
------------恢复内容开始------------
我们现在学习的机器学习算法,大部分算法的本质都是建立优化模型,通过特定的最优化算法对目标函数(或损失函数)进行优化,通过训练集和测试集选择出最好的模型,所以,选择合适的最优化算法是非常重要的。常见的最优化方法有梯度下降法、牛顿法和拟牛顿法、共轭梯度法,拉格朗日乘数法(约束优化)等等。
本期的主题是牛顿法的详解,为了更好的理解,会简明的说一下梯度下降法的内容。
一、梯度下降法
梯度下降法的本质是,用梯度来进行迭代的方法。即用当前位置的负梯度方向作为搜索方向,可以以理解为切线或者切平面的反方向。因为是切线(切平面),所以此方向为当前位置的最快下降方向。越接近目标值,步长(深度学习中也叫学习率)越小,前进速度越慢。
步长是梯度下降法性能的很重要的因素,步长小,效率低;步长大,容易出现震荡现象。那么当样本数量很大时,可想而知这种迭代速度会非常慢,因此梯度下降法衍生出了随机梯度下降法,批梯度下降法,小批梯度下降法。
在求解机器学习模型参数时,梯度下降法是很常用的方法。当目标函数为凸函数时,局部最优点即为全面据最优点,这也是为什么凸函数在机器学习最优化领域受欢迎的原因 。
二、牛顿法
牛顿法主要有两个应用方向:1、求解方程根的问题。2、目标函数最优化求解
先详细介绍牛顿法的原理,再具体介绍牛顿法的两个应用方向。
前面说过,梯度下降法是用梯度来建立迭代关系式的方法,而牛顿法则是用切线来建立迭代关系式的算法(所以也叫切线法)。牛顿法的迭代过程与梯度下降法有相似之处,只不过是用切线与x轴的交点来作为下一轮迭代的起点,如下图所示。第一次迭代是从f(x0)开始,沿着切线的相反方向一直前进到与x轴的交点x1处。第二次迭代从点x1的值f(x1)开始,前进到f(x1)处的切线与x轴的交点x2处。如此持续进行,逐步逼近x*点。需要注意的是,牛顿法是用来求解方程的,因此f(x)与x轴必须有交点x*,这是牛顿法应用的前提。

上述求切线交点的过程,也可以看作是近似的泰勒展开过程。把f(x)在x0处展开成泰勒级数f(x)=f(x0)+(x-x0)f'(x0)+......。在x0附近出取线性部分g(x)作为f(x)的近似,将g(x)与x轴的交点近似作为f(x)与x轴的交点,通过一次次近似来逼近方程的根的过程。所以,牛顿法的本质是泰勒展开。
1、用牛顿法求方程的根
一阶泰勒公式:f(x) = f(x0)+(x-x0)f'(x0)+o( (x-x0)^2 )
取线性部分
-------->x(1)=x(0)-f(x(0))/f’(x(0))
-------->x(n+1)=x(n)-f(x(n))/f'(x(n))
Until…
可以看出,在求解方程根时,只用到了一阶收敛。而在解决最优化问题中,二阶收敛才是牛顿法的精髓所在。
2、目标函数用于最优化求解
在机器学习领域中,牛顿法常用来解极值问题。牛顿法最初时为了求解方程的根,不能直接用来求极值。但是,函数极值的一阶导数为0,因此,可以用牛顿法来求解函数一阶导数为0的方程的根,得到极值点。
对于简单的二维函数而言:
二阶泰勒展开:f(x) = f(x0)+(x-x0)f'(x0)+1/2f''(x0)(x-x0)^2+o( (x-x0)^3 )
取线性部分
--------->x(n+1)=xn-f'(x)/f''(x),n=0,1,2….
而对于高维函数而言,同样的道理。
此时f'(xn)为Jacobi(雅克比)矩阵: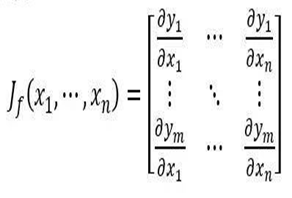
f''(xn)为Hessian矩阵:
牛顿法的精髓就是二阶收敛,不仅利用了损失函数的一阶偏导数,也用到了损失函数的二阶偏导数,即梯度变化的趋势,因此比梯度下降法更快的确定合适的搜索方向,具有二阶收敛速度。通俗点来说,梯度下降法时选择下一步能迈出的最大步长,而牛顿法是在选择下一步能迈出的最大步长的基础上,同时也考虑了下下步的选择方向。也就是牛顿法更加具有大局观(如下图)。
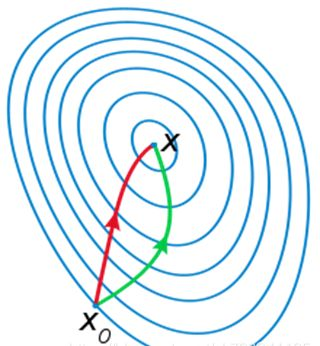
注:红色为牛顿法,绿色为梯度下降法
牛顿法公式(高维):xn+1=xn−[Hf(xn)]^−1*∇f(xn), n=0,1,2….
