
如题:
深度强化学习算法(深度强化学习框架)为考虑可以快速适用多种深度学习框架建议采用弱耦合的软件设计方法
今日在看强化学习的框架,发现现在的深度强化学习框架不论是依赖Tensorflow的还是PyTorch的,在设计时都没有考虑过耦合这个问题,虽然强化学习算法源于学术界,而且现在也还是主要停留于学术界,但是毕竟现在在慢慢的向工业界靠拢,而不论是考虑到工业界的快速使用还是学术领域方面很好的follow工作,一个可以快速适用于多种深度学习计算框架的深度强化学习框架都是很为需要的。
强化学习与其他继续学习算法的不同之处:
像其他的强化学习算法,如NLP,CV等,算法本身就与深度学习计算框架是弱耦合的关联,因此这些算法如果要更换具体的深度学习计算框架的话只需要替换为另一种计算框架下的网络定义方式,并更换损失函数和优化器以及数据导入方式即可,这这些模块本身也是弱耦合的,因此这些非深度强化学习算法可以较为容易的更换具体的深度学习计算框架。而强化学习算法与其他机器学习算法不同,深度学习模块在深度强化学习算法只是一个组成部分,是一个子模块,而往往深度强化学习算法的主体部分不是深度学习的计算网络,再加上强化学习算法本身又需要与环境进行交互,因此最终导致深度强化学习算法的代码中神经网络体现在整个算法的各个部分,形成了一种强耦合的状态。由于现如今的大多数深度强化学习算法代码都是神经网络与强化学习算法主体部分形成了强耦合形式,因此我们难以快速的使现有代码快速适用不同的深度学习计算框架,比如从pytorch框架迁移到TensorFlow框架,亦如从TensorFlow框架迁移到pytorch框架,这样不论是学术研究还是工业领域的直接使用都难以快速实现,那么我们怎么来解决这个问题呢,如何使我们的代码可以快速适应不同的深度学习计算框架,较少人力花费的进行迭代变更,快速的使他人fellow呢?
这里我给出了一个个人的建议,那就是对于深度强化学习算法采用弱耦合的软件设计方法。
现有的强耦合式的深度强化学习算法设计:(示意图)
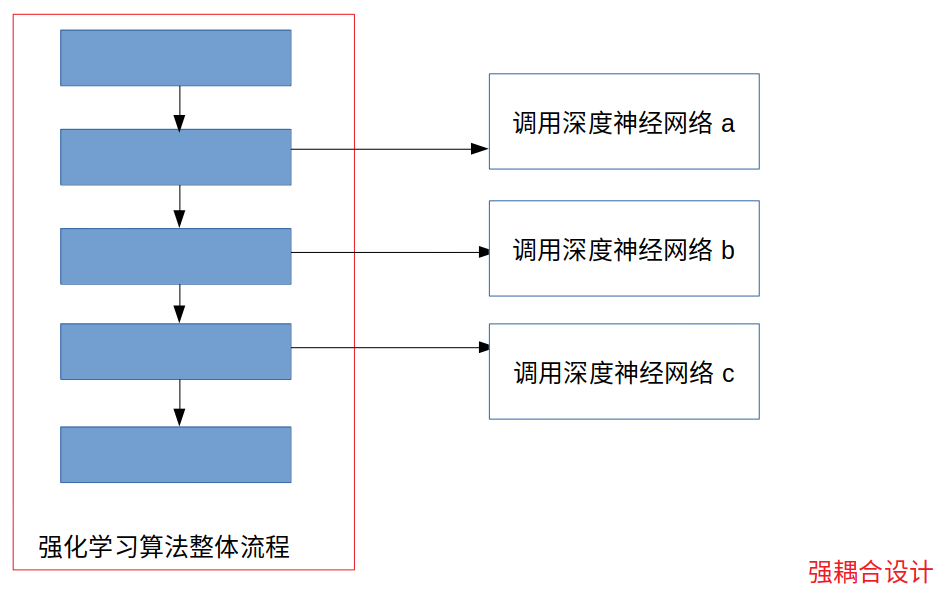
建议使用的弱耦合设计:(示意图)

=================================================================
这种弱耦合的设计可以很好的隔离掉神经网络的实现细节与调用细节,而我们以后不管是要替换掉具体的后台深度学习计算框架还是要进行代码版本的迭代更新都可以进行组件方式的操作。如果我们要把深度强化学习的网络框架由Tensorflow和Pytorch之间进行转换,我们只需要替换掉神经网络代码库这一部分,同时对中间层代码的api调用进行修改,而对强化学习的逻辑代码部分不进行任何修改。而如果我们要对强化学习算法的主体部分的逻辑进行修改,我们的中间层代码和后端的神经网络代码是不需要进行大幅度修改的,不论是修改强化学习算法主体逻辑还是进行版本更迭都会节省掉很大的人力物力,提高我们的效率。
本文的想法概括的来说就是将以往的耦合成一体的深度强化学习算法分解成三部分,即:
1. 前端(强化学习主体逻辑部分)
2. 中间层 (对强化学习主体算法隐藏掉具体的神经网络代码细节,只提供统一的调用接口)
3. 后端(深度学习计算框架代码部分,根据具体的运行平台,快速的、独立的替换成不同版本的Tensorflow、Pytorch、MindSpore代码,同时也能快速使用不同的计算平台:CPU、GPU、移动端Lite、Ascend平台)
ps:
当然本文最初的构想还是为了解决学术研究时要根据不同深度强化学习算法及框架去看不同深度学习框架代码而来的,毕竟一边搞着强化学习的各种论文及算法逻辑代码还能很好的cover掉不同深度学习计算框架的代码是一件蛮难的事情。
文章来源: 博客园
原文链接: https://www.cnblogs.com/devilmaycry812839668/p/15025136.html
- 还没有人评论,欢迎说说您的想法!



 客服
客服


