
数据库用户通常依赖隔离级别来确保数据一致性,但很多数据库却并未达到其所表明的级别。主要原因是:一方面,数据库开发者对各个级别的理解有细微差异;另一方面,实现层面没有达到理论上的要求。
用户在使用或开发者在交付数据库前,需要对隔离级别进行快速的正确性验证,并且希望验证是可靠的(没有误差)、快速的(多项式时间)、有效的(找出异常)、通用的(任意数据库)、可解释的(可以debug,可以复现)。
Elle 就是针对以上问题提出的一个基于 Adya 模型的黑盒一致性检测工具。Elle 通过精心设计的读写操作和版本控制,可以检验出 Adya 提出的所有非谓词异常,并且具有一定可解释性和复现性。在实践中,Elle 在所测的四个数据库上都测出了数据不一致。
探索前沿研究,聚焦技术创新。本期由腾讯云数据库高级工程师陈育兴为大家介绍数据库事务一致性检测的技术原理及相关实现,包括背景、动机、解决方案等内容。
一、背景介绍
1.1 数据异常
我们熟知的数据异常有脏读、脏写、丢失更新等很多种类,如果从数据异常的角度来解释一致性,即一致性是保证不出现数据异常。

我们以一个经典案例数据异常(写偏序(Write Skew))对此进行说明。某用户有两个投资账户,允许其中一个账户暂时亏损,但两个账户总额不能为亏损。转账前两个账户各有$100,两个事务同时开启,A事务查询总余额发现有$200,并在第一个账户取出$200,B事务查询总余额也是$200,并且在第二个账户取$200,两个事务都提交成功。各取出$200、总共取出$400,但按正常理解,超额取钱是不允许的,这种情况就是数据异常。然而这种操作在绝大部分数据库的默认配置中都会出现。
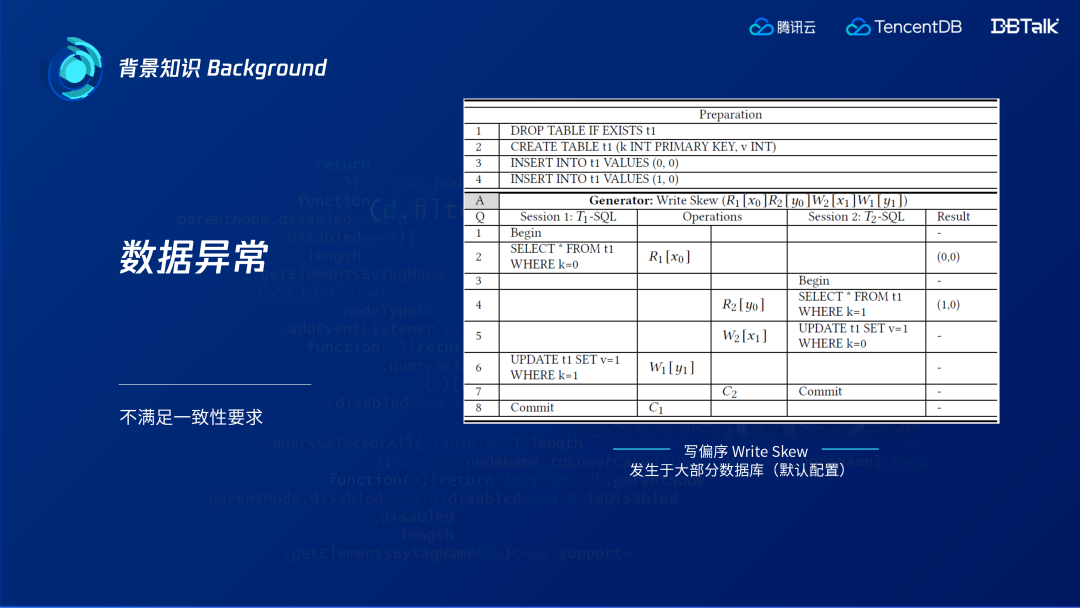
该例子的写偏序的标准测试样例如上图所示:初始数据库有两行数据,两个事务都各自读一行数据,两个事务分别更新对方读的数据,最后两个事务都提交成功,这就是标准的写偏序。这在很多数据库的默认级别和快照级别都会出现,用户通常需要额外的约束或需要数据库开启可串行级别才能避免该异常。
1.2 隔离级别 VS 数据异常
一致性有强弱之分,数据库中满足强/弱一致性需要通过隔离级别来实现。在某些弱级别下,异常的出现被视为正常,因为有些异常在部分业务场景下是可以被接受的。那我们为何要允许数据异常的出现,而不是禁止所有异常出现从而保证正确性?因为正确性和性能之间需要权衡,正确性越高,性能越差,允许一些数据异常,性能也会有所提升。

