
作者|Renan Ferreira
编译|VK
来源|Towards Datas Science
典型的数据科学工作流由以下步骤组成:
确定业务需求->数据获取->数据准备->数据分析->共享数据见解
每一个步骤都需要一套专业知识,这些专业知识可分为:
数据工程师:开发、构建、测试和维护数据管道
数据科学家:使用各种方法建立数据模型(机器学习模型)
数据分析师:获取数据工程师准备的数据,以图形、图表和仪表板的形式从中提取见解(商业智能)
平台管理员:负责管理和支持数据基础设施(DevOps)
Databricks是一个统一的平台,它为每个作业提供了必要的工具。在本文中,我们将通过创建一个数据管道并指出每个团队成员的职责来分析巴西的COVID-19数据。
准备
要完成下一步,你需要访问Databricks帐户。最简单的启动方法是在https://community.cloud.databricks.com
集群创建(平台管理员)
第一步是配置集群。Databricks是一个基于Spark的平台,是最流行的大数据分析框架之一。Spark本质上是一个分布式系统。驱动程序是集群的协调器,工作节点负责繁重的工作。
平台管理员负责根据用例、spark版本、worker节点数量和自动调整配置选择适当的虚拟机系列。例如,ETL过程可能需要内存优化的设备,而繁重的机器学习训练过程可能在gpu上运行。
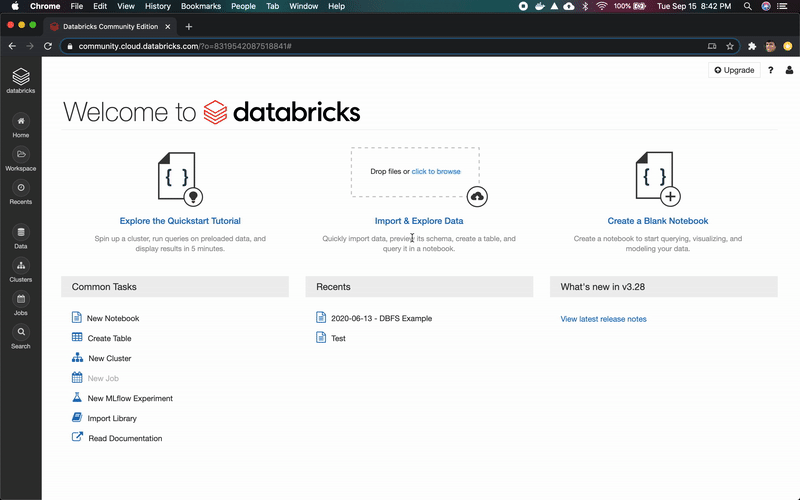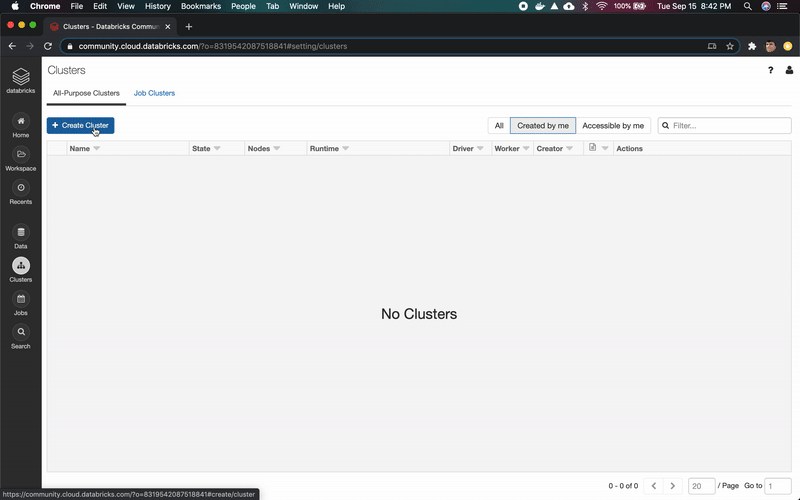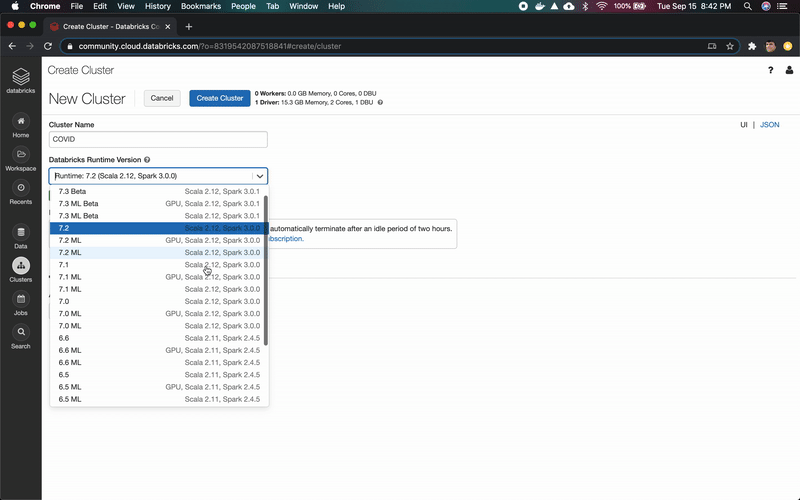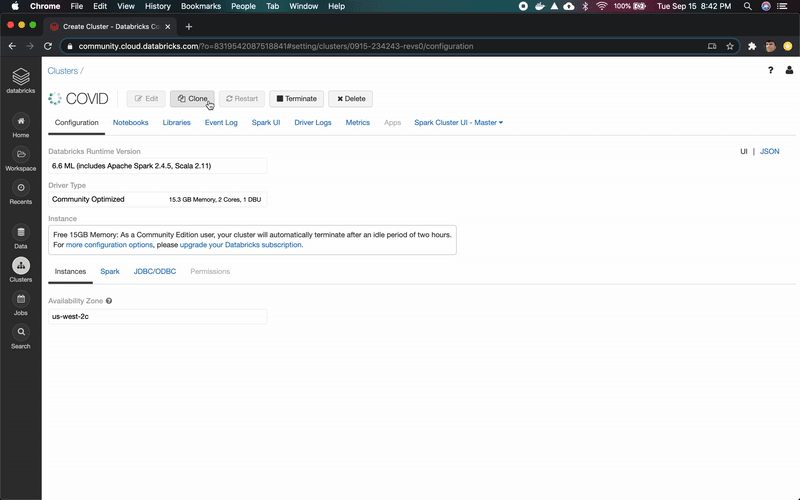
转到Clusters页面,使用6.6ML运行时创建一个新的集群。如果你使用的是 Azure Databricks或AWS,则需要选择驱动程序和worker节点的VM系列。对于本教程,你可以选择最便宜的。
数据获取
数据获取可能是一个具有挑战性的领域。通常,公司将数据存储在多个数据库中,而现在数据流的使用非常普遍。幸运的是,Databricks与Spark和Delta-Lake相结合,可以帮助我们为批处理或流式ETL(提取、转换和加载)提供一个简单的接口。
在本教程中,我们将从最简单的ETL类型开始,从CSV文件加载数据。
首先,我们需要下载数据集。访问以下网址:
https://github.com/relferreira/databricks-tutorial/tree/master/covid
下载文件caso.csv.gz
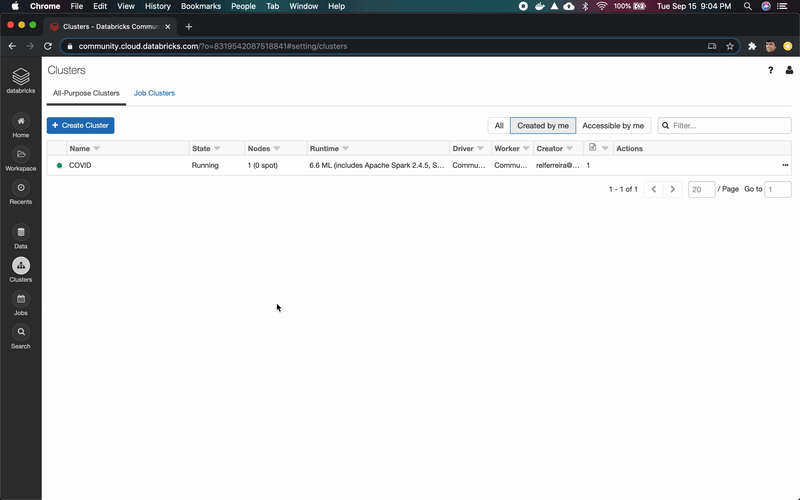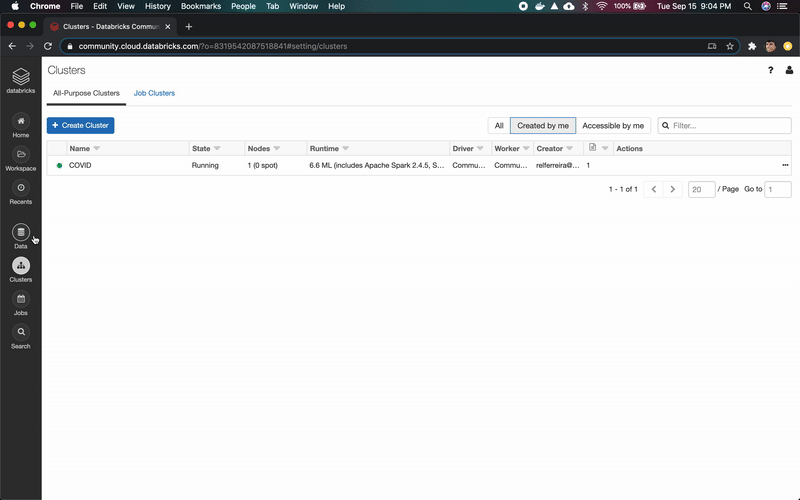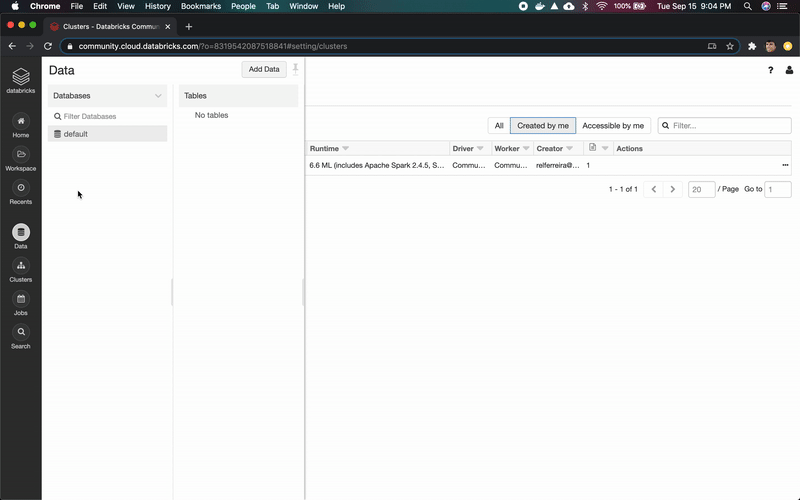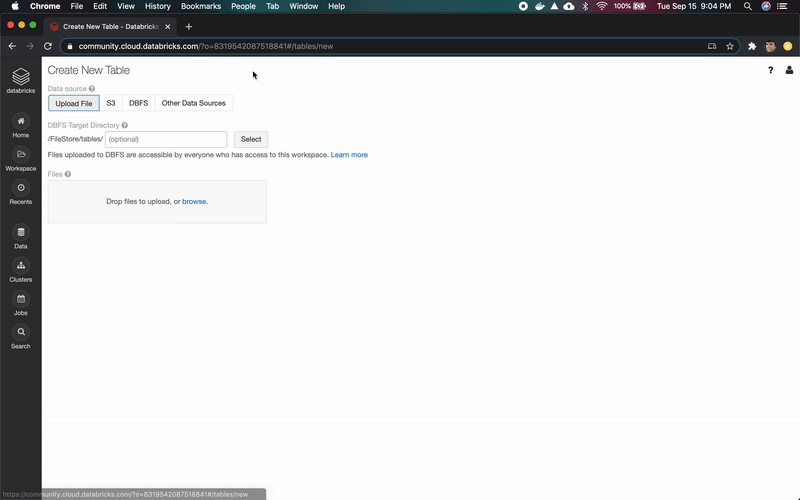
解压缩该文件,访问“数据”菜单,然后单击“添加数据”按钮。接下来,上传先前下载的CSV文件。
上传完成后,我们将使用数据集中显示的信息创建一个新表。单击Create Table UI,将表重命名为covid,将第一行设置为标题,最后单击Create按钮。
数据分析
创建了表之后,我们就可以开始分析数据集了。首先,我们需要创建一个新的python notebook。
Worspace > Users > YOUR EMAIL
单击箭头并创建一个新的Notebook
尽管Databricks是一个python Notebook,但它支持Notebook内的多种语言。在我们的例子中,我们将主要使用SparkSQL。如果你熟悉SQL,SparkSQL会让你感觉像家一样。
