
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~
1. Google的DQN论文
2015年2月,Google在Nature上发表了一篇论文(见附件):Human-level control through deep reinforcement learning。文章描述了如何让电脑自己学会打Atari 2600电子游戏。
Atari 2600是80年代风靡美国的游戏机,总共包括49个独立的游戏,其中不乏我们熟悉的Breakout(打砖块),Galaxy Invaders(小蜜蜂)等经典游戏。Google算法的输入只有游戏屏幕的图像和游戏的得分,在没有人为干预的情况下,电脑自己学会了游戏的玩法,而且在29个游戏中打破了人类玩家的记录。
Google给出的深度络架构图如下:
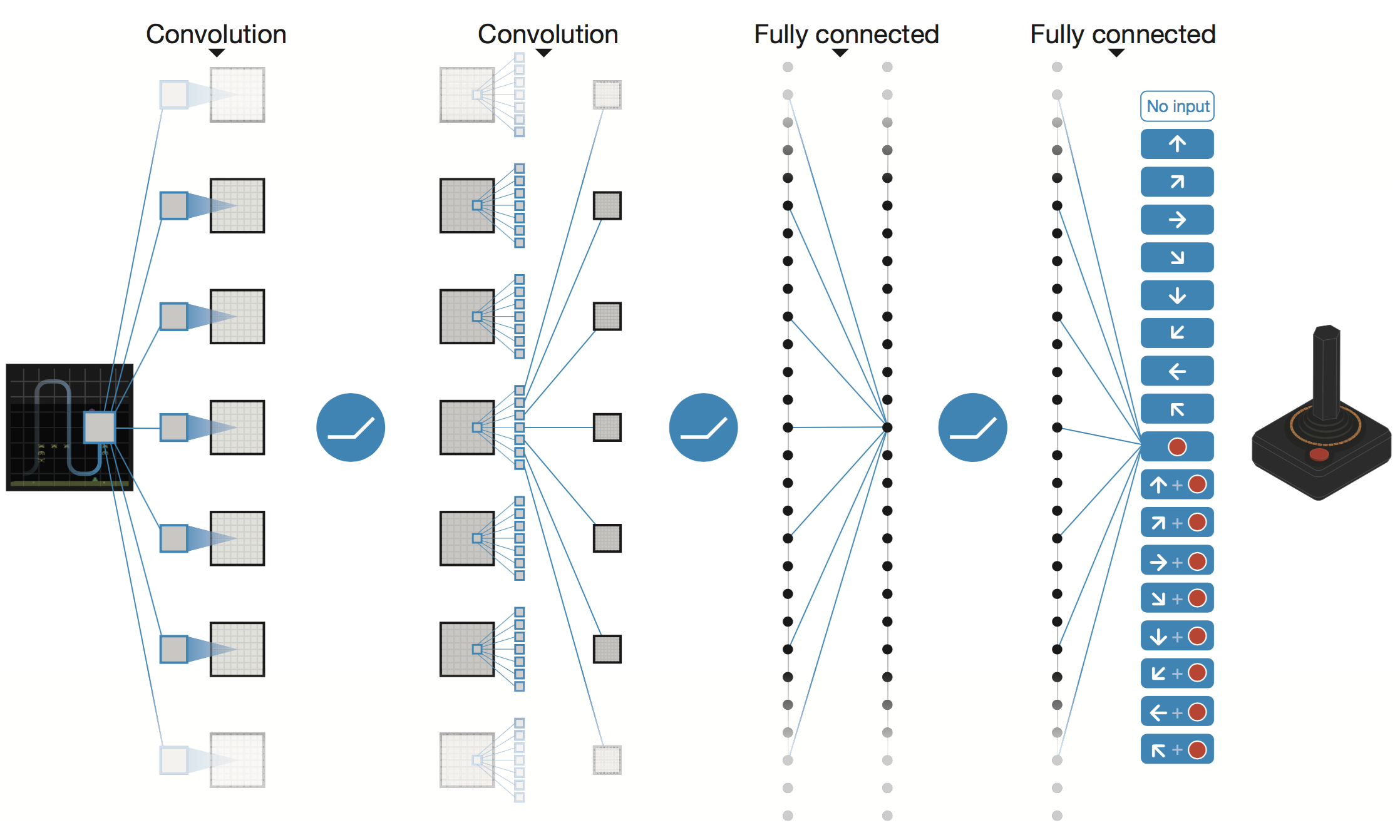
网络的左边是输入,右边是输出。 游戏屏幕的图像先经过两个卷积层(论文中写的是三个),然后经过两个全连接层, 最后映射到游戏手柄所有可能的动作。各层之间使用ReLU激活函数。
2. 强化学习(Q-Learning)
根据维基百科的描述,强化学习定义如下:
强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。
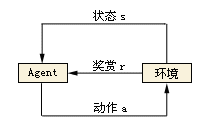
在强化学习的世界里, 算法称之为Agent, 它与环境发生交互,Agent从环境中获取状态(state),并决定自己要做出的动作(action).环境会根据自身的逻辑给Agent予以奖励(reward)。奖励有正向和反向之分。比如在游戏中,每击中一个敌人就是正向的奖励,掉血或者游戏结束就是反向的奖励。