标准定义下存在四种异常,从P0到P3,逐步禁止,比如P0是脏写,在所有级别中都不允许出现;P1是脏读,在读未提交允许出现,幻读则允许在RR级别下出现;可串行级别理论上不允许任何异常出现。隔离级别越强,允许的异常就越少,且通常隔离级别为逐级叠加,即弱隔离级别不允许出现的异常,在更强的隔离级别也不允许出现。
四种标准的异常只是数据异常中的一小部分,还有更多数据异常的形式。在四种标准的级别之上也有更多的隔离级别。
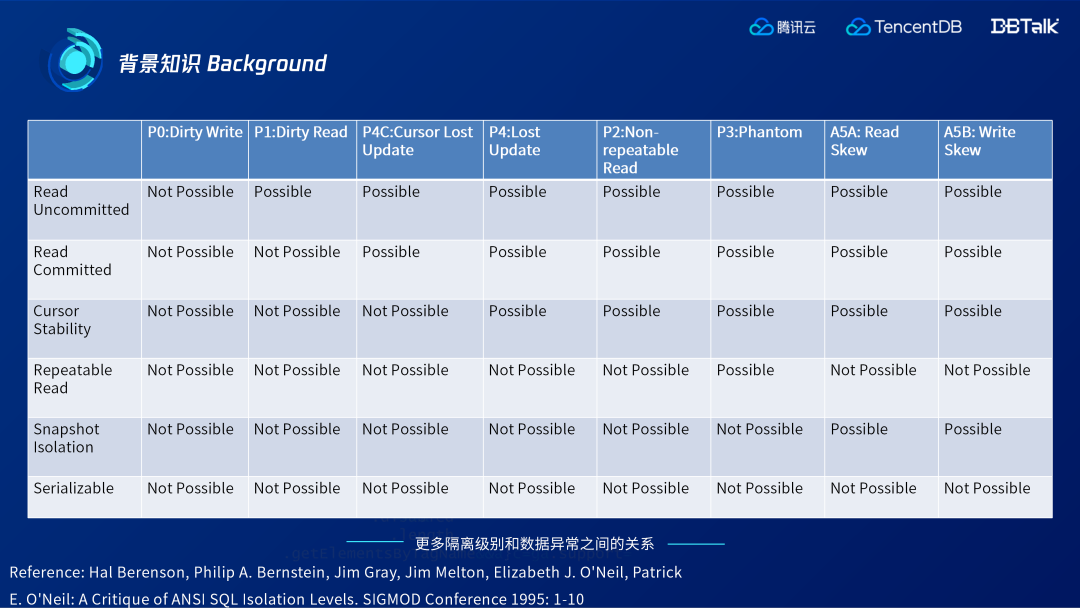
上表显示的是新的异常和新的隔离级别之间的允许/不允许关系,但并非时时刻刻都如此严格。一方面,各厂商的数据库产品会因理解和实现的不同致使部分异常没有按预期出现或禁止。另一方面,上述异常仅仅是一小部分,理论上存在的级别也还有很多。因此很多数据库新用户不知道哪些异常会出现或不应该出现,以及如何去理解这些级别和异常。
二、动机
2.1 非传统隔离级别
下图所示是部分非传统的隔离级别。比较常见的是快照隔离级别,如图所示的部份厂商,从名字上我们无法直接判断这些级别的具体表现,相关文档的描述也比较模糊,因此就会引申出一个问题,即它们应该等价于哪些级别、对比当前级别它们是强或弱。

2.2 用户层面
从用户角度来看,主要存在以下三方面问题:
- 如何针对自身业务选择隔离级别,如何理解这些(新)隔离级别。比如哪些异常允许出现,哪些异常不允许出现?
- 数据库申明的隔离级别没有达到标准。比如Oracle申明支持可串行级别,但它只消除了四种标准的异常,没有消除所有异常,存在写偏序。在串行级别存在写偏序异常,这种申明现象在很多数据库中都会出现。
- 对隔离级别的定义标准不同,不单是可串行级别,其他弱隔离级别也是如此。比如在可重复读级别,PostgreSQL不存在幻读但存在写偏序,SQL Server则不存在写偏序异常但存在幻读。

