
3.1 程序编码
机器代码中可以看到对程序员隐藏的处理器状态:
- 程序计数器(PC,在x86-64中用%rip表示)给出执行的下一条执行在内存中的地址
- 整数寄存器文件包含16个命名的位置,分别存储64位的值
- 条件吗寄存器保存着最近执行的算数或逻辑指令的状态信息,实现控制或数据流中的条件变化
- 一组向量寄存器可以存放一个或多个整数或浮点数值
每个程序都是在虚拟内存中寻址的,只有有限的一部分虚拟地址被认为是合法的,通常一个经典的程序徐只会访问几兆或几千兆字节的数据。
假设写一个非常简单的代码包含如下定义,一个求和函数。接下来使用gcc -o2 -c code.c进行编译,就可以看到产生的仅编译而没有进行链接汇编代码code.o
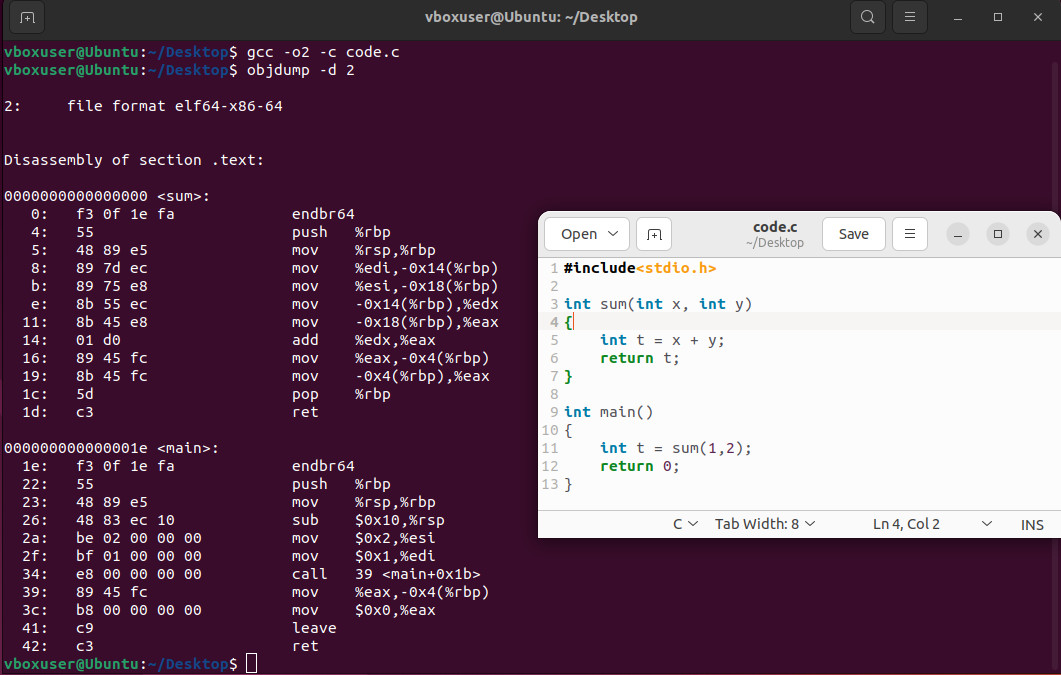
这里可以看到main函数以endbr64起始,首先将当前帧指针保存,然后讲栈指针移动到帧指针的位置,最后将栈指针下移,形成了新的空间用于传参,接下来将立即数放到了寄存器里,并调用函数,但此时调用函数还没有给定地址,因为还没有进行链接。这里面-0x14(%rbp)是说相对于帧指针向上移动0x14个字节的地址位置,参数在内存中存储都是相对于帧指针的
![]()
接下来使用gcc code.c -o code指令生成可执行文件code,并反编译该可执行文件
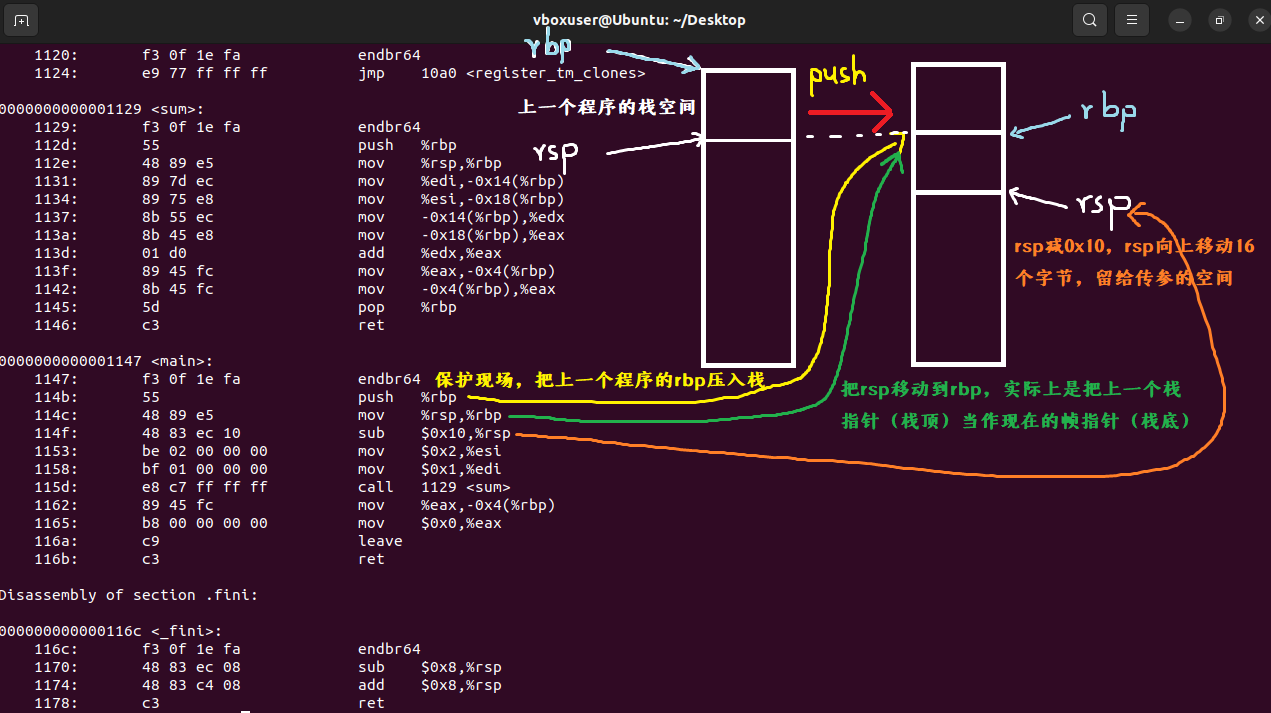
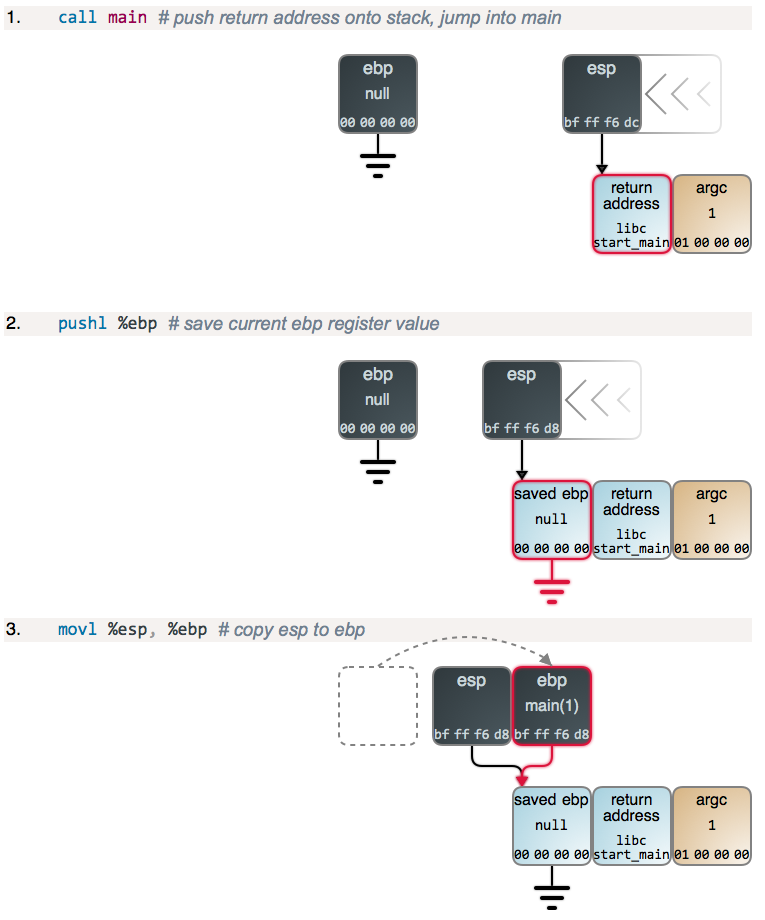
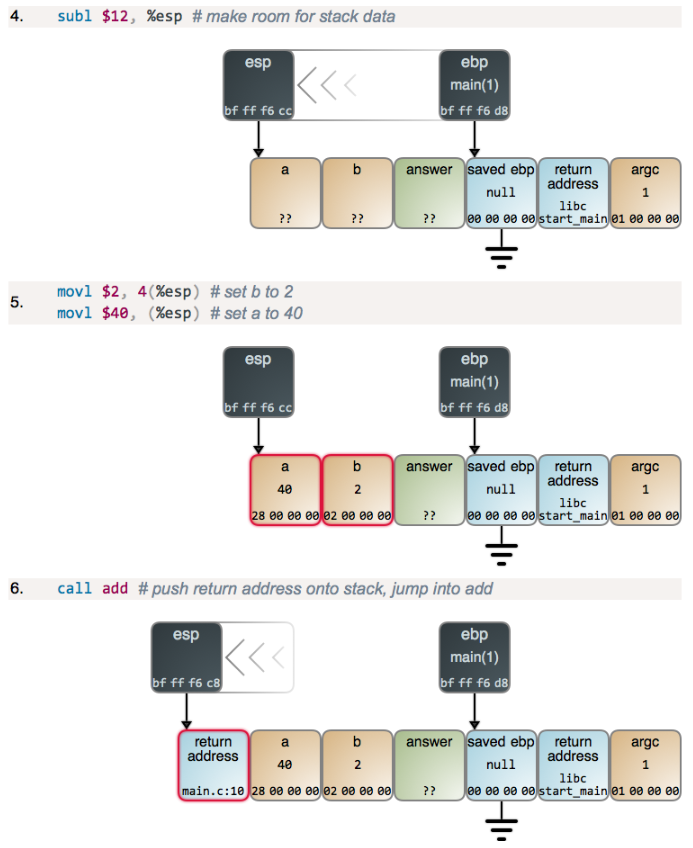
下面是一个函数调用过程中栈到底压入和弹出详细过程的图
int add(int a, int b) { int result = a + b; return result; } int main(int argc) { int answer; answer = add(40, 2); }

