
这个案例是最近刚发生不久的,只是这个雷的历史实在是久远。
公司在3月底因为一次腾讯云专线故障,整个支付系统在高峰期停止服务将近10分钟。而且当时为了快速解决问题止损,重启了支付服务,事后也就没有了现场。我们支付组在技术架构上原先对专线故障的场景做了降级预案,但故障时预案并没有生效,所以这次我们需要排查清楚降级没有生效的原因(没有现场的事后排查,挑战非常大)。
微信支付流程
首先回顾一下微信支付的流程(也可以参考https://pay.weixin.qq.com/wiki/doc/api/jsapi.php?chapter=7_4):
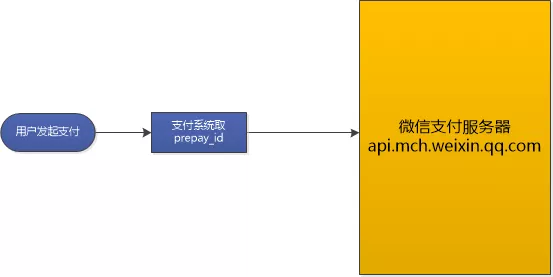
这个过程是同步的,如果我们的支付系统因为网络问题,没有取到prepay_id,那么用户就无法支付;
我们的预案
我们的预案非常简单,就是在请求api.mch.weixin.qq.com时,在HTTPClient中设置了一个超时时间,当支付请求超时时,我们就请求微信支付的另外一个备用域名api2.mch.weixin.qq.com,我们的超时时间设置的是3秒;
故障现象
每次网络抖动的时候,我们从监控中都能发现,我们的超时时间并没有完全起作用。从故障后的监控看平均执行时间达到了10秒,超时时间(3秒)完全不管用:从日志中进一步分析到,很多请求都是在10秒以上,甚至10分钟后才报超时异常。10分钟后再降级到备份域名显然已经没有什么意义了。这让我们开发很不解,为什么HttpClient的超时设置没有生效,难道是HttpClient的bug?

以前我们也怀疑过自己封装的HTTPClient组件有问题,但是我们写了一个并发程序测试过,当时并没有测试出有串行问题或者不支持并发的问题;
真相-系统层面瓶颈点HttpClient
最近通过我们测试(我们组其中一个开发在测试环境对故障进行了复现)和调研后,我们发现支付系统使用的封装后的HttpsClient工具,同一时间最多只允许发起两个微信支付请求;当这两个请求没有迅速返回的时候(也就是网络抖动的时候),后面新的请求,只能排队等候,进而block住线程耗尽tomcat的线程;超时未生效的原因是因为CloseableHttpClient默认的实现对网络连接采用了连接池技术,当连接数达到最大连接数时,后续的请求只能排队等待连接,根本就无法取得发起网络请求的机会,所以也谈不上连接超时和响应超时;
系统本来应该这样:
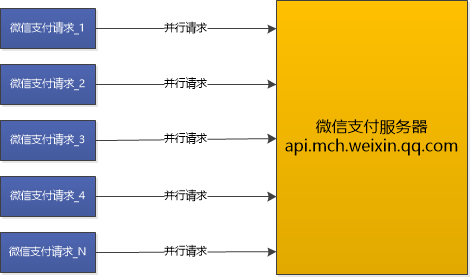
实际却是这样:

参考和论证
我们从HttpClient的官方文档中证实了这一点,同时也写程序进行了验证(这其中的配置比较复杂和深入,计划后续再写一篇文章进行说明,请持续关注汪汪队);
官方文档:http://hc.apache.org/httpcomponents-client-4.5.x/tutorial/html/connmgmt.html 2.3.3. Pooling connection manager
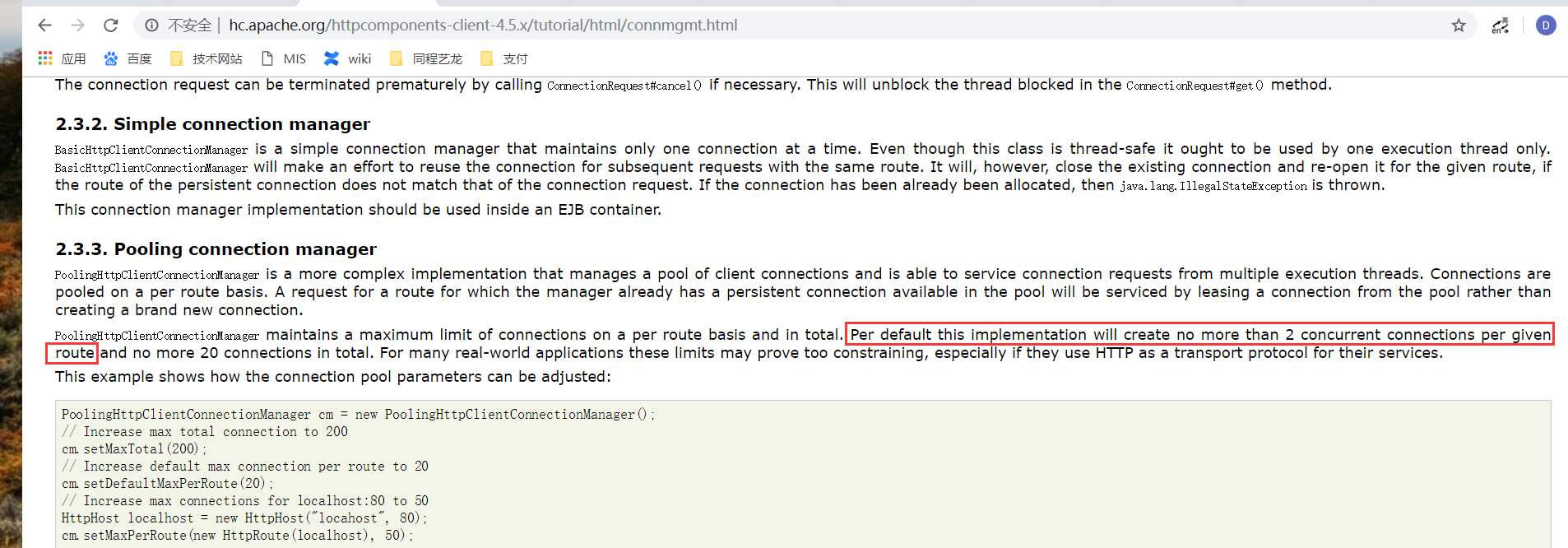
我们访问微信支付域名api.mch.weixin.qq.com,无论我们发起多少个请求, 在httpclient中就是对应一个route(一个host和port对应一个route),而每个route默认最多只有两个connection;而这个Route的默认值,我们代码中没有修改。所以,一台tomcat,实际上同一时间最多只会有两个请求发送到微信。网络抖动的时候,请求都会需要很长时间才能返回,因为我们设置的是3秒响应超时,所以,当网络抖动时,我们单台机器的qps就是3秒2个,极限情况下一分钟最多40个请求;更糟糕的情况,我们的程序中微信退款的超时时间设置的是30秒,所以如果是退款请求,那就是1分钟只能处理4个请求,10台服务器一分钟也就只能处理40个请求;因为支付和退款都是共用的一个HttpClient连接池,所以退款和支付会互相影响;
按照HttpClient的设计,支付系统真实请求过程大概如下:
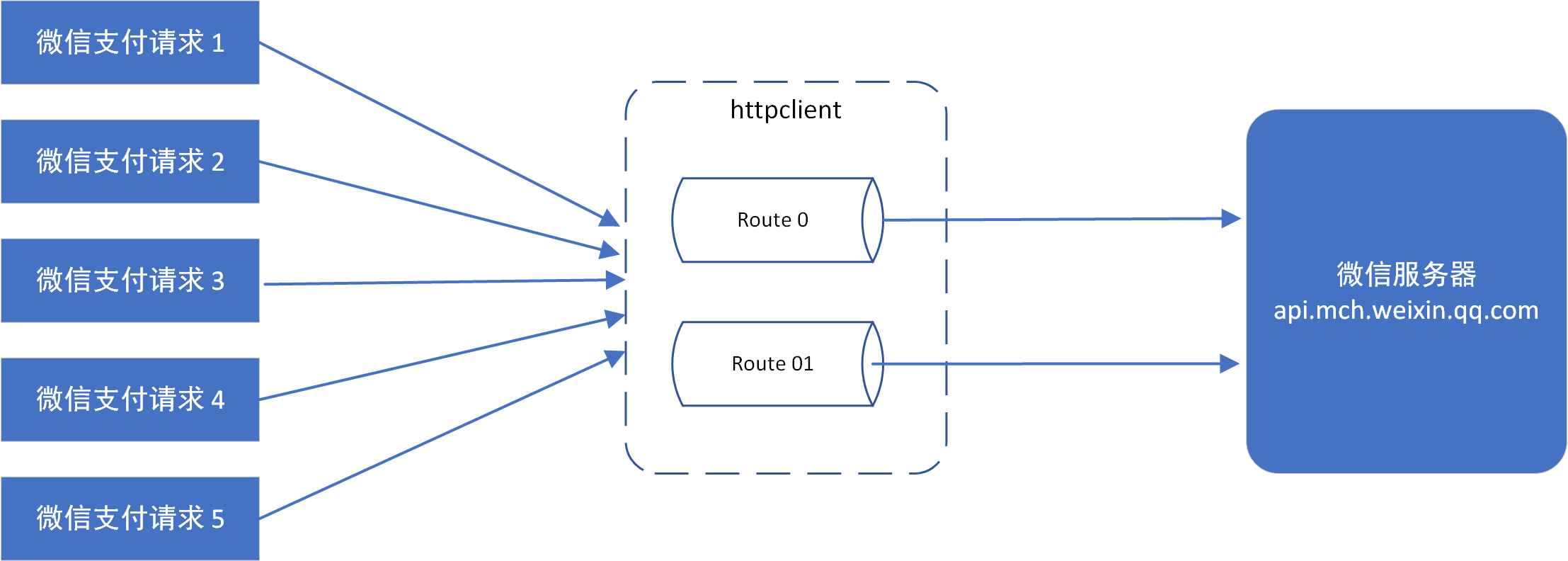
经验教训
1、对于微信支付,缺少压测。之前压测都是基于支付宝,而支付宝的调用模式和微信完全不一样,导致无法及时发现这个瓶颈;
2、研发对HttpClient等使用池技术的组件,原理了解不够深入,没有修改默认策略,最终形成了瓶颈;
3、对报警细节观察不是很到位,每次网络抖动我们只看到了网络方面的问题,却忽略了程序中超时参数未生效的细节,从而多次错失发现程序缺陷的机会,所以“细节决定成败”;
知识点
1、HttpClient,Route
2、微信支付
3、池技术
更多案例请关注微信公众号猿界汪汪队

- 还没有人评论,欢迎说说您的想法!
 客服
客服