2.3 厂商层面
从厂商角度来看,主要存在以下两方面问题:
一方面,数据库需要迭代版本,但回归测试样例一般都不完整,只能在一定程度上进行验证。比如PostgreSQL在2011年推出的9.1版本中已经实现可串行化的快照隔离(SSI),但因为某些步骤优化导致在第三方事务插入后马上更新干扰的情况下,出现G2异常(写偏序),正常情况下不应出现,直到2019年推出12.4版本才对此进行修复。
另一方面,厂商需要研发新型事务数据库,需要验证开发的正确性,确保没有缺陷或者没有程序上的bugs影响。

三、解决方案
3.1 Jepsen/Elle事务一致性测试框架
对上述问题,我们可以利用一个事务一致性检测方案——Jepsen/Elle方案进行解决。Jepsen是一个更强大的框架,可以检测分布式一致性、线性一致性等多种一致性级别,Elle是其中的一个事务验证模块,Elle方案目前已经在VLDB 2020会议中发表。

整体来看,Jepsen/Elle事务一致性测试框架的作用如下:
- 测试出各种级别下存在的异常,帮助理解当前级别的表现;
- 通过理解当前级别,可以验证当前隔离级别是否达到要求;
- 测试结果可解释、可溯源、可复现。
3.2 定义数据异常
在解决上述问题之前,我们需要知道如何定义数据异常,以及学术界又如何看待数据库异常。

前文提到最简单的一致性是不存在任何数据异常,但如何判断发生了数据异常呢?比如正常要读提交的值但却读到未提交的写,一个事务两次读但却读到不一样的值,这些能否归为数据异常?其实,这些异常在一定程度上都算是数据异常,只是表述不够正式且无法总结规律,因此我们需要用更规范的方式来定义数据异常。

在判断有无数据异常前,我们需要把数据库执行后的数据抽象地表示出来。Elle方案里采用Adya表示模型,这是一个比较标准通用的表示模型,可以将数据库操作对象以及操作方式抽象出来。比如对象通常有x、y、z, 可以对应不同key,再用R、W、C、A对应读、写、提交和回滚。在数据库执行完操作后,我们把一组事务操作记录下来成为历史(history),调度(schedule)是历史的前缀(prefix)。两者的区别在于,调度里仍有未完成的事务,但历史里全是已完成的事务。
现阶段写偏序的执行可以描述成一个调度,其中读写操作的下角标表示事务,对象的下角标表示版本数。以下图为例,写偏序的调度为:事务1进行了读操作,读取了对象为x的0版本数据,事务2读了对象为y的0版本数据,事务1改了y对象的值,事务2修改了x对象的值。

有了调度和历史的概念后,我们可以去构建冲突图。冲突图是以事务为点、冲突为边的图模型。比如上图右边的写偏序例子,事务1的读和事务2的写作用在同一个对象x上,从版本来看事务1的版本更小、事务2的版本更大,因此存在从事务1到事务2的RW冲突边。同理在y对象上,存在由事务2到事务1的RW边。我们可以看到,该图是一个环结果,我们可以通过环的存在来判断数据异常的存在。因为我们认为串行执行的结果是一个没有问题的数据状态,比如事务1先做,再做事务2,就不会有数据异常,而冲突图有环的情况,其实就是不可串行的执行结果,它的结果不等价于任何一个串行执行的结果。因此,我们认为执行的状态或结果为不可串行的就存在异常。

如果我们把数据库执行转成历史,通过历史去建模冲突图,再去判断冲突图是否有环,就可以轻易判断是否存在数据异常。因为历史或调度模型里可以确定读写版本,从而确定冲突依赖关系,容易做判断。
3.3 问题与挑战
在现实中,数据库执行结果有时很难获取统计,即使可以获取统计,也很难直接转化为确定的历史或者调度。这主要有两方面的问题:一方面,依赖关系有时可能性很多,很难决定;另一方面,如果并发事务较多,不确定的依赖关系就会更多,需要分析和决定的成本很高,导致验证速度慢或可能性太多,内存和计算资源不足以在短时间内验证太多可能性。

数据读写之间的依赖判断存在以下难点:
- 两个事务都对K=1更新值,从两个事务的历史数据无法得知谁先谁后;
- 两个事务都对K=1更新V=5,其他事务读到K=1、V=5时,无法得知是哪个事务的写的数据;
- 事务读写后是否参与冲突依赖判断,需要两个事务在时间上有交叉。但很多分布式时间不可信、不对齐,时间不一定对等;
如果考虑将所有可串行的结果去匹配执行结果,本质上是NP-complete问题,是一个非多项式时间的验证,计算成本非常高。
3.4 Jepsen/Elle解决方案

