
代码洁癖狂们!看到一个类中有几十个if-else是不是很抓狂?
设计模式学了用不上吗?面试的时候问你,你只能回答最简单的单例模式,问你有没有用过反射之类的高级特性,回答也是否吗?
这次就让设计模式(模板方法模式+工厂模式)和反射助你消灭if-else!
真的是开发中超超超超超超有用的干货啊!
那个坑货
某日,码农胖滚猪接到上级一个需求,这个需求牛逼了,一站式智能报表查询平台,支持mysql、pgxl、tidb、hive、presto、mongo等众多数据源,想要啥数据都能通通给你查出来展示,对于业务人员数据分析有重大意义!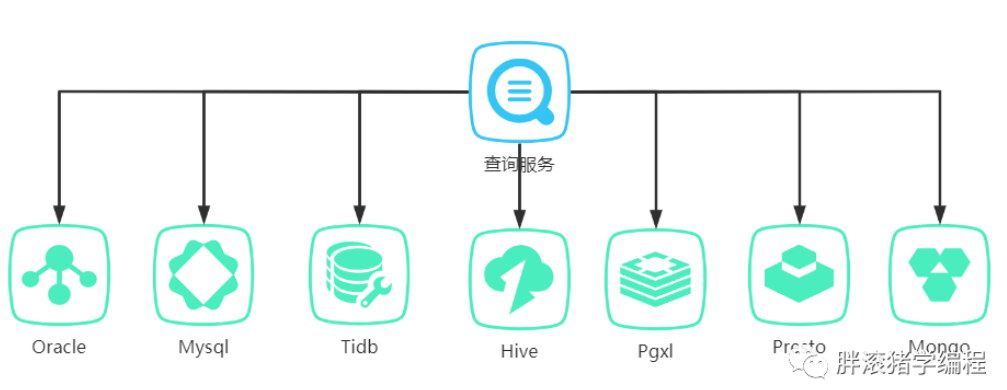
虽然各个数据源的参数校验、查询引擎和查询逻辑都不一样,但是胖滚猪对这些框架都很熟悉,这个难不倒她,她只花了一天时间就都写完了。
领导胖滚熊也对胖滚猪的效率表示了肯定。可是好景不长,第三天,领导闲着没事,准备做一下code review,可把胖滚熊惊呆了,一个类里面有近30个if-else代码,我滴个妈呀,这可让代码洁癖狂崩溃了。
// 检验入参合法性
Boolean check = false;
if(DataSourceEnum.hive.equals(dataSource)){
check = checkHiveParams(params);
} else if(DataSourceEnum.tidb.equals(dataSource)){
check = checkTidbParams(params);
} else if(DataSourceEnum.mysql.equals(dataSource)){
check = checkMysqlParams(params);
} // else if ....... 省略pgxl、presto等
if(check){
if(DataSourceEnum.hive.equals(dataSource)){
list = queryHive(params);
} else if(DataSourceEnum.tidb.equals(dataSource)){
list = queryTidb(params);
} else if(DataSourceEnum.mysql.equals(dataSource)){
list = queryMysql(params);
} // else if ....... 省略pgxl、presto等
}
//记录日志
log.info("用户={} 查询数据源={} 结果size={}",params.getUserName(),params.getDataSource(),list.size());
模板模式来救场
首先我们来分析下,不管是什么数据源,算法结构(流程)都是一样的,1、校验参数合法性 2、查询 3、记录日志。这不就是说模板一样、只不过具体细节不一样,没错吧?