让我们从查看新表开始:
%sql
SELECT * FROM covid
你应该看到这样的表:
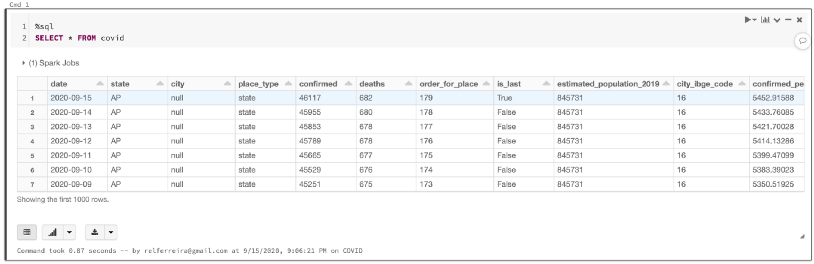
作为数据分析员,你应该能够提取有关数据的有价值的信息。首先,我们需要理解表中每一列的含义。一种方法是使用DESCRIBE函数:
%sql
DESCRIBE covid
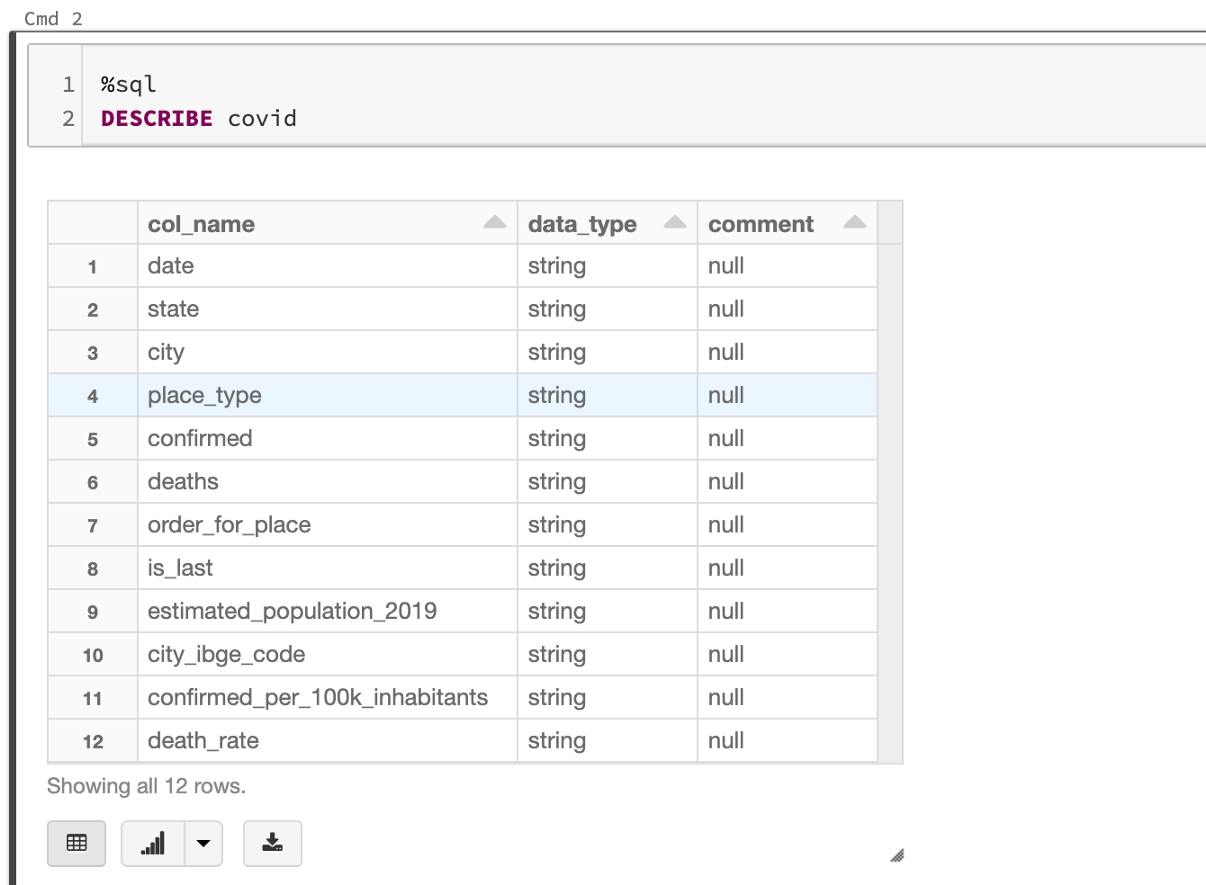
通过分析这两个表,我们可以推断出,当列place_type为state时,每一行表示该state的总数。让我们试着画出人口最多的三个州的死亡人数的演变:
%sql
SELECT date, state, deaths FROM covid WHERE state in (“MG”, “RJ”, “SP”) and place_type = “state”
单击Bar Chart按钮,Plot选项,并对Line chart使用以下配置:
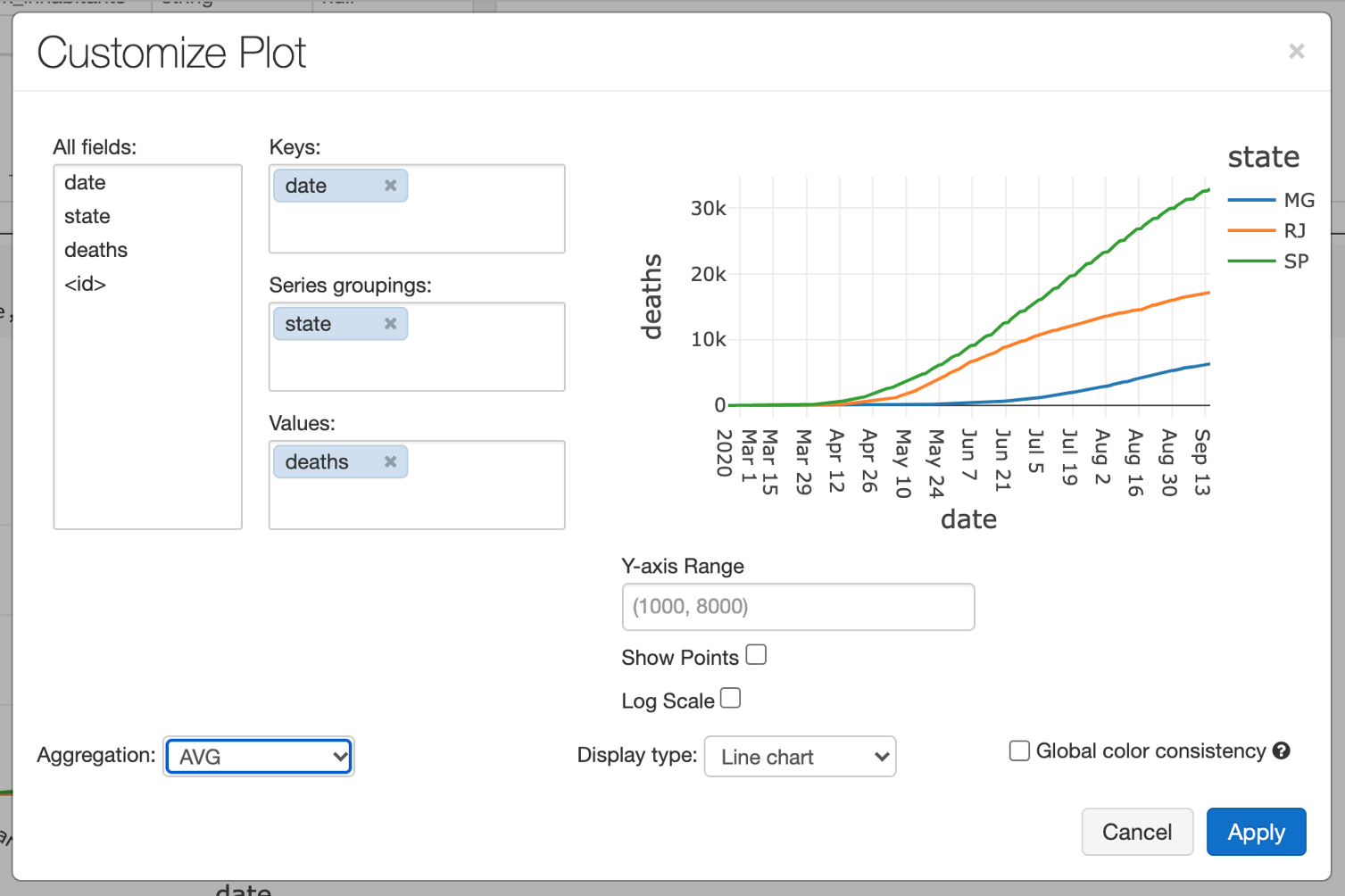
现在我们有了大流行期间死亡人数演变的一个很好的代表。例如,我们可以将此图嵌入仪表板,以提醒这些州的人口。