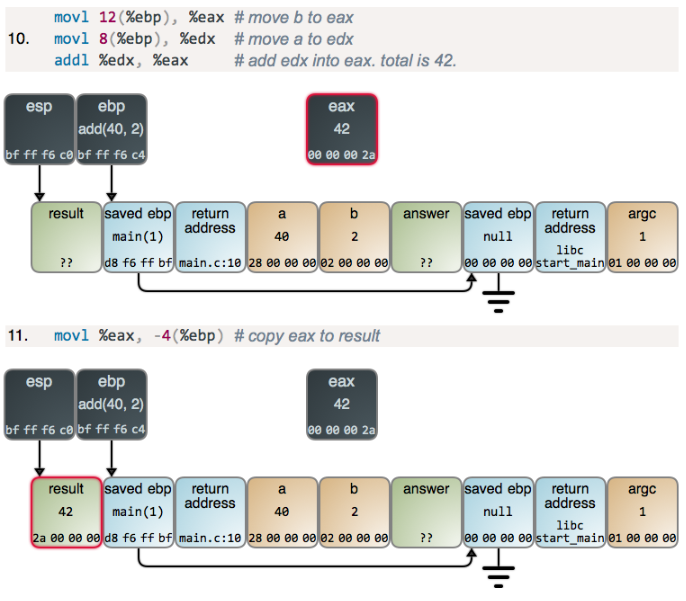
3.2 访问信息
一个x86-64处理器包括16个存储64位值的通用寄存器,用这些寄存器存储整数数据和指针。下图显示了这些个寄存器。