让我们来看看设计模式中模板方法模式的定义吧:
模板方法模式:定义一个操作中的算法的框架,而将一些步骤延迟到子类中. 使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。通俗的讲,就是将子类相同的方法, 都放到其抽象父类中。
我们这需求不就和模板方法模式差不多吗?因此我们可以把模板抽到父类(抽象类)中。至于特定的步骤实现不一样,这些特殊步骤,由子类去重写就好了。
废话不多说了,我们先把父类模板写好吧,完全一样的逻辑是记录日志,这步在模板写死就好。至于检验参数和查询,这两个方法各不相同,因此需要置为抽象方法,由子类去重写。
public abstract class AbstractDataSourceProcesser <T extends QueryInputDomain> {
public List<HashMap> query(T params){
List<HashMap> list = new ArrayList<>();
//检验参数合法性 不同的引擎sql校验逻辑不一样
Boolean b = checkParam(params);
if(b){
//查询
list = queryData(params);
}
//记录日志
log.info("用户={} 查询数据源={} 结果size={}",params.getUserName(),params.getDataSource(),list.size());
return list;
}
//抽象方法 由子类来实现特定逻辑
abstract Boolean checkParam(T params);
abstract List<HashMap> queryData(T params);
}
这段代码非常简单。但是为了照顾新手,还是想解释一个东西:
T这个玩意。叫泛型,因为不同数据源的入参不一样,所以我们使用泛型。但是他们也有公共的参数,比如用户名。因此为了不重复冗余,更好的利用公共资源,在泛型的设计上,我们可以有一个泛型上限,<T extends QueryInputDomain>
public class QueryInputDomain<T> {
public String userName;//查询用户名
public String dataSource;//查询数据源 比如mysqltidb等
public T params;//特定的参数 不同的数据源参数一般不一样
}
public class MysqlQueryInput extends QueryInputDomain{
private String database;//数据库
public String sql;//sql
}
接下来就轮到子类出场了,通过上面的分析,其实也很简单了,不过是继承父类,重写checkParam()和queryData()方法,下面以mysql数据源为例,其他数据源也都一样的套路:
@Component("dataSourceProcessor#mysql")
public class MysqlProcesser extends AbstractDataSourceProcesser<MysqlQueryInput>{
@Override
public Boolean checkParam(MysqlQueryInput params) {
System.out.println("检验mysql参数是否准确");
return true;
}
@Override
public List<HashMap> queryData(MysqlQueryInput params) {
List<HashMap> list = new ArrayList<>();
System.out.println("开始查询mysql数据");
return list;
}
}
这样一来,所有的数据源,都自成一体,拥有一个只属于自己的类,后续要扩展数据源、或者要修改某个数据源的逻辑,都非常方便和清晰了。
说实话,模板方法模式太简单了,抽象类这东西也太基础普遍了,一般应届生都会知道的。但是对于初入职场的新人来说,还真不太能果断应用在实际生产中。因此提醒各位:一定要有一个抽象思维,避免代码冗余重复。
另外,要再啰嗦几句,即使工作有几年的工程师也很容易犯一个错误。就是把思维局限在今天的需求,比如老板一开始只给你一个mysql数据源查询的需求,压根没有if-else,可能你就不会放在心上,直接在一个类中写死,不会考虑到后续的扩展。直到后面越来越多的新需求,你才恍然大悟,要全部重构一番,这样浪费自己的时间了。因此提醒各位:做需求不要局限于今天,要考虑到未来。 从一开始就做到高扩展性,后续需求变更和维护就非常爽了。
原创声明:本文为【胖滚猪学编程】原创博文,转载请注明出处。以漫画形式让编程生动有趣!原创不易,求关注!
工厂模式来救场
但是模板模式还是没有完全解决胖滚猪的if-else,因为需要根据传进来的dataSource参数,判断由哪个service来实现查询逻辑,现在是这么写的:
if(DataSourceEnum.hive.equals(dataSource)){
list = queryHive(params);
} else if(DataSourceEnum.tidb.equals(dataSource)){
list = queryTidb(params);
}
那么这种if-else应该怎么去干掉呢?我想先跟你讲讲工厂模式的那些故事。
工厂模式:工厂方法模式是一种创建对象的模式,它被广泛应用在jdk中以及Spring和Struts框架中。它将创建对象的工作转移到了工厂类。
为了呼应一下工厂两字,我特意举一个代工厂的例子让你理解,这样你应该会有更深刻的印象。
以手机制造业为例。我们知道有苹果手机、小米手机等等,每种品牌的手机制造方法必然不相同,我们可以先定义好一个手机标准接口,这个接口有make()方法,然后不同型号的手机都继承这个接口:
#Phone类:手机标准规范类(AbstractProduct)
public interface Phone {
void make();
}
#MiPhone类:制造小米手机(Product1)
public class MiPhone implements Phone {
public MiPhone() {
this.make();
}
@Override
public void make() {
System.out.println("make xiaomi phone!");
}
}
#IPhone类:制造苹果手机(Product2)
public class IPhone implements Phone {
