
本文内容整理自博学谷狂野架构师

CAP 定理又被称作布鲁尔定理,是加州大学的计算机科学家布鲁尔在 2000 年提出的一个猜想。2002 年,麻省理工学院的赛斯·吉尔伯特和南希·林奇发表了布鲁尔猜想的证明,使之成为分布式计算领域公认的一个定理。
布鲁尔在提出CAP猜想时并没有具体定义 Consistency、Availability、Partition Tolerance 这3个词的含义,不同资料的具体定义也有差别,为了更好地解释,下面选择Robert Greiner的文章《CAP Theorem》作为参考基础。
CAP理论的定义
在一个分布式系统(指互相连接并共享数据的节点的集合)中,当涉及读写操作时,只能保证一致性(Consistence)、可用性(Availability)、分区容错性(PartitionTolerance)三者中的两个,另外一个必须被牺牲。
Consistency、Availability、Partition Tolerance具体解释如下:
C - Consistency 一致性
A read is guaranteed to return the most recent write for a given client.
对某个指定的客户端来说,读操作保证能够返回最新的写操作结果。
这里并不是强调同一时刻拥有相同的数据,对于系统执行事务来说,在事务执行过程中,系统其实处于一个不一致的状态,不同的节点的数据并不完全一致。
一致性强调客户端读操作能够获取最新的写操作结果,是因为事务在执行过程中,客户端是无法读取到未提交的数据的,只有等到事务提交后,客户端才能读取到事务写入的数据,而如果事务失败则会进行回滚,客户端也不会读取到事务中间写入的数据。
A - Availability 可用性
A non-failing node will return a reasonable response within a reasonable amount of time (no error or timeout).
非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。
这里强调的是合理的响应,不能超时,不能出错。注意并没有说“正确”的结果,例如,应该返回 100 但实际上返回了 90,肯定是不正确的结果,但可以是一个合理的结果。
P - Partition Tolerance 分区容忍性
The system will continue to function when network partitions occur.
当出现网络分区后,系统能够继续“履行职责”。
这里网络分区是指:
一个分布式系统里面,节点组成的网络本来应该是连通的。然而可能因为一些故障(节点间网络连接断开、节点宕机),使得有些节点之间不连通了,整个网络就分成了几块区域,数据就散布在了这些不连通的区域中。
一致性、可用性、分区容忍性的选择
虽然 CAP 理论定义是三个要素中只能取两个,但放到分布式环境下来思考,我们会发现必须选择 P(分区容忍)要素,因为网络本身无法做到 100% 可靠,有可能出故障,所以分区是一个必然的现象。
如果我们选择了 CA(一致性 + 可用性) 而放弃了 P(分区容忍性),那么当发生分区现象时,为了保证 C(一致性),系统需要禁止写入,当有写入请求时,系统返回 error(例如,当前系统不允许写入),这又和 A(可用性) 冲突了,因为 A(可用性)要求返回 no error 和 no timeout。
因此,分布式系统理论上不可能选择 CA (一致性 + 可用性)架构,只能选择 CP(一致性 + 分区容忍性) 或者 AP (可用性 + 分区容忍性)架构,在一致性和可用性做折中选择。
CP - Consistency + Partition Tolerance (一致性 + 分区容忍性)