Jepsen/Elle解决方案首先要保证得到可靠的历史,需要执行结果满足两个特性:
- 可追溯性,需要知道版本之间的顺序,决定ww依赖,谁先写、谁后写需要确认。
- 可复原性,需要知道读的是哪个版本、谁的写,从而决定写读依赖;读写依赖可以根据写写依赖和写读依赖进行推导。

Jepsen/Elle的输入设置分为三种操作:
- 读操作,select语句。
- 插入操作,insert语句。
- 更新操作,update语句。该update语句与普通update不同,需要在更新值时附带原有值,把原有值和更新值都保留。

具体示例如下:首先往t1表里插入新值K=1,V=1。R1读表里的内容,读到k=1、 v=1。W1更新行的内容,让值更新为2。因为更新时我们会将原有值加进来,所以当R2再次读时,我们读到的是k=1,v=“1 2”。以此类推,当再次更新值为3时,我们读到的是“1 2 3”。同一个变量上的更新使其保持唯一则不会有歧义,我们也知道更新版本顺序,再通过读数据,可以轻易推导出这些操作的读写依赖关系。

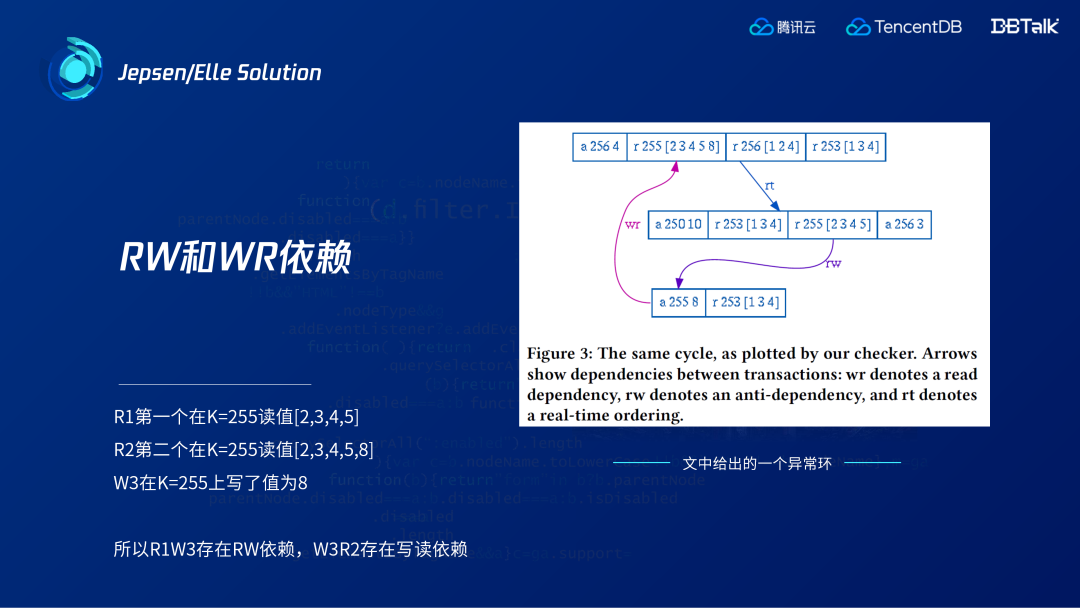
上图是论文中给出的例子。R1中间的事务,读了K=255的值2,3,4,5;R2上面的事务,读了K=255的值为2,3,4,5, 8;W3下面的事务在K=255上写了值为8,我们可以得到从W3到R2的WR依赖和R1到W3的RW依赖,从最上面的事务到中间的时间依赖(real-time 依赖),可以用作严格一致性的判断。

Elle检测模型基本遵循Adya文章定义的环分类,比如G0异常为全是WW边的环,G1c为WW或WR组合的环,加上G-single和G2,这些异常环的组合类似于四种异常现象,所以也有逐步不允许的限制。我们验证隔离级别是否达标,就从最简单的四种异常验证转化为四大类环的检测。

Elle检测可以保证正确性,只要测出异常,则该异常一定存在。只要出现异常,理论上可以复现,也说明数据库在该模型下不一致。另一方面,Elle不能保证完整性,Elle检测后不代表系统完全满足一致性,因为有些异常不能用环表示,比如脏读、脏写、中间读以及有些需要状态确认的异常,Elle也不能检测谓词异常。
Elle通过初期写的特殊处理,所有的依赖关系都是确定性的,通过事务执行结果来判断依赖关系的复杂度,基本上都是线性。我们可以看到,随着并发增大,粉色线的时间基本是平稳线性增长,而传统做法需要比对任意事务之间的顺序,复杂度是阶乘于事务个数,随着并发增大,验证时间为指数增长。