2.1. 马尔可夫决策过程
现在的问题是,你如何公式化一个强化学习问题,然后进行推导呢?最常见的方法是通过马尔可夫决策过程。
假设你是一个代理,身处某个环境中(例如《打砖块》游戏)。这个环境处于某个特定的状态(例如,牌子的位置、球的位置与方向,每个砖块存在与否)。人工智能可以可以在这个环境中做出某些特定的动作(例如,向左或向右移动拍子)。
这些行为有时候会带来奖励(分数的上升)。行为改变环境,并带来新的状态,代理可以再执行另一个动作。你选择这些动作的规则叫做策略。通常来说,环境是随机的,这意味着下一状态也或多或少是随机的(例如,当你漏掉了球,发射一个新的时候,它会去往随机的方向)。
状态与动作的集合,加上改变状态的规则,组成了一个马尔可夫决策过程。这个过程(例如一个游戏)中的一个情节(episode)形成了状态、动作与奖励的有限序列。
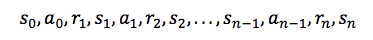
其中 si 表示状态,ai 表示动作,ri+1 代表了执行这个动作后获得的奖励。情节以最终的状态 sn 结束(例如,「Game Over」画面)。一个马尔可夫决策过程基于马尔可夫假设(Markov assumption),即下一状态 si+1 的概率取决于现在的状态 si 和动作 ai,而不是之前的状态与动作。
2.2. 折扣未来奖励(Discounted Future Reward)
为了长期表现良好,我们不仅需要考虑即时奖励,还有我们将得到的未来奖励。我们该如何做呢?