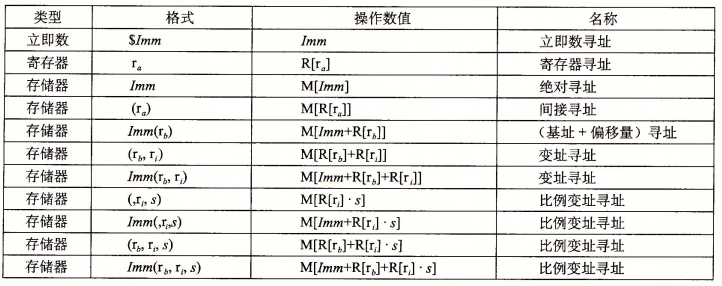
3.2.1 操作数指示符
大多数指令有一个或多个操作数(operand),指出执行操作的源数据值和存放结果的目标位置。
- 立即数(immediate),也就是常数值,可以直接使用的数,不是从存储器中读出的。任何32位的数都可以用作立即数,汇编器在可能时会用一个或两个字节编码,书写方式是$后跟一个整数,例如$0x1F
- 寄存器(register),它表示某个寄存器的内容,对于双字操作数来说,可以是8个32位寄存器种的一个(如%eax),对于字节操作数来说,可以是八个单字节操作数中的一个(如%al)
- 存储器引用(memory),根据计算出来的有效地址访问存储器位置
3.2.2 数据传送指令
最频繁使用的指令是数据传送的指令,下表给出了一些例子,第一个是源操作数,第二个是目的操作数。原操作可以是立即数、寄存器中的数或者存储器中的数,IA32中规定了两个操作数不能都指向存储器,也就是从存储器的一个位置拷贝到另一个位置需要两条指令完成
| movl $0x4050, %eax | immediate -> register | movl S, D 传送双字 | pusbl S 压栈双字 | |
| movl %ebp, %esp | register -> register | movw S, D 传送字 | popl D 出栈双字 | |
| movl (%edi, %ecx), %eax | memory -> register | movb S, D 传送字节 | ||
| movl %-17, (%esp) | immediate -> memory | movsbl S, D 传送符号扩展的字节(单字节扩展到32位补符号位) | ||
| movl %eax, -12(%ebp) | register -> memory | movzbl S 传送零扩展的字节(单字节扩展到32位补0) | ||