三、用Rosenbrock函数来测试牛顿法的性能
在数学最优化问题中,Rosenbrock函数是一个用来测试最优化算法性能的非凸函数,也称为香蕉函数。
f(x,y)=(1-x^2)+100(y-x^2)^2.(100可变,但不影响测试)
Rosenbrock函数的每个等高线大致呈抛物线形,其全域最小值也位在抛物线形的山谷中(香蕉型山谷)。很容易找到这个山谷,但是,因为山谷内的值变化不大,所以迭代到最优点是很有难度的。
Rosenbrock山谷
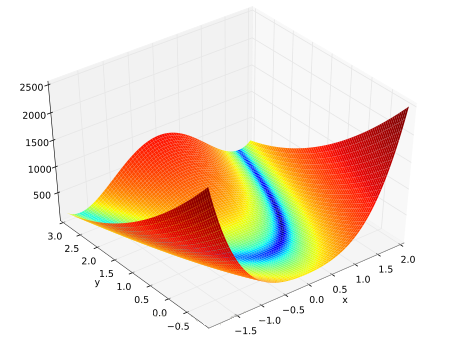
可以看出,我们可以很明显的找到谷底所在山谷。
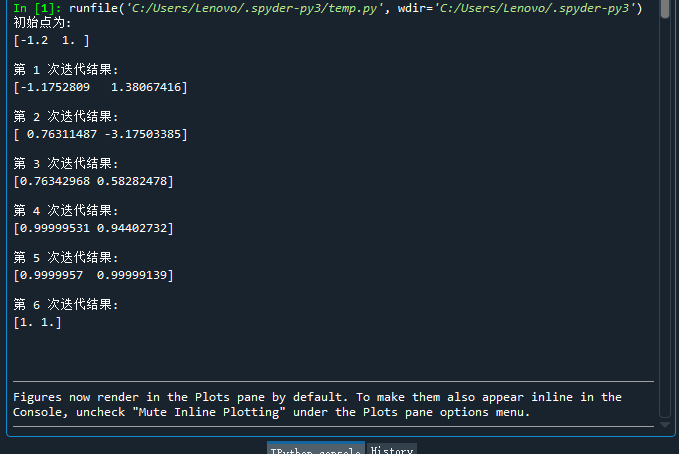
牛顿法用了6次迭代,而相同的起始位置梯度下降法要迭代1000次左右,当然,批梯度和随机梯度效率要高一些。
四、牛顿法的优缺点
优点:
1、二阶收敛,收敛效率高。
2、海森矩阵的逆在迭代过程中不断减小,所以步长也逐渐减小。
缺点:
1、对目标函数有较为严格要求函数必须具有连续的一、二阶偏导数,海森矩阵必须正定。
2、计算相当相当相当复杂。
五、牛顿法在非正定Hessian矩阵的使用
那么问题来了,对于Hessian非正定矩阵来说,牛顿法一定不能使用吗。
答案是不一定的,这就涉及到牛顿法的实际使用情况。刚才我们说的那些是理想下的情况,而在现实中我们使用牛顿法时,尤其是三维四维这种高维度下的情况,求Hessian矩阵的逆矩阵太复杂了。为了在不影响精确度的情况下尽可能简化运算,我们用雅可比矩阵乘以雅可比矩阵的转置来代替Hessian矩阵。具体推导过程如下。(电脑没有这些符号,直接手写了)。
(重点!)

推导过程不需要记住,掌握最后的方法就可以。
六、拟牛顿法
虽然非正定矩阵的问题解决了,但即使这样,雅可比矩阵乘以雅可比矩阵的转置计算仍然复杂。所以又有人提出了牛顿法的改进方法——拟牛顿法。它的本质和牛顿法相同,不同的是使用一个正定矩阵来近似Hessian矩阵的逆矩阵,从而简化了运算的复杂度。拟牛顿法在20世纪50年代由一位美国科学家提出,当时极大的推动了非线性优化这一学科的发展,即使在今天,拟牛顿法也是非线性优化领域最有效的方法之一。
有时间会再出一篇拟牛顿法详解。
------------恢复内容结束------------
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