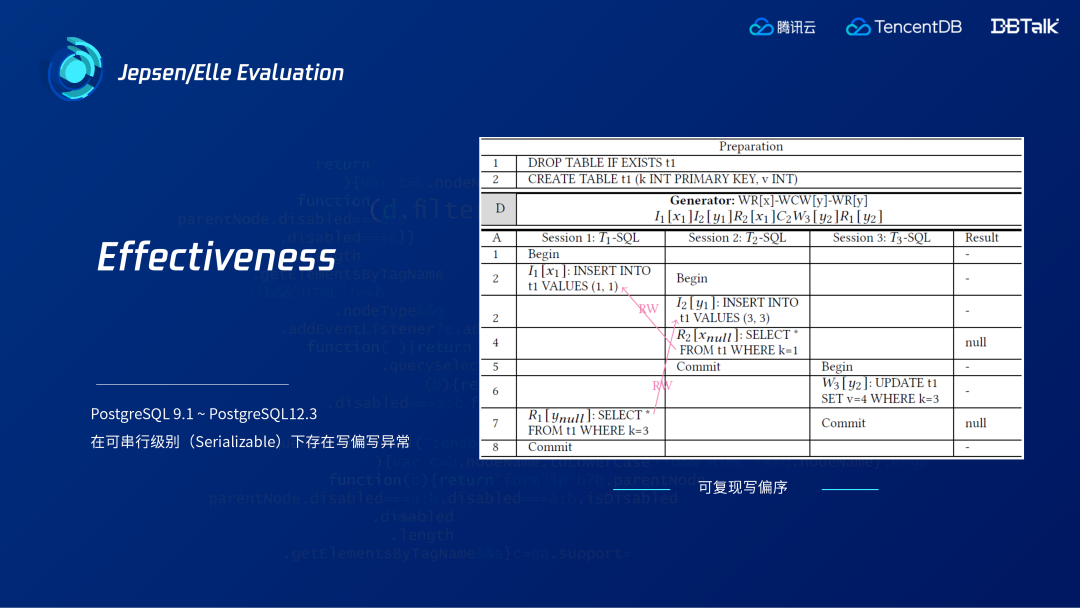
上图是用Elle工具在PostgreSQL老版本上测出的异常,在可串行级别下存在写偏序异常。右边的可复现的例子中, 共有三个事务,两个事务新插入数据,且相互没有读到新插入的数据,从而形成一个写偏序的环。出现该异常的原因是,第三个事务对某个插入进行更新导致后面的读依赖没有作用在插入值上。
3.5 Test on TDSQL

我们在TDSQL上进行测试。结果显示,可串行级别不存在任何异常,RR级别的表现属于快照隔离级别水平。
四、总结
综上所述,Elle事务一致性检测框架主要解决两个问题:
- 通过写版本叠加,在更新时保留旧值,从而确定版本顺序以及把执行结果变为历史调度。
- 通过冲突图的环检测,从历史调度判断有无数据异常。此外,Elle也可通过叠加时间要求来检测严格一致性,比如T2是T1 commit之后才开始的,那么串行执行时必须为T1->T2,不允许出现T2->T1。
上述情况只涉及部分级别,我们还可以根据实际情况细分出更多的级别和一致性模型,用Elle进行更多的验证。

最后,我们还可以从以下四方面对Jepsen/Elle事务一致性测试框架进行优化:
- 框架本身并不简单,需要很多参数调节才能达到效果。比如有些情况压测不充分,小概率异常难于发现,有时不易复现。
- 不支持Delete,不支持谓词范围查询。无法检验幻读(Phantom),无法判别Repeatable Read和Serializable之间的区别。
- 采用新数据格式,而非传统回归测试的SQL语句,分析和debug都比较困难。
- Jepsen有额外错误注入功能,但作者在Elle文章中并没有细说。比如很多异常是因为某些节点重启断联导致的,正常情况下允许并无异常。
参考文献
[1] Atul Adya, Barbara Liskov, Patrick E. O'Neil: Generalized Isolation Level Definitions. ICDE 2000: 67-78
[2] Peter Alvaro, Kyle Kingsbury: Elle: Inferring Isolation Anomalies from Experimental Observations. Proc. VLDB Endow. 14(3): 268-280 (2020)
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!


 客服
客服