对于给定的马尔可夫决策过程的一次运行,我们可以容易地计算一个情节的总奖励:
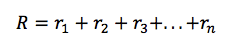
鉴于此,时间点 t 的总未来回报可以表达为:
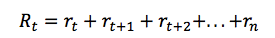
但是由于我们的环境是随机的,我们永远无法确定如果我们在下一个相同的动作之后能否得到一样的奖励。时间愈往前,分歧也愈多。因此,这时候就要利用折扣未来奖励来代替:
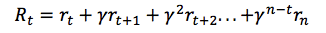
在这里 γ 是数值在0与1之间的贴现因子——奖励在距离我们越远的未来,我们便考虑的越少。我们很容易看到,折扣未来奖励在时间步骤 t 的数值可以根据在时间步骤 t+1 的相同方式表示:
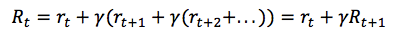
如果我们将贴现因子定义为 γ=0,那么我们的策略将会过于短浅,即完全基于即时奖励。如果我们希望平衡即时与未来奖励,那么贴现因子应该近似于 γ=0.9。如果我们的环境是确定的,相同的动作总是导致相同的奖励,那么我们可以将贴现因子定义为 γ=1。
一个代理做出的好的策略应该是去选择一个能够最大化(折扣后)未来奖励的动作。
2.3. Q-Learning算法描述:

算法中的 α 是指学习率,其控制前一个 Q 值和新提出的 Q 值之间被考虑到的差异程度。尤其是,当 α=1 时,两个 Qs,a 互相抵消,结果刚好和贝尔曼方程一样。
我们用来更新 Qs,a 的只是一个近似,而且在早期阶段的学习中它完全可能是错误的。但是随着每一次迭代,该近似会越来越准确;而且我们还发现如果我们执行这种更新足够长时间,那么 Q 函数就将收敛并能代表真实的 Q 值。
3. 卷积神经网络(CNN)
在图像处理中,往往把图像表示为像素的向量,比如一个1000×1000的图像,可以表示为一个1000000的向量。在上一节中提到的神经网络中,如果隐含层数目与输入层一样,即也是1000000时,那么输入层到隐含层的参数数据为1000000×1000000=10^12,这样就太多了,基本没法训练。所以图像处理要想练成神经网络大法,必先减少参数加快速度。
3.1. 局部感知
卷积神经网络有两种神器可以降低参数数目,第一种神器叫做局部感知野。一般认为人对外界的认知是从局部到全局的,而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。
因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。网络部分连通的思想,也是受启发于生物学里面的视觉系统结构。视觉皮层的神经元就是局部接受信息的(即这些神经元只响应某些特定区域的刺激)。如下图所示:左图为全连接,右图为局部连接。
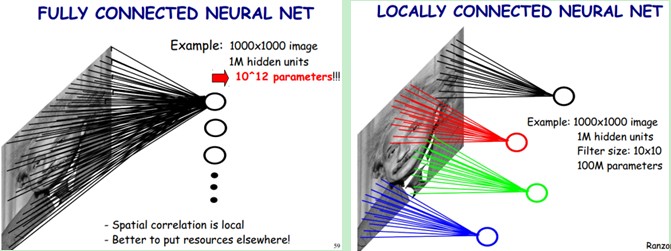
在上右图中,假如每个神经元只和10×10个像素值相连,那么权值数据为1000000×100个参数,减少为原来的万分之一。而那10×10个像素值对应的10×10个参数,其实就相当于卷积操作。