对于出栈和入栈,所有程序都是在存储器的栈中保存的。如果我们将一个双字值压入栈则需要将指针减4,然后将值写道新的栈顶地址。所以pushl %ebp实际上等价于subl $4, %esp和movl %ebp, (%esp)这两条指令,而popl %eax实际上等价于movl (%esp), %eax和addl $4, %esp。无论如何,%esp指向的地址永远是栈顶
3.3 算术和逻辑操作
下表列出了一些操作,包括加载有效地址(读入的不是数据,而是该数据的有效地址),一元操作(例如incl(%esp)会使栈顶元素加一),二元操作(例如subl %eax, %edx会让前寄存器的值减后寄存器的值并存在后面的寄存器),移位操作等
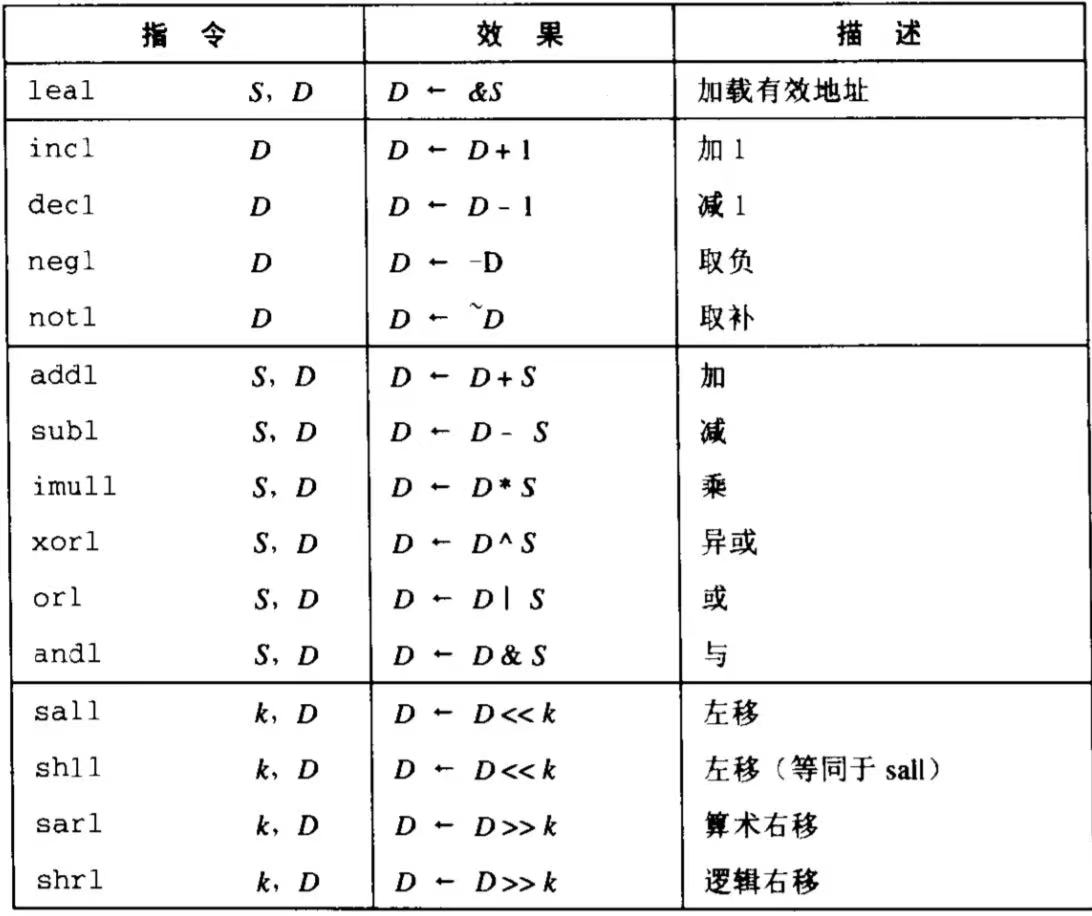