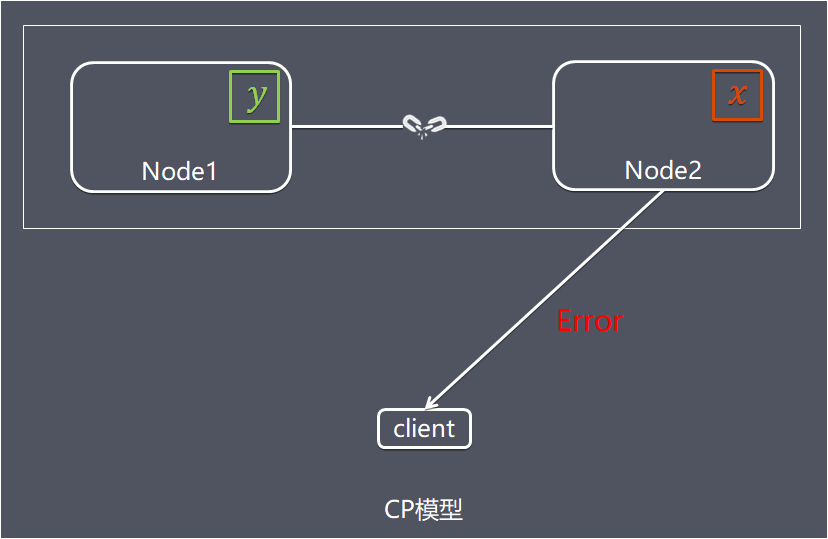
如上图所示,因为Node1节点和Node2节点连接中断导致分区现象,Node1节点的数据已经更新到y,但是Node1 和 Node2 之间的复制通道中断,数据 y 无法同步到 Node2,Node2 节点上的数据还是旧数据x。
这时客户端C 访问 Node2 时,Node2 需要返回 Error,提示客户端 “系统现在发生了错误”,这种处理方式违
背了可用性(Availability)的要求,因此 CAP 三者只能满足 CP。
AP - Availability + Partition Tolerance (可用性 + 分区容忍性)
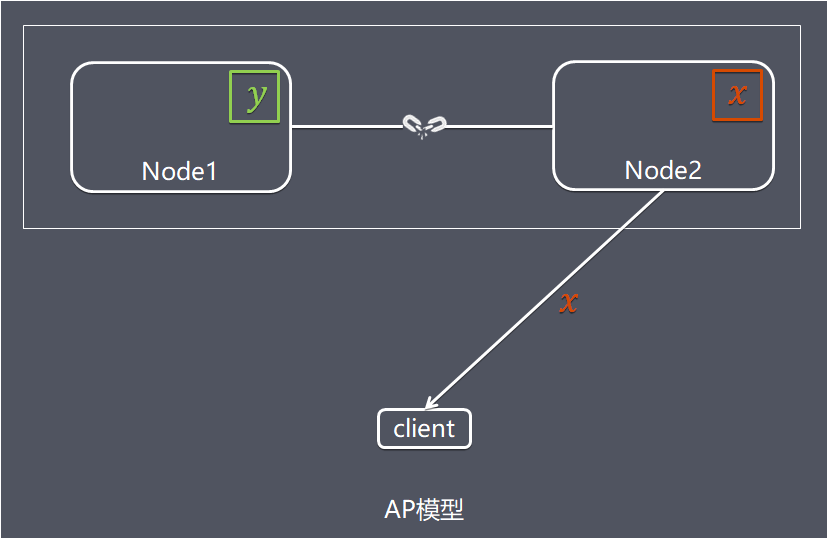
同样是Node2 节点上的数据还是旧数据x,这时客户端C 访问 Node2 时,Node2 将当前自己拥有的数据 x 返回给客户端 了,而实际上当前最新的数据已经是 y 了,这就不满足一致性(Consistency)的要求了,因此 CAP 三者只能满足 AP。
注意:这里 Node2 节点返回 x,虽然不是一个“正确”的结果,但是一个“合理”的结果,因为 x 是旧的数据,并不是一个错乱的值,只是不是最新的数据。
值得补充的是,CAP理论告诉我们分布式系统只能选择AP或者CP,但实际上并不是说整个系统只能选择AP或者CP,在 CAP 理论落地实践时,我们需要将系统内的数据按照不同的应用场景和要求进行分类,每类数据选择不同的策略(CP 还是 AP),而不是直接限定整个系统所有数据都是同一策略。
另外,只能选择CP或者AP是指系统发生分区现象时无法同时保证C(一致性)和A(可用性),但不是意味着什么都不做,当分区故障解决后,系统还是要保持保证CA。
CAP理论的延伸——BASE理论
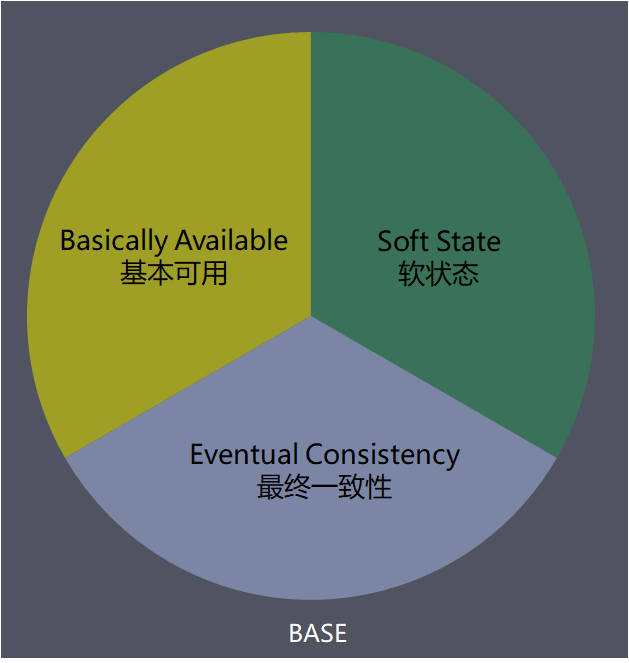
BASE 是指基本可用(Basically Available)、软状态( Soft State)、最终一致性( Eventual Consistency),核心思想是即使无法做到强一致性(CAP 的一致性就是强一致性),但应用可以采用适合的方式达到最终一致性。
BA - Basically Available 基本可用
分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
这里的关键词是“部分”和“核心”,实际实践上,哪些是核心需要根据具体业务来权衡。例如登录功能相对注册功能更加核心,注册不了最多影响流失一部分用户,如果用户已经注册但无法登录,那就意味用户无法使用系统,造成的影响范围更大。
S - Soft State 软状态
允许系统存在中间状态,而该中间状态不会影响系统整体可用性。这里的中间状态就是 CAP 理论中的数据不一致。
E - Eventual Consistency 最终一致性
系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。
这里的关键词是“一定时间” 和 “最终”,“一定时间”和数据的特性是强关联的,不同业务不同数据能够容忍的不一致时间是不同的。例如支付类业务是要求秒级别内达到一致,因为用户时时关注;用户发的最新微博,可以容忍30分钟内达到一致的状态,因为用户短时间看不到明星发的微博是无感知的。而“最终”的含义就是不管多长时间,最终还是要达到一致性的状态。
BASE 理论本质上是对 CAP 的延伸和补充,更具体地说,是对 CAP 中 AP 方案的一个补充:
-
CP 理论是忽略延时的,而实际应用中延时是无法避免的。