3.2. 参数共享
但其实这样的话参数仍然过多,那么就启动第二级神器,即权值共享。在上面的局部连接中,每个神经元都对应100个参数,一共1000000个神经元,如果这1000000个神经元的100个参数都是相等的,那么参数数目就变为100了。
怎么理解权值共享呢?我们可以这100个参数(也就是卷积操作)看成是提取特征的方式,该方式与位置无关。这其中隐含的原理则是:图像的一部分的统计特性与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征。
更直观一些,当从一个大尺寸图像中随机选取一小块,比如说 8x8 作为样本,并且从这个小块样本中学习到了一些特征,这时我们可以把从这个 8x8 样本中学习到的特征作为探测器,应用到这个图像的任意地方中去。特别是,我们可以用从 8x8 样本中所学习到的特征跟原本的大尺寸图像作卷积,从而对这个大尺寸图像上的任一位置获得一个不同特征的激活值。
如下图所示,展示了一个3×3的卷积核在5×5的图像上做卷积的过程。每个卷积都是一种特征提取方式,就像一个筛子,将图像中符合条件(激活值越大越符合条件)的部分筛选出来。
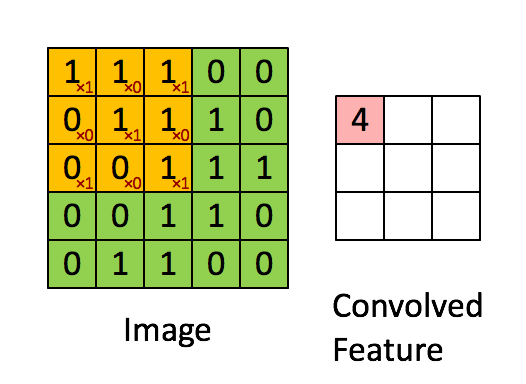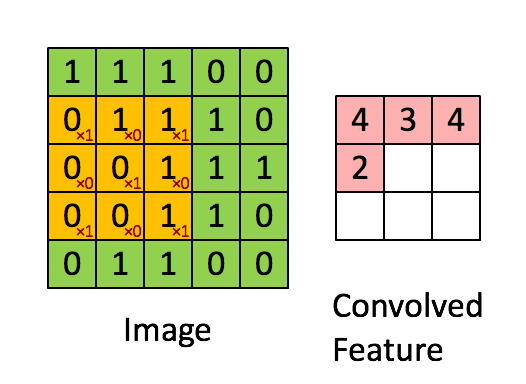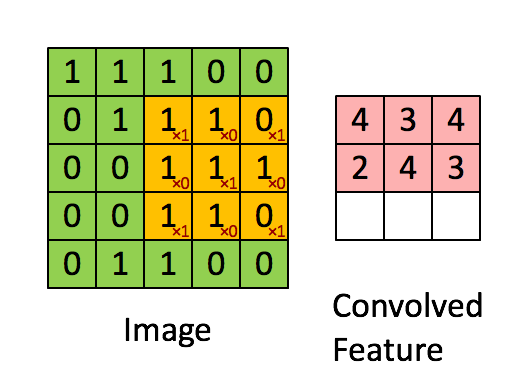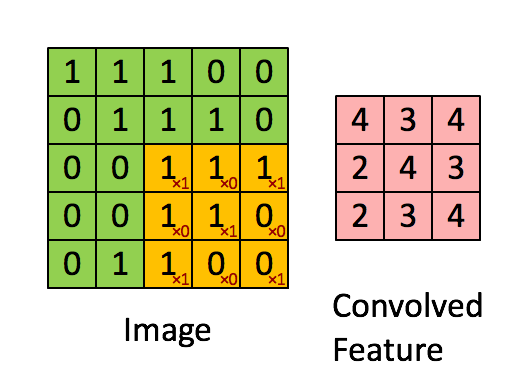
3.3. 多卷积核
上面所述只有100个参数时,表明只有1个10×10的卷积核,显然,特征提取是不充分的,我们可以添加多个卷积核,比如32个卷积核,可以学习32种特征。在有多个卷积核时,如下图所示:
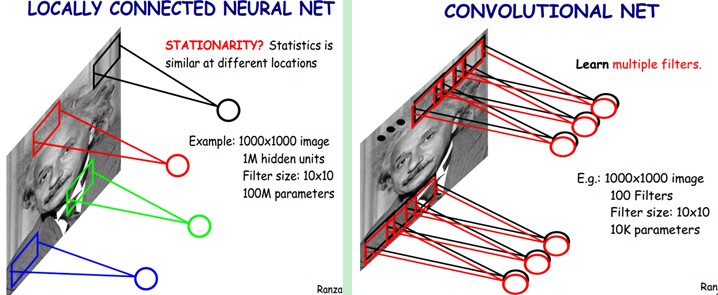
上图右,不同颜色表明不同的卷积核。每个卷积核都会将图像生成为另一幅图像。比如两个卷积核就可以将生成两幅图像,这两幅图像可以看做是一张图像的不同的通道。如下图所示,下图有个小错误,即将w1改为w0,w2改为w1即可。下文中仍以w1和w2称呼它们。
下图展示了在四个通道上的卷积操作,有两个卷积核,生成两个通道。其中需要注意的是,四个通道上每个通道对应一个卷积核,先将w2忽略,只看w1,那么在w1的某位置(i,j)处的值,是由四个通道上(i,j)处的卷积结果相加然后再取激活函数值得到的。

所以,在上图由4个通道卷积得到2个通道的过程中,参数的数目为4×2×2×2个,其中4表示4个通道,第一个2表示生成2个通道,最后的2×2表示卷积核大小。
3.4. Down-pooling
在通过卷积获得了特征 (features) 之后,下一步我们希望利用这些特征去做分类。理论上讲,人们可以用所有提取得到的特征去训练分类器,例如 softmax 分类器,但这样做面临计算量的挑战。