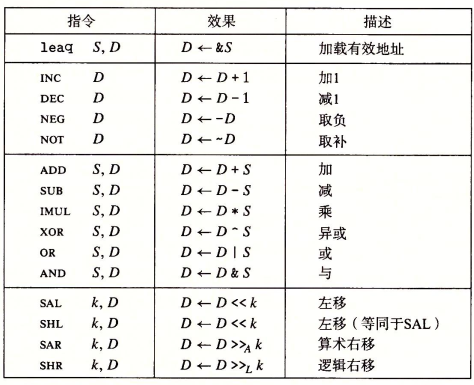

加载有效地址(load effective address)lea指令可以很灵活的实现将有效地址写入操作数,例如假设%rdx寄存器中存储的值位x,leaq 7(%rdx, %rdx, 4), %rax的含义是将寄存器%rax的值设置为x+4x+7
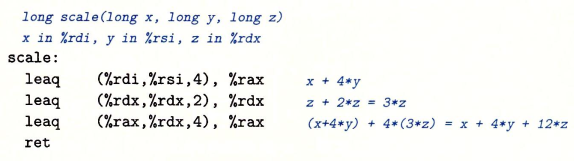
3.4 控制
程序默认的方式是顺序控制流,按照语句或指令在程序中出现的顺序来执行,但类似于条件语句、循环语句等也允许控制按照非顺序的方式执行
3.4.1 条件码
除了整数寄存器,CPU还包含一组单个位的条件码(condition code)寄存器,描述了最近的算术或逻辑操作的属性,这些检测有助于执行分支条件,举例有
- CF进位标志(最近的操作使最高位产生了进位)
- ZF零标志(最近得到的结果是0)
- SF符号标志(最近得到的结果是负数)
- OF溢出标志(最近的操作导致二进制补码正溢出或负溢出)
例如使用addl指令完成表达式 t = a + b
- CF:(unsigned t) < (unsigned a) 无符号溢出
- ZF:( t == 0) 零
- SF:( t < 0 ) 负数
- OF:( a < 0 == b < 0) && ( t < 0 != a < 0 ) 有符号溢出
有一些指令只设置条件码而不改变其他寄存器的值,例如CMP S1, S2指令,他与SUB指令是相同的,做减法,如果S1和S2的值相等则会将ZF零标志设置为1
3.4.2 访问条件码
一般情况下条件码不会直接读取,而是
1)通过某种组合将一个字节设置为1或者0
2)跳转到程序的其他位置
3)有条件的传送数据。用如下代码举例,cmp指令会根据两个寄存器的值设置条件码寄存器的值,接下来setl指令是根据条件寄存器的值确定的,如果是小于号就将%al寄存器中设置为1,最后movzbl不仅会清空%eax高3字节的值,还会把整个%rax高4字节的值清空