public IPhone() {
this.make();
}
@Override
public void make() {
System.out.println("make iphone!");
}
}
现在有某手机代工厂:【天霸手机代工厂】。客户只会告诉该工厂手机型号,就要匹配到不同型号的制作方案,那么代工厂是怎么实现的呢?其实也很简单,简单工厂模式(还有抽象工厂模式和工厂方法模式,有兴趣可以了解下)是这么实现的:
#PhoneFactory类:手机代工厂(Factory)
public class PhoneFactory {
public Phone makePhone(String phoneType) {
if(phoneType.equalsIgnoreCase("MiPhone")){
return new MiPhone();
}
else if(phoneType.equalsIgnoreCase("iPhone")) {
return new IPhone();
}
}
}
这样客户告诉你手机型号,你就可以调用代工厂类的方法去获取到对应的手机制造类。你会发现其实也不过是if-else,但是把if-else抽到一个工厂类,由工厂类统一创建对象,对我们的业务代码无入侵,不管是维护还是美观上都会好很多。
首先,我们应该在每个特定的dataSourceProcessor(数据源执行器),比如MysqlProcesser、TidbProcesser中添加spring容器注解@Component。该注解我想应该不用多解释了吧~重点是:我们可以把不同数据源都搞成类似的bean name,形如dataSourceProcessor#数据源名称,如下两段代码:
@Component("dataSourceProcessor#mysql")
public class MysqlProcesser extends AbstractDataSourceProcesser<MysqlQueryInput>{
@Component("dataSourceProcessor#tidb")
public class TidbProcesser extends AbstractDataSourceProcesser<TidbQueryInput>{
这样有什么好处呢?我可以利用Spring帮我们一次性加载出所有继承于AbstractDataSourceProcesser的Bean ,形如Map<String, AbstractDataSourceProcesser>,Key是Bean的名称、而Value则是对应的Bean:
@Service
public class QueryDataServiceImpl implements QueryDataService {
@Resource
public Map<String, AbstractDataSourceProcesser> dataSourceProcesserMap;
public static String beanPrefix = "dataSourceProcessor#";
@Override
public List<HashMap> queryData(QueryInputDomain domain) {
AbstractDataSourceProcesser dataSourceProcesser = dataSourceProcesserMap.get(beanPrefix + domain.getDataSource());
//省略query代码
}
}
可能你还是不太理解,我们直接看一下运行效果:
1、dataSourceProcesserMap内容如下所示,存储了所有数据源Bean,Key是Bean的名称、而Value则是对应的Bean: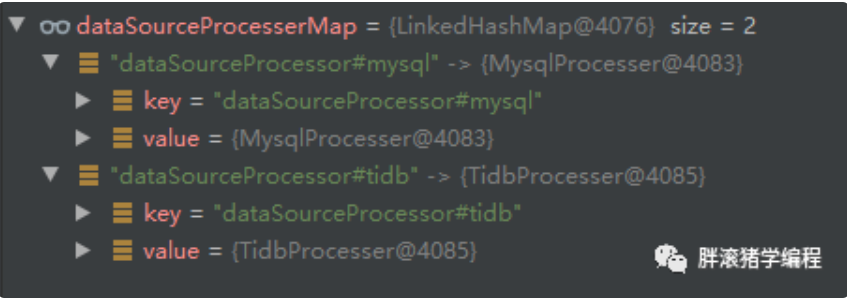
2、我只需要通过key(即前缀+数据源名称=beanName),就能匹配到对应的执行器了。比如当参数dataSource为tidb的时候,key为dataSourceProcessor#tidb,根据key可以直接从dataSourceProcesserMap中获取到TidbProcesser



public static String classPrefix = "com.lyl.java.advance.service.";
AbstractDataSourceProcesser sourceGenerator =
(AbstractDataSourceProcesser) Class.forName
(classPrefix+DataSourceEnum.getClasszByCode(domain.getDataSource()))
.newInstance();
需要注意的是,该种方法是通过className来获取到类的实例,而前端传参肯定是不会传className过来的。因此可以用到枚举类,去定义好不同数据源的类名:
public enum DataSourceEnum {
mysql("mysql", "MysqlProcesser"),
tidb("tidb", "TidbProcesser");
private String code;
private String classz;
原创声明:本文为【胖滚猪学编程】原创博文,转载请注明出处。以漫画形式让编程生动有趣!原创不易,求关注!
总结
有些童鞋总觉得设计模式用不上,因为平时写代码除了CRUD还是CRUD,面试的时候问你设计模式,你只能回答最简单的单例模式,问你有没有用过反射之类的高级特性,回答也是否。
其实不然,JAVA这23种设计模式,每一个都是经典。今天我们就用模板方法模式+工厂模式(或者反射)解决了让人崩溃的if-else。后续对于设计模式的学习,也应该多去实践,从真实的项目中找到用武之地,你才算真正把知识占为己有了。
本篇文章的内容和技术点虽然很简单,但旨在告诉大家应该要有一个很好的代码抽象思维。杜绝在代码中出现一大摞if-else或者其他烂代码。
即使你有很好的代码抽象思维,做需求开发的时候,也不要局限于当下,只考虑现在,要多想想未来的扩展性。
就像你谈恋爱一样,只考虑当下的是渣男,考虑到未来的,才算是一个负责任的人
"愿世界没有渣男"
原创声明:本文为【胖滚猪学编程】原创博文,转载请注明出处。以漫画形式让编程生动有趣!原创不易,求关注!
本文来源于公众号:【胖滚猪学编程】。一枚集颜值与才华于一身,不算聪明却足够努力的女程序媛。用漫画形式让编程so easy and interesting!求关注!
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