例如:对于一个 96X96 像素的图像,假设我们已经学习得到了400个定义在8X8输入上的特征,每一个特征和图像卷积都会得到一个 (96 − 8 + 1) × (96 − 8 + 1) = 7921 维的卷积特征,由于有 400 个特征,所以每个样例 (example) 都会得到一个 7921 × 400 = 3,168,400 维的卷积特征向量。学习一个拥有超过 3 百万特征输入的分类器十分不便,并且容易出现过拟合 (over-fitting)。
为了解决这个问题,首先回忆一下,我们之所以决定使用卷积后的特征是因为图像具有一种“静态性”的属性,这也就意味着在一个图像区域有用的特征极有可能在另一个区域同样适用。
因此,为了描述大的图像,一个很自然的想法就是对不同位置的特征进行聚合统计,例如,人们可以计算图像一个区域上的某个特定特征的平均值 (或最大值)。这些概要统计特征不仅具有低得多的维度 (相比使用所有提取得到的特征),同时还会改善结果(不容易过拟合)。这种聚合的操作就叫做池化 (pooling),有时也称为平均池化或者最大池化 (取决于计算池化的方法)。
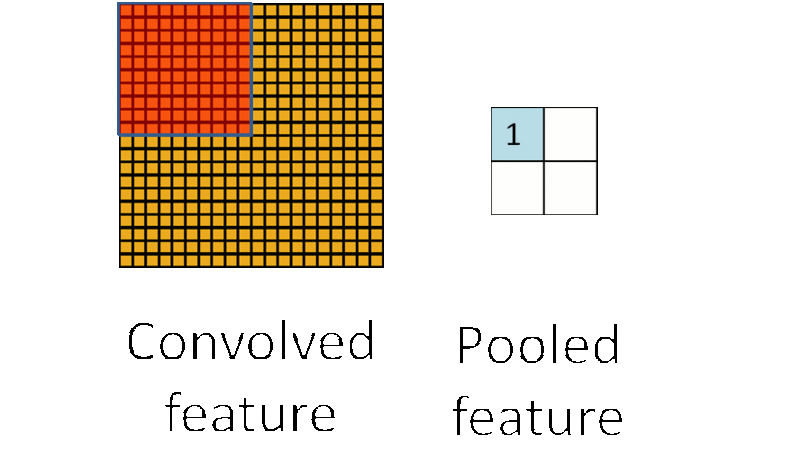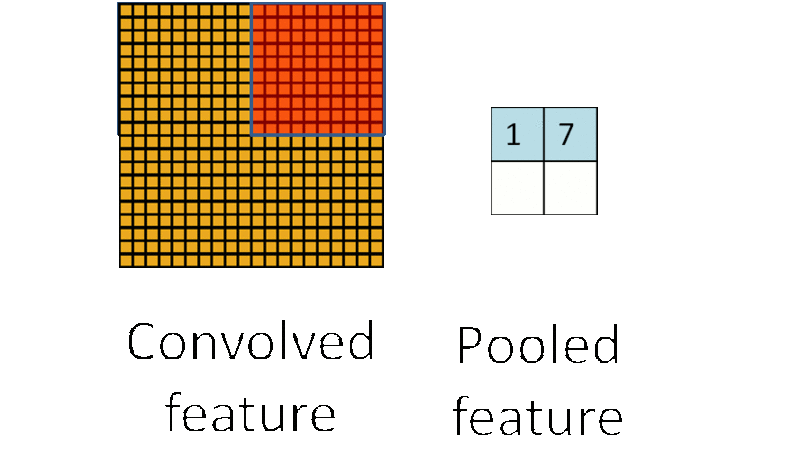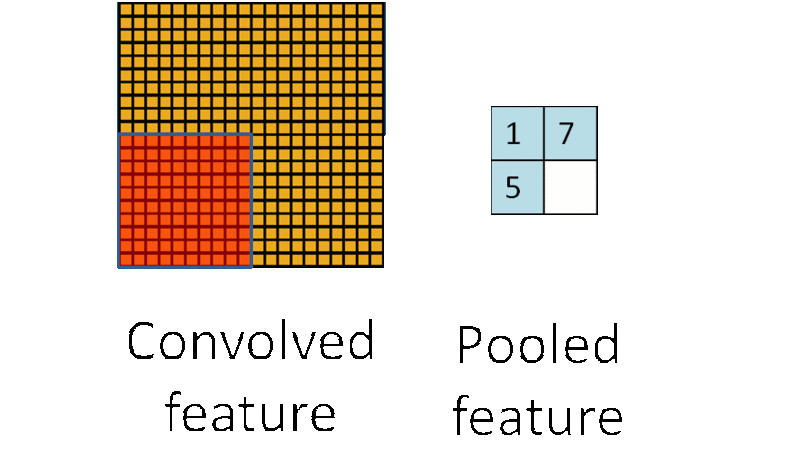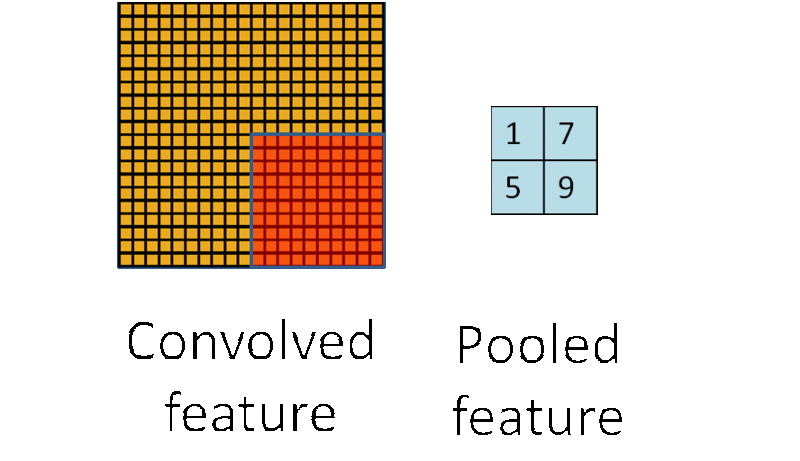
3.5. 多层卷积
在实际应用中,往往使用多层卷积,然后再使用全连接层进行训练,多层卷积的目的是一层卷积学到的特征往往是局部的,层数越高,学到的特征就越全局化。
4. DQN算法描述
单纯的Q-Learning算法使用表来保存状态,一个1000×1000图像的像素状态数基本接近与无穷,故有了CNN+Q-Learning 即DQN算法,算法描述如下:

5. 使用DQN训练“接砖块”游戏
深度学习的开源类库比较多,比较著名的有tensorlow、caffe等。此处我们使用Tensorflow来训练游戏“接砖块”。
游戏截图如下:
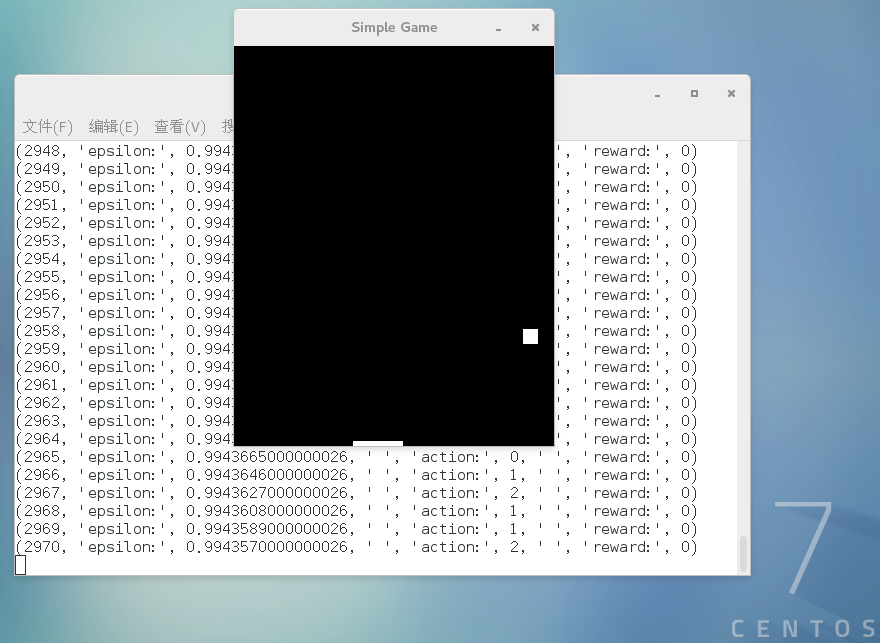
通过点击鼠标左键、右键控制滑块的左右移动来接住小球,如果球碰到底面,则游戏结束
主要python代码如下(游戏本身的代码省略,此处主要关注算法代码):
#Game的定义类,此处Game是什么不重要,只要提供执行Action的方法,获取当前游戏区域像素的方法即可
class Game(object):
def __init__(self): #Game初始化
# action是MOVE_STAY、MOVE_LEFT、MOVE_RIGHT
# ai控制棒子左右移动;返回游戏界面像素数和对应的奖励。(像素->奖励->强化棒子往奖励高的方向移动)
def step(self, action):
# learning_rate
LEARNING_RATE = 0.99
# 跟新梯度
INITIAL_EPSILON = 1.0
FINAL_EPSILON = 0.05
# 测试观测次数
EXPLORE = 500000
OBSERVE = 500
# 记忆经验大小
REPLAY_MEMORY = 500000