这一点就意味着完美的 CP 场景是不存在的,即使是几毫秒的数据复制延迟,在这几毫秒时间间隔内,系统是不符合 CP 要求的。因此 CAP 中的 CP 方案,实际上也是实现了最终一致性,只是“一定时间”是指几毫秒而已。 -
AP 方案中牺牲一致性只是指发生分区故障期间,而不是永远放弃一致性。
这一点其实就是 BASE 理论延伸的地方,分区期间牺牲一致性,但分区故障恢复后,系统应该达到最终一致性。
数据一致性模型
前面介绍的BASE模型提过“强一致性”和“最终一致性”,下面对这些一致性模型展开介绍。
分布式系统通过复制数据来提高系统的可靠性和容错性,并且将数据的不同的副本存放在不同的机器上,由于维护数据副本的一致性代价很高,因此许多系统采用弱一致性来提高性能,下面介绍常见的一致性模型:
强一致性
要求无论更新操作是在哪个数据副本上执行,之后所有的读操作都要能获得最新的数据。对于单副本数据来说,读写操作是在同一数据上执行的,容易保证强一致性。对多副本数据来说,则需要使用分布式事务协议。
弱一致性
在这种一致性下,用户读到某一操作对系统特定数据的更新需要一段时间,我们将这段时间称为"不一致性窗口"。
最终一致性
是弱一致性的一种特例,在这种一致性下系统保证用户最终能够读取到某操作对系统特定数据的更新(读取操作之前没有该数据的其他更新操作)。"不一致性窗口"的大小依赖于交互延迟、系统的负载,以及数据的副本数等。
总结
系统选择哪种一致性模型取决于应用对一致性的需求,所选取的一致性模型还会影响到系统如何处理用户的请求以及对副本维护技术的选择等。后面将基于上面介绍的一致性模型分别介绍分布式事务的解决方案。
柔性事务
柔性事务的概念
在电商等互联网场景下,传统的事务在数据库性能和处理能力上都暴露出了瓶颈。在分布式领域基于CAP理论以及BASE理论,有人就提出了柔性事务的概念。
基于BASE理论的设计思想,柔性事务下,在不影响系统整体可用性的情况下(Basically Available 基本可用),允许系统存在数据不一致的中间状态(Soft State 软状态),在经过数据同步的延时之后,最终数据能够达到一致。并不是完全放弃了ACID,而是通过放宽一致性要求,借助本地事务来实现最终分布式事务一致性的同时也保证系统的吞吐。
实现柔性事务的一些特性
下面介绍的是实现柔性事务的一些常见特性,这些特性在具体的方案中不一定都要满足,因为不同的方案要求不一样。
可见性(对外可查询)
在分布式事务执行过程中,如果某一个步骤执行出错,就需要明确的知道其他几个操作的处理情况,这就需要其他的服务都能够提供查询接口,保证可以通过查询来判断操作的处理情况。
为了保证操作的可查询,需要对于每一个服务的每一次调用都有一个全局唯一的标识,可以是业务单据号(如订单号)、也可以是系统分配的操作流水号(如支付记录流水号)。除此之外,操作的时间信息也要有完整的记录。
操作幂等性
幂等性,其实是一个数学概念。幂等函数,或幂等方法,是指可以使用相同参数重复执行,并能获得相同结果的函数。幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。也就是说,同一个方法,使用同样的参数,调用多次产生的业务结果与调用一次产生的业务结果相同。
之所以需要操作幂等性,是因为为了保证数据的最终一致性,很多事务协议都会有很多重试的操作,如果一个方法不保证幂等,那么将无法被重试。幂等操作的实现方式有多种,如在系统中缓存所有的请求与处理结果、检测到重复操作后,直接返回上一次的处理结果等。
本文由
传智教育博学谷狂野架构师教研团队发布。如果本文对您有帮助,欢迎
关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力。转载请注明出处!
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