3.4.3 跳转指令
正常情况下程序一般是顺序执行的,跳转指令会导致程序切换到一个全新的位置,在汇编代码中通常用一个标号指明。除了jmp .L1这种根据标签直接跳转之外,也可以间接跳转,例如jmp *%rax表示从%rax寄存器中读出地址并跳转,而jmp *(%rax)表示从寄存器中读出内存的地址,并根据内存中读出的地址跳转,下表列出了一些有条件跳转指令
3.4.4 跳转指令的编码
跳转指令根据读取跳转地址的方式分为直接跳转和间接跳转,根据编码方式分为相对跳转地址和绝对跳转地址,下面举例了最常见的相对跳转
PC读到0x3位置的指令后自增指向0x5,同时读取到jmp指令是相对跳转0x03个地址,所以此时PC指向0x5+0x3也就是0x8的地址
当PC读到0xb位置的指令后自增指向0xd的位置,接下来解析指令jg跳转,0xf8是补码表示,十进制是-8,将0xd+0xf8得到0x5的地址

3.4.5 用条件控制实现条件分支
将条件表达式从c语言翻译成汇编代码,最常见的是结合有条件和无条件跳转,如果判断成立,程序沿着一条执行路径执行,不成立则执行另一条路径,这种方式简单易用,但可能在现代处理器非常低效


3.4.6 用条件传送实现条件分支
相较于3.4.5提到的方式,一种替代策略是使用数据的条件转移。这种方法计算一个条件操作的两种结果,然后再根据条件是否满足从中选取一个,只有在一些受限制的情况下这种策略才可行。
如下图所示的代码,相对于3.4.5中的区别是没有修改lt_cnt或ge_cnt的值。汇编后首先分别计算了y-x和x-y的值,并分别存储在%rax和%rdx这两个寄存器中,接下来比较了x和y的值,如果x>=y的话就把%rdx的值移动到%rax,否则不做移动,最后返回%rax的值

为什么这样会实现性能提升:处理器通过使用流水线获得高性能,在流水线中,一条指令的处理要经过一系列阶段,每个阶段执行所需操作的一小部分(例如从内存取指令、确定指令类型、从内存读数据、执行算术运算、向内存写数据、更新计数器)。这种方法通过重叠连续指令来获得高性能。例如在取指令的同时,执行它前面一条算数运算,要做到这一点,首先要知道接下来要执行的指令序列,但遇到跳转时需要等待分支条件求值结束,才能决定下一条指令是哪条。下图列举了一些条件传送指令,当满足条件是将S复制到目的R

