ 3.8373, 1.8350, 0.0467, -0.2063],
[-0.4456, 0.0655, -0.4609, -0.4604]], grad_fn=<AddBackward0>)
三、计算图
3.1 手动计算梯度
torch 的 autograd 的底层采用了计算图,它是一种特殊的有向无环图,记录算子和变量的关系,如下图所示:
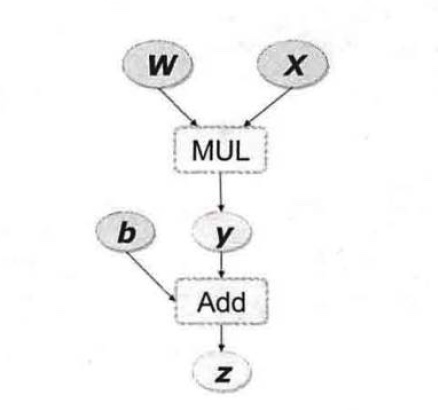
其中 MUL 和 ADD 都是算子,用矩形表示;w、x、b 都是变量,用椭圆形表示。上述所示的变量 w、x、b 都是叶子节点,一般由用户创立,不依赖于其他变量。z 称为根结点,是计算图的最终目标。
其中各个叶子节点的梯度可以用链式法则求出为:
- (frac{partial{z}}{partial{y}}=1, frac{partial{z}}{partial{b}}=1)
- (frac{partial{z}}{partial{w}}=frac{partial{z}}{partial{y}}frac{partial{y}}{partial{w}}=1*x,frac{partial{z}}{partial{x}}=frac{partial{z}}{partial{y}}frac{partial{z}}{partial{x}}=1*w)
3.2 利用 torch 进行反向传播求梯度
对于上述的计算梯度,如果有了计算图,则可以通过 torch 的 autograd 反向传播自动完成。前面说到 autograd 会随着用户的操作,记录生产当前的 variable 的所有操作,并由此建立一个有向无环图,随着用户的每一个操作,相应的计算图就会发生改变,更底层的操作就是在图中记录了 Function,如下图的 addBackward。上述所说的有向无环图如下图所示:
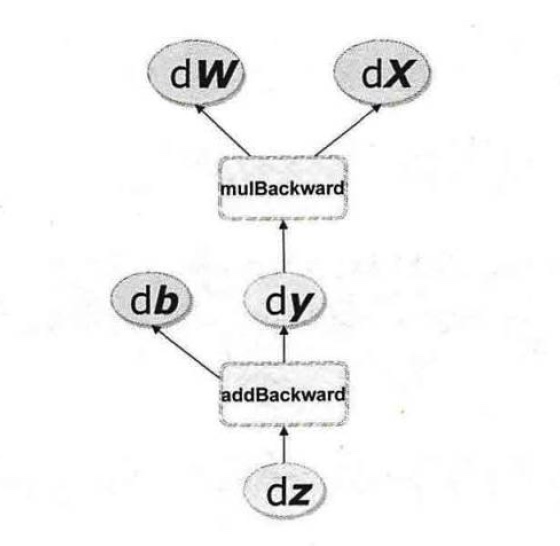
由于torch 把每一个操作都写入了计算图中,也由此每一个变量在图中的位置可通过 它的grad_fn 属性在图中的位置推测得到。
进而在反向传播过程中,autograd 沿着这个图从根节点 z 溯源,然后利用链式求导法则计算所有叶子节点的梯度。每一个前向传播操作的函数都会有与之对应的反向传播函数用来计算输入的各个 variable 的梯度,这些函数的函数名通常以 Backward 结尾。
x = V(t.ones(1))
b = V(t.rand(1), requires_grad=True)
w = V(t.rand(1), requires_grad=True)
y = w * x # 等价于 y=w.mul(x)
z = y + b # 等价于 z=y.add(b)
# 由于 y 依赖于求导的 w,故而即使 y 没有指定requires_grad=True,也为 True;z 同理
x.requires_grad, b.requires_grad, w.requires_grad, y.requires_grad, z.requires_grad
(False, True, True, True, True)
x.is_leaf, b.is_leaf, w.is_leaf, y.is_leaf, z.is_leaf
(True, True, True, False, False)
# grad_fn 可以查看这个 variable 的反向传播函数
# 由于 z 是 add 函数的输出,所以它的反向传播函数是 AddBackward
z.grad_fn
<AddBackward0 at 0x7fdd9bbbe470>
# next_functions 保存 grad_fn 的输入,grad_fn 是一个元组
# 第一个是 y,它是乘法的输出,所以对应的反向传播函数 y.grad_fn 是 MulBackward
# 第二个是 b,它是叶子节点,由用户创建,grad_fn 为 None,但是有 z.grad_fn.next_functions
z.grad_fn.next_functions