# 每次训练取出的记录数
BATCH = 100
# 输出层神经元数。代表3种操作-MOVE_STAY:[1, 0, 0] MOVE_LEFT:[0, 1, 0] MOVE_RIGHT:[0, 0, 1]
output = 3 # MOVE_STAY:[1, 0, 0] MOVE_LEFT:[0, 1, 0] MOVE_RIGHT:[0, 0, 1]
input_image = tf.placeholder("float", [None, 80, 100, 4]) # 游戏像素
action = tf.placeholder("float", [None, output]) # 操作
#定义CNN-卷积神经网络
def convolutional_neural_network(input_image):
weights = {'w_conv1':tf.Variable(tf.zeros([8, 8, 4, 32])),
'w_conv2':tf.Variable(tf.zeros([4, 4, 32, 64])),
'w_conv3':tf.Variable(tf.zeros([3, 3, 64, 64])),
'w_fc4':tf.Variable(tf.zeros([3456, 784])),
'w_out':tf.Variable(tf.zeros([784, output]))}
biases = {'b_conv1':tf.Variable(tf.zeros([32])),
'b_conv2':tf.Variable(tf.zeros([64])),
'b_conv3':tf.Variable(tf.zeros([64])),
'b_fc4':tf.Variable(tf.zeros([784])),
'b_out':tf.Variable(tf.zeros([output]))}
conv1 = tf.nn.relu(tf.nn.conv2d(input_image, weights['w_conv1'], strides = [1, 4, 4, 1], padding = "VALID") + biases['b_conv1'])
conv2 = tf.nn.relu(tf.nn.conv2d(conv1, weights['w_conv2'], strides = [1, 2, 2, 1], padding = "VALID") + biases['b_conv2'])
conv3 = tf.nn.relu(tf.nn.conv2d(conv2, weights['w_conv3'], strides = [1, 1, 1, 1], padding = "VALID") + biases['b_conv3'])
conv3_flat = tf.reshape(conv3, [-1, 3456])
fc4 = tf.nn.relu(tf.matmul(conv3_flat, weights['w_fc4']) + biases['b_fc4'])
output_layer = tf.matmul(fc4, weights['w_out']) + biases['b_out']