数据科学
接下来,我们将尝试预测先前绘制的时间序列的未来值。为此,我们将使用一个名为Prophet的Facebook库
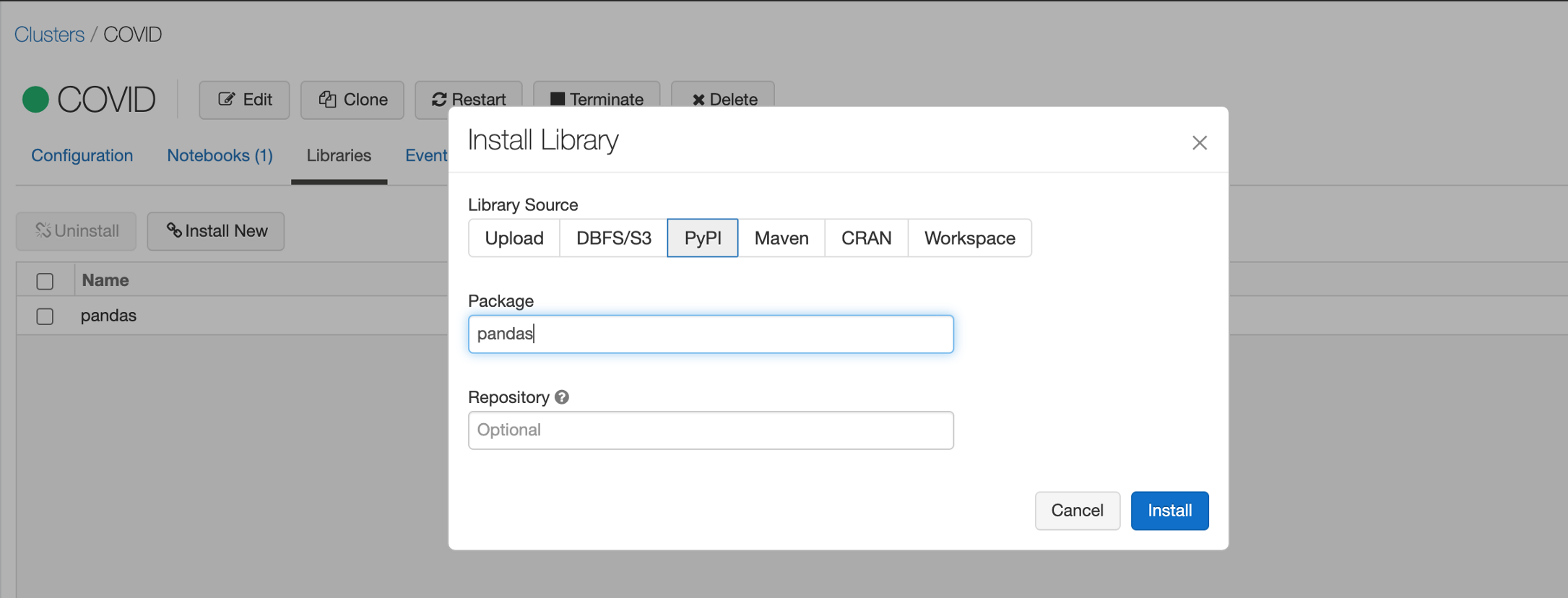
首先,我们需要安装一些依赖项。
Clusters > COVID > Libraries
并使用PyPI安装以下依赖项
- pandas
- pystan
- fbprophet
我们将尝试预测Minas Gerais(MG)未来的死亡人数。所以第一步是收集我们的数据。
也许你需要清除你Notebook的状态
import pandas as pd
import logging
logger = spark._jvm.org.apache.log4j
logging.getLogger("py4j").setLevel(logging.ERROR)
query = """
SELECT string(date) as ds, int(deaths) as y FROM covid WHERE state = "MG" and place_type = "state" order by date
"""
df = spark.sql(query)
df = df.toPandas()
display(df)
接下来,我们将使用Prophet拟合模型并最终绘制预测
from fbprophet import Prophet
m = Prophet()
m.fit(df)
future = m.make_future_dataframe(periods=30)
forecast = m.predict(future)
fig1 = m.plot(forecast)
你应该看到下面的图表和预测:

结论
我们的目标是演示数据科学工作流的所有步骤。这就是为什么我们没有描述时间序列模型是如何工作的。如果你遵循本教程,你应该对Databricks平台有一个很好的了解。
此公共存储库中提供了完整的Notebook:https://github.com/relferreira/databricks-tutorial
原文链接:https://towardsdatascience.com/getting-started-with-databricks-analyzing-covid-19-1194d833e90f
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