((<MulBackward0 at 0x7fdd9bbbe908>, 0),
(<AccumulateGrad at 0x7fdd9bbbe940>, 0))
z.grad_fn.next_functions[0][0] == y.grad_fn # 证明上述所说
True
# 第一个是 w,叶子节点,但代码中规定需要求导,梯度是累加的
# 第二个是 x,叶子节点,单不需要求导,所以为 None
y.grad_fn.next_functions
((<AccumulateGrad at 0x7fdd9bbc50f0>, 0), (None, 0))
# 虽然 w 规定了需要求导,但是叶子节点的 grad_fn 都是 None
w.grad_fn, x.grad_fn
(None, None)
计算 w 的梯度时需要用到 x 的数值((frac{partial{y}}{partial{w}}=x)),这些数值在前向过程中会被保存为 buffer,但是在梯度计算完之后清空。为了能够多次反向传播,可以指定 retain_graph 来保留这些 buffer。
# error 的原因是版本问题,PyTorch0.3 中把许多python的操作转移到了C++中
# saved_variables 现在是一个c++的对象,无法通过python访问。
try:
y.grad_fn.saved_variables
except Exception as e:
print(f'error: {e}')
error: 'MulBackward0' object has no attribute 'saved_variables'
# 使用 retain_graph 保存 buffer
z.backward(retain_graph=True)
w.grad
tensor([1.])
# 多次反向传播,梯度累加,这也就是 w 中 AccumulateGrad 标识的含义
# 如果第一次 backward 没有 retain_graph=True 参数,再次反向传播则会报错
z.backward()
w.grad
tensor([2.])
# 由于反向传播没有保存 buffer,前向过程中保存的 buffer 都被清空,无法在进行正常的反向传播
z.backward() # 会报错
y.grad_fn.saved_variables # 会报错
3.3 在前向传播中利用动态图特性构建计算图
由于 torch 使用的是动态图,它的计算图在每次前向传播开始都是从头开始构建的,因此可以用使用 Python 的控制语句按照需求构建计算图。这意味着你不需要事先构建所有可能用到的图的路径,图可以在运行的时候构建。
def abs(x):
if x.data[0] > 0: return x
else: return -x
x = V(t.ones(1), requires_grad=True)
y = abs(x) # 相当于 y = x
y.backward()
x.grad
tensor([1.])
x = V(-1 * t.ones(1), requires_grad=True)
y = abs(x) # 相当于 y = -x
y.backward()
x.grad
tensor([-1.])
t.arange(-2, 4)
tensor([-2, -1, 0, 1, 2, 3])
def f(x):
result = 1
for i in x:
if i.data > 0:
result = i * result
return result
x = V(t.arange(-2, 4, dtype=t.float), requires_grad=True)
y = f(x) # 相当于 y = x[3]*x[4]*x[5]
y.backward()
x.grad
tensor([0., 0., 0., 6., 3., 2.])