return output_layer
#训练神经网络
def train_neural_network(input_image):
predict_action = convolutional_neural_network(input_image)
argmax = tf.placeholder("float", [None, output])
gt = tf.placeholder("float", [None])
action = tf.reduce_sum(tf.mul(predict_action, argmax), reduction_indices = 1)
cost = tf.reduce_mean(tf.square(action - gt))
optimizer = tf.train.AdamOptimizer(1e-6).minimize(cost)
game = Game()
D = deque()
_, image = game.step(MOVE_STAY)
image = cv2.cvtColor(cv2.resize(image, (100, 80)), cv2.COLOR_BGR2GRAY)
ret, image = cv2.threshold(image, 1, 255, cv2.THRESH_BINARY)
input_image_data = np.stack((image, image, image, image), axis = 2)
#print ("IMG2:%s" %input_image_data)
with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
saver = tf.train.Saver()
n = 0
epsilon = INITIAL_EPSILON
while True:
#print("InputImageData:", input_image_data)
action_t = predict_action.eval(feed_dict = {input_image : [input_image_data]})[0]
argmax_t = np.zeros([output], dtype=np.int)
if(random.random() <= INITIAL_EPSILON):
maxIndex = random.randrange(output)
else:
maxIndex = np.argmax(action_t)
argmax_t[maxIndex] = 1
if epsilon > FINAL_EPSILON:
epsilon -= (INITIAL_EPSILON - FINAL_EPSILON) / EXPLORE
reward, image = game.step(list(argmax_t))
image = cv2.cvtColor(cv2.resize(image, (100, 80)), cv2.COLOR_BGR2GRAY)