3.4.7 循环
C语言提供了很多循环结构,但汇编中没有相应的指令存在,可以用条件测试和跳转组合起来实现循环效果
1.do-while循环

2.while循环

3.for循环
for循环与在外层先声明一个变量,然后再使用while循环实际上是一样的
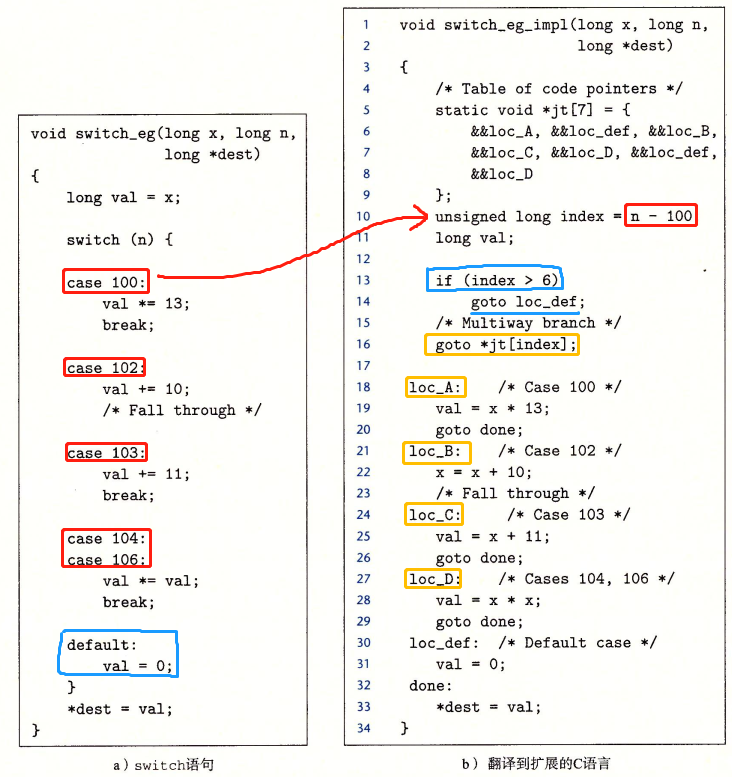
3.4.8 switch语句
switch语句使用跳转表(jump table)这种数据结构可以实现的更高效,跳转表是一个数组,表项 i 是一个代码段的地址,与if-else语句相比,跳转表的优势是执行switch语句的时间与case的数量无关
在下面例子中可以看到,对于对于100,102,103,104,106都有特殊处理,在右侧最上方生成了一张跳转表,分别对应了0,2,3,4,6这几种特殊情况以及1,5这两种默认情况。接下来他对这几个数进行了-100的操作,使得它可以对应到上方的跳转表中。switch语句的关键就是通过跳转表访问代码位置。
3.5 过程
3.5.1 运行时栈和转移控制
过程是软件中很重要的一种抽象,提供了一种封装代码的方式,用一组指定参数和一个可选的返回值实现某种功能。例如函数、方法、子例程、处理函数等。假设P调用过程Q,Q执行后返回到P,机器必须支持下面这些机制。运行时栈的栈尾是被保存的寄存器,中间是局部变量,栈顶是参数构造区
- 传递控制:在进入过程Q的时候,程序计数器必须被设置为Q的起始地址,返回的时候要把计数器设置为P中调用Q后面那条地址
- 传递数据:P能够向Q提供一个或多个参数,Q必须能够向P返回一个值
- 分配和释放内存:在开始时,如果寄存器空间不够,可能需要为Q分配局部变量的空间,返回前要释放这些空间
在程序转移时,调用call指令将返回地址A压入栈,接下来将PC设置为该过程的起始地址,对应指令ret会弹出地址A,并把PC设置为A,下图给出了一个详细说明传递控制的例子。

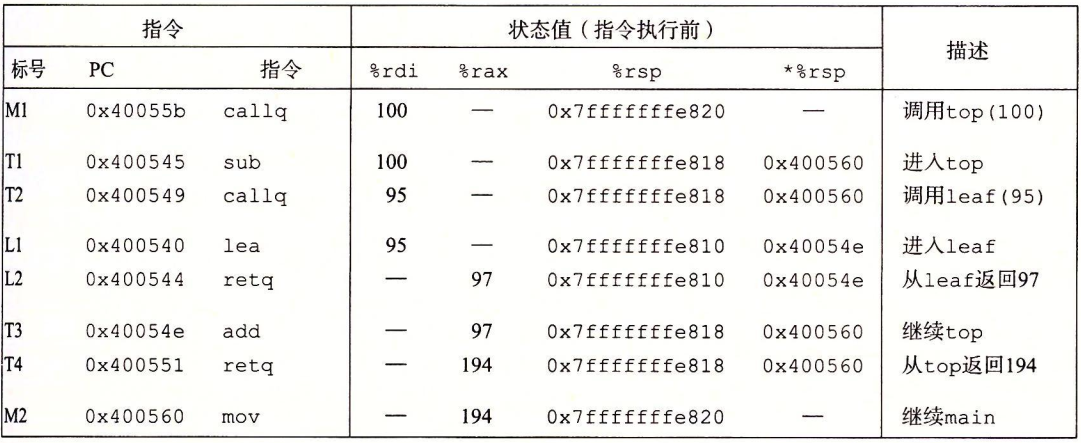
执行指令前的状态值前三列可以看到%rdi、%rax和%rsp的内容,可以观察到在这里%rdi用于传值,而%rax用于返回值,栈顶指针经过几次压栈和回弹后最终回到了最初始的位置
我们看到的大多数程序都不需要超出寄存器大小的本地存储区域,不过有些时候局部数据必须存储在内存中,常见的包括:
- 寄存器不足够存放所有本地数据
- 对某一个局部变量使用地址运算符”&“,必须产生一个地址
- 某些局部变量是数组或结构,必须通过索引被访问
3.5.2 栈上的局部存储