在某些场景下,有些节点不需要反向传播,也不需计算图的生成,因此可以使用一个上下文管理器with torch.no_grad()
x = V(t.ones(1), requires_grad=True)
y = 2 * x
x.requires_grad, y.requires_grad
(True, True)
x = V(t.ones(1), requires_grad=True)
with t.no_grad():
y = 2 * x
x.requires_grad, y.requires_grad
(True, False)
反向传播过程中非叶子节点的导数计算完之后将会被清空,可以通过以下三种方法查看这边变量的梯度:
- 使用retain_grad保存梯度
- 使用
autograd.grad函数 - 使用 hook
上述两个方法都是很强大的工具,具体的方法可以查看官网 api,这里只给出基础的用法。
x = V(t.ones(3), requires_grad=True)
w = V(t.rand(3), requires_grad=True)
y = x * w
z = y.sum()
z.backward()
y.retain_grad()
# 非叶子节点grad 计算完后清空,y 是 None
x.grad, w.grad, y.grad
(tensor([0.6035, 0.5587, 0.7389]), tensor([1., 1., 1.]), None)
# 第一种方法,保存梯度
x = V(t.ones(3), requires_grad=True)
w = V(t.rand(3), requires_grad=True)
y = x * w
z = y.sum()
y.retain_grad()
z.backward()
# 非叶子节点grad 计算完后清空,y 是 None
y.grad
tensor([1., 1., 1.])
# 第二种方法,使用 grad 获取中间变量的梯度
x = V(t.ones(3), requires_grad=True)
w = V(t.rand(3), requires_grad=True)
y = x * w
z = y.sum()
# z 对 y 的梯度,隐式调用 backward()
t.autograd.grad(z, y)
(tensor([1., 1., 1.]),)
# 第三种方法,使用 hook
# hook 是一个函数,输入是梯度,不应该有返回值
def variable_hook(grad):
print(f'y 的梯度:{grad}')
x = V(t.ones(3), requires_grad=True)
w = V(t.rand(3), requires_grad=True)
y = x * w
z = y.sum()
# 注册 hook
hook_handle = y.register_hook(variable_hook)
z = y.sum()
z.backward()
# 除非你每次都要使用 hook,否则使用后应该移除 hook
hook_handle.remove()
y 的梯度:tensor([1., 1., 1.])
3.4 variable 的 grad 属性和 backward函数 的 grad_variables 参数的区别
- variable X 的梯度是目标函数 f(x) 对 X 的梯度,(frac{partial{f(X)}}{partial{X}}=(frac{partial{f(X)}}{partial{x_0}},frac{partial{f(X)}}{partial{x_1}},cdots,frac{partial{f(X)}}{partial{x_n}}))
y.backward(grad_variables)中的 grad_variables 相当于链式求导法则中的 (frac{partial{z}}{partial{x}}=frac{partial{z}}{partial{y}}frac{partial{y}}{partial{x}}) 中的 (frac{partial{z}}{partial{y}})。z 是目标函数,一般是一个标量,因此 (frac{partial{z}}{partial{y}}) 的形状和 y 的形状一致。z.backward()等价于 y.backward(grad_y)。z.backward()省略了 grad_variables 参数,因为 z 是一个标量,并且 (frac{partial{z}}{partial{z}}=1)
x = V(t.arange(0, 3, dtype=t.float32), requires_grad=True)
y = x**2 + x * 2 # dy/dz = 2 * x + 2
z = y.sum()
z.backward() # 从 z 开始反向传播
x.grad
tensor([2., 4., 6.])
x = V(t.arange(0, 3, dtype=t.float32), requires_grad=True)
y = x**2 + x * 2 # dy/dz = 2 * x + 2
z = y.sum()
y_grad_variables = V(t.Tensor([1, 1, 1])) # dz/dy
y.backward(y_grad_variables)
x.grad
tensor([2., 4., 6.])
