
所谓机器学习,在形式上可近似等同于,在数据对象中通过统计或推理的方法,寻找一个有关特定输入和预期输出的功能函数 f(如图 1 所示)。通常,我们把输入变量(特征)空间记作大写的 X,而把输出变量空间记作大写的 Y。那么所谓的机器学习,在形式上就近似等同于 Y≈f(X)。

图 1:机器学习近似于找一个好用的函数
在这样的函数中,针对语音识别功能,如果输入一个音频信号,那么这个函数 f 就能输出诸如 "你好" "How are you?" 这类识别信息。针对图片识别功能,如果输入的是一张图片,在这个函数的加工下,就能输出(或识别出)一个或猫或狗的判定。针对下棋博弈功能,如果输入的是一个围棋的棋谱局势,就能输出这局棋的下一步“最佳”走法。
而对于具备智能交互功能的系统(比如微软的小冰),当我们给这个函数输入如 "How are you?" 一样的语句,它就能输出如 "I am fine, thank you." 这样的智能回应。每个具体的输入都是一个实例(instance),它通常由特征向量(feature vector)构成。在这里,所有特征向量存在的空间称为特征空间(feature space),特征空间的每一个维度对应实例的一个特征。
但问题来了,这样“好用的”函数并不那么好找。在输入猫的图片后,这个函数并不一定就能输出“这是一只猫”,它可能会错误地输出这是一只狗或这是一条蛇。这样一来,我们就需要构建一个评估体系来辨别函数的好赖。当然,这中间自然需要通过训练数据(training data)来“培养”函数的好品质。
前面我们提到,学习的核心就是改善性能。图 2 展示了机器学习的三步走,通过训练数据,我们把 f1 改善为 f2 的样子,即使 f2 中仍然存在分类错误,但相比于 f1 的全部出错,它的性能(分类的准确度)还是提高了,这就是学习。
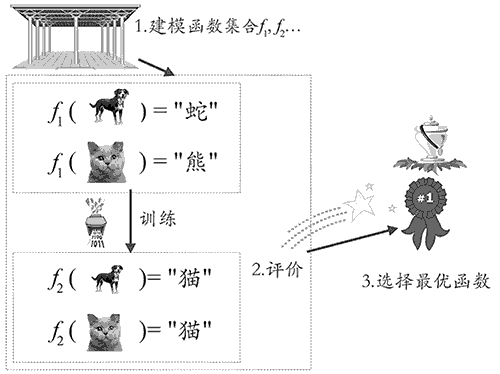
图 2:机器学习的三步走
具体来说,机器学习要想做得好,需要走好三大步:
- 如何找到一系列的函数来实现预期功能,这是一个建模问题;
- 如何找到一系列评价标准来评价函数的好坏,这是一个评价问题;
- 如何快速找到性能最优的函数,这是一个优化问题。
习惯上,我们把具体的输入变量、输出变量用小写的 x 和 y 表示。变量既可以是标量(scalar),也可以是向量(vector)。除做特殊说明外,本教程所言向量均为列向量。标准的写法如图 3(a) 所示,但这种写法比较占用空间,因此我们通常采用转置的写法,如图 3(b) 所示,图中的上标“T”就是转置(Transpose)符号。
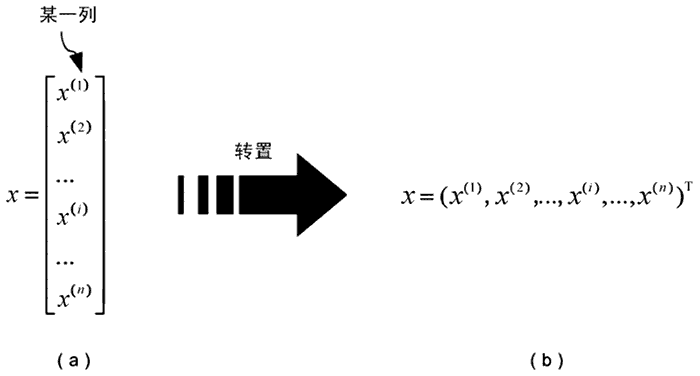
图 3:特征向量矩阵
这里的 x(i) 表示的是输入变量 x 的第 i 个特征。需要特别注意的是,当输入变量有多个时,我们用 xj 表示。如此一来,xj(i) 就表示第 j 个变量的第 i 个特征,特征向量矩阵如图 4 所示。
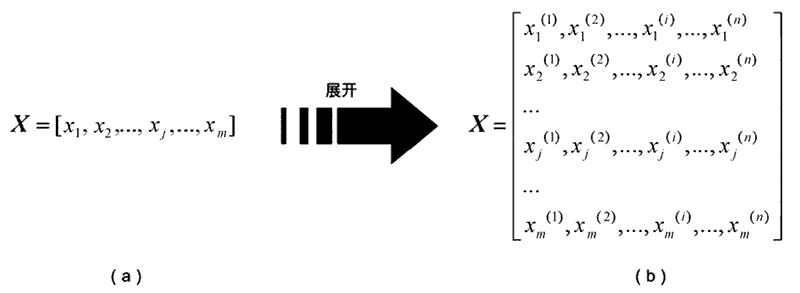
图 4:特征向量矩阵
对于监督学习来说,所构建的模型通常在训练数据(Training Data)集中学习,调整模型参数,然后在测试数据(Test Data)集中进行预测验证。
对于训练数据,输入信号(或变量)与输出信号(或变量)通常是成对出现的。有时,输出信号也被称为“教师信号”,因为它具备指导性,可通过损失函数来“调教”模型中的参数。因此,训练数据集通常用如下列公式所示的方式进行描来“调教”模型中的参数。因此,训练数据集通常用如以下公式所示的方式进行描述:
T ={(x1, y1),(x2, y2),...,(xj, yj),...(xm, ym)}
输入变量和输出变量有不同的类型,它们既可以是连续的,也可以是离散的。通常,人们会根据输入变量和输出变量的不同类型,给预测任务赋予不同的名称。比如,如果输入变量和输出变量均为连续变量,那么这样的预测任务就称为回归(Regression)。
如果输出变量为有限的离散值,那么这样的预测任务就称为分类(Classification)。如果输入变量和输出变量均为变量序列,那么这样的预测任务就称为标注(Tagging),我们可以认为标注是分类的一个推广。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