这里汇编第2行将栈指针下移开辟了一块空间,接下来2到15行是在为调用proc做准备,其中3到6行在栈上分配了局部变量x1到x4,用leaq生成了这些位置的指针(7、10、12、14行),参数7(立即数4)和参数8(指向x4的指针)在栈顶,偏移量分别为0和8。
3.5.3 寄存器中的局部存储空间
寄存器组是唯一被所有过程共享的资源,寄存器在给定时刻只有一个过程活动,但必须保证当过程调用另一个过程时,被调用者不会覆盖稍后使用的寄存器的值。
根据惯例,寄存器%rbx、%rbp和%r12~%r15划分为被调用者保存寄存器。过程P调用过程Q的时候,Q必须保存这些寄存器的值,保证它们的值在Q返回到P时与Q被调用时是一样的。
所有其他的寄存器,除了栈指针%rsp寄存器,都分类为调用者保存寄存器。这意味着任何函数都可以修改它们,保护好这个寄存器是调用者P的责任,比如使用push %某个寄存器将值保存到栈中。
3.5.4 递归过程
寄存器和栈的特性使得它可以递归的调用自身,每个过程调用在栈中都有自己的私有空间,多个未完成的过程互不影响
3.6 数组和指针
3.6.1 基本原则
如果E是int数组,我们想计算E[i],E的地址保存在%rdx中,而i的地址保存在%rcx中,使用指令mov (%rdx, %rcx, 4) %eax可以自动计算出e+4i的地址并读出数据放到%eax寄存器中
3.6.2 指针运算
操作符 '&' 和 '*‘ 可以产生指针和间接引用指针,也就是对于某个对象的表达式 Expr,&Expr 给出的是该对象地址的一个指针,对于表达地址的表达式 AExpr,*AExpr 给出该地址的值。因此 Expr 与 * & Expr 是等价的。下表假设了一个数组E和索引i,分别放在%rdx和%rcx寄存器中

3.6.3 嵌套数组的数据形式

3.6.4 定长和变长数组
(略,书中3.8.3和3.8.4)
3.7 内存引用越界举例
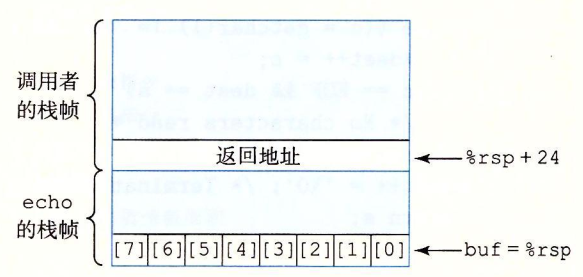
在内存中声明一个字符数组长度为8,反编译可以看到在内存中分配了一小块空间,但是由于c本身不进行越界检查,所以实际上可以给这个字符数组赋更长的值,如果输入0-7长度的字符就没有问题,如果输入8-23的长度,会破坏未使用的栈空间,如果长度大于24会破坏栈空间中保存的返回地址,如果继续增加长度还会破坏调用者的栈帧。所以运气好的话,超出数组长度一点点好像也不会有什么问题,但实际上是有错误的。
参考文献
深入理解计算机系统(第三版)
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