3.5 计算图特点小结
在反向传播时,需要注意的是,只有对 variable 操作才能使用 autograd,如果对 variable 的 data 操作,无法使用反向传播,并且除了参数初始化,一般不会修改 varaible.data 值。
讲了这么多,在 torch 中计算图的特点可总结如下:
- autograd 根据用户对 variable 的操作构建计算图。对 variable 的操作抽象为 Function。
- 由用户创建的结点称作叶子节点,叶子节点的 grad_fn 为 None。并且叶子节点中需要求导的 variable,具有 AccumulateGrad 标识,因为它的梯度是累加的。
- variable 默认是不需要求导的。如果某一个节点的
requeires_grad=True,那么所有依赖它的节点都为 True。 - 多次反向传播时,梯度是累加的。反向传播的中间缓存会被清空,为进行多次反向传播需要指定
retain_graph=True来保存这些缓存。 - 非叶子节点的梯度计算完之后就会被清空,可以使用 autograd.grad 和 hook 技术获取非叶子节点梯度的值,也可以通过 retain_grad 保存它的梯度值。
- varibale 的 grad 和 data 形状一致,应该避免直接修改 variable.data,因为对 data 值的修改无法进行反向传播。
- 反向传播函数 backward 的参数 grad_variables 可以看成是链式求导的中间结果,如果是标量,可以省略,默认为 1。
- torch 采用动态图的设计,可以很方便的查看中间层的输出,动态地设计计算图的结构。
四、用 variable 实现线性回归(autograd 实战)
import torch as t
from torch.autograd import Variable as V
# 不是 jupyter 运行请注释掉下面一行,为了 jupyter 显示图片
%matplotlib inline
from matplotlib import pyplot as plt
from IPython import display
t.manual_seed(1000) # 随机数种子
def get_fake_data(batch_size=8):
"""产生随机数据:y = x * 2 + 3,同时加上了一些噪声"""
x = t.rand(batch_size, 1) * 20
y = x * 2 + (1 + t.randn(batch_size, 1)) * 3 # 噪声为 |3-((1 + t.randn(batch_size, 1)) * 3)|
return x, y
# 查看 x,y 的分布情况
x, y = get_fake_data()
plt.scatter(x.squeeze().numpy(), y.squeeze().numpy())
plt.show()

# 随机初始化参数
w = V(t.rand(1, 1), requires_grad=True)
b = V(t.zeros(1, 1), requires_grad=True)
lr = 0.001 # 学习率
for i in range(8000):
x, y = get_fake_data()
x, y = V(x), V(y)
# forwad:计算 loss
y_pred = x.mm(w) + b.expand_as(y)
loss = 0.5 * (y_pred - y)**2
loss = loss.sum()
# backward:自动计算梯度
loss.backward()
# 更新参数
w.data.sub_(lr * w.grad.data)
b.data.sub_(lr * b.grad.data)
# 梯度清零,不清零则会进行叠加,影响下一次梯度计算
w.grad.data.zero_()
b.grad.data.zero_()
if i % 1000 == 0:
# 画图
display.clear_output(wait=True)
x = t.arange(0, 20, dtype=t.float).view(-1, 1)
y = x.mm(w.data) + b.data.expand_as(x)
plt.plot(x.numpy(), y.numpy(), color='red') # 预测效果
x2, y2 = get_fake_data(batch_size=20)
plt.scatter(x2.numpy(), y2.numpy(), color='blue') # 真实数据
plt.xlim(0, 20)
plt.ylim(0, 41)
plt.show()
plt.pause(0.5)
break # 注销这一行,可以看到动态效果

# y = x * 2 + 3
w.data.squeeze(), b.data.squeeze() # 打印训练好的 w 和 b
(tensor(2.3009), tensor(0.1634))
五、总结
本篇文章介绍了 torch 的一个核心——autograd,其中 autograd 中的 variable 和 Tensor 都属于 torch 中的基础数据结构,variable 封装了 Tensor ,拥有着和 Tensor 几乎一样的接口,并且提供了自动求导技术。autograd 是 torch 的自动微分引擎,采用动态计算图的技术,可以更高效的计算导数。
这篇文章说实话是有点偏难的,可以多看几遍,尤其是对于还没有写过实际项目的小白,不过相信有前面几个小项目练手,以及最后一个线性回归的小 demo,相信你差也不差的能看懂,但这都不要紧,在未来的项目实战中,你将会对 autograd 的体会越来越深刻。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