ret, image = cv2.threshold(image, 1, 255, cv2.THRESH_BINARY)
image = np.reshape(image, (80, 100, 1))
input_image_data1 = np.append(image, input_image_data[:, :, 0:3], axis = 2)
D.append((input_image_data, argmax_t, reward, input_image_data1))
if len(D) > REPLAY_MEMORY:
D.popleft()
if n > OBSERVE:
minibatch = random.sample(D, BATCH)
input_image_data_batch = [d[0] for d in minibatch]
argmax_batch = [d[1] for d in minibatch]
reward_batch = [d[2] for d in minibatch]
input_image_data1_batch = [d[3] for d in minibatch]
gt_batch = []
out_batch = predict_action.eval(feed_dict = {input_image : input_image_data1_batch})
for i in range(0, len(minibatch)):
gt_batch.append(reward_batch[i] + LEARNING_RATE * np.max(out_batch[i]))
print("gt_batch:", gt_batch, "argmax:", argmax_batch)
optimizer.run(feed_dict = {gt : gt_batch, argmax : argmax_batch, input_image : input_image_data_batch})
input_image_data = input_image_data1
n = n+1
print(n, "epsilon:", epsilon, " " ,"action:", maxIndex, " " ,"reward:", reward)
train_neural_network(input_image)6. 总结
说到这里,相信你已经能对强化学习有了一个大致的了解。接下来的事情,应该是如何把这项技术应用到我们的工作中,让它发挥出应有的价值。
问答
什么时候使用某种强化学习算法?
相关阅读
使用 Q-Learning 实现 FlappyBird AI
强化学习总结
一文学习基于蒙特卡罗的强化学习方法
【每日课程推荐】机器学习实战!快速入门在线广告业务及CTR相应知识
此文已由作者授权腾讯云+社区发布,更多原文请点击
搜索关注公众号「云加社区」,第一时间获取技术干货,关注后回复1024 送你一份技术课程大礼包!
海量技术实践经验,尽在云加社区!
- 还没有人评论,欢迎说说您的想法!



 客服
客服


