
0x00 机器学习基础
机器学习可分为三类
- 监督学习
- 无监督学习
- 强化学习
三种学习类别的关键点
- 监督学习需要人为设置参数,设置好标签,然后将数据集分配到不同标签。
- 无监督学习同样需要设定参数,对无标签的数据集进行分组。
- 强化学习需要人为设置初始参数,然后通过数据的反馈,不断修改参数,使得函数出现最优解,也即我们认为最完美的策略。
机器学习的原理
- 向系统提供数据(训练数据或者学习数据) 并通过数据自动确定系统的参数。
机器学习常见算法有很多,比如
- 逻辑回归
- 支持向量机
- 决策树
- 随机森林
- 神经网络
但是是否真的需要按照概率论->线性代数->高等数学->机器学习->深度学习->神经网络这个顺序去学呢?
- 不一定,因为等你学完,可能会发现自己真正需要的一些东西学的不够清楚,反倒是学了一堆只是看过一次之后就不会用到的知识点。
0x01 强化学习背景
强化学习刚出现时非常火爆,但是之后却逐渐变冷。主要原因在于强化学习不能很好的解决状态缩减表示,智能体主要存在着状态和动作,比如状态可看作人类在地球的某个位置,动作可看作人类走路,如果我们很清楚人类的位置和动作其实就能预测出人的下一个状态和动作,但是事实上智能体需要通过枚举的方式将所有可能的状态汇集到一张表中,而就我们这个例子来说,一个人的下一个状态实在是太多了,比如现在我位于北京,我下一步飞到上海,飞到南京,没有谁清楚我到底飞哪里。为什么AI不能突破到强人工智能?我认为主要还是算力不够,没办法把智能体的所有状态都列举出来。现今因为深度学习可以对大量的数据进行降维处理,使得数据集保有了特征的同时缩小了体积,使得同样的算力情况下,强化学习能够收集到智能体更多的状态用来获得最优解,所以出现了新的概念,叫做深度强化学习,它是将深度学习与强化学习结合的强化学习的加强版,这种学习可以完成对于人类来说非常困难的任务。
0x02 迷宫的建立
import numpy as np
import matplotlib.pyplot as plt
fig=plt.figure(figsize=(5,5))
ax=plt.gca()
# 画墙壁
plt.plot([1,1],[0,1],color='red',linewidth=3)
plt.plot([1,2],[2,2],color='red',linewidth=2)
plt.plot([2,2],[2,1],color='red',linewidth=2)
plt.plot([2,3],[1,1],color='red',linewidth=2)
# 画状态
plt.text(0.5,2.5,'S0',size=14,ha='center')
plt.text(1.5,2.5,'S1',size=14,ha='center')
plt.text(2.5,2.5,'S2',size=14,ha='center')
plt.text(0.5,1.5,'S3',size=14,ha='center')
plt.text(1.5,1.5,'S4',size=14,ha='center')
plt.text(2.5,1.5,'S5',size=14,ha='center')
plt.text(0.5,0.5,'S6',size=14,ha='center')
plt.text(1.5,0.5,'S7',size=14,ha='center')
plt.text(2.5,0.5,'S8',size=14,ha='center')
plt.text(0.5,2.5,'S0',size=14,ha='center')
plt.text(0.5,2.3,'START',ha='center')
plt.text(2.5,0.3,'END',ha='center')
# 设置画图范围
ax.set_xlim(0,3)
ax.set_ylim(0,3)
plt.tick_params(axis='both',which='both',bottom='off',top='off',labelbottom='off',right='off',left='off',labelleft='off')
# 当前位置S0用绿色圆圈
line,=ax.plot([0.5],[2.5],marker="o",color='g',markersize=60)
# 显示图
plt.show()
运行结果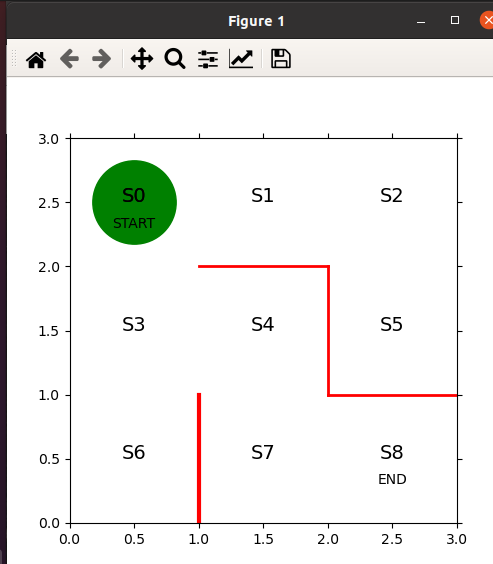
0x03 策略迭代算法
对于我们人类而言,一眼就可以看出怎么从START走到END S0->S3->S4->S7-S8
那么对于机器而言,我们正常套路是通过编程直接写好路线解决这种问题,不过这样的程序依赖的主要是我们自己的想法了,现在我们要做的是强化学习,是让机器自己根据数据学习怎么走路线。
基本概念
- 强化学习中定义智能体的行为方式的规则称为策略 policy 策略 使用 Πθ(s,a)来表示 ,意思是在状态s下采取动作a的概率遵循由参数θ决定的策略Π。
在这里,状态指的是智能体在迷宫的位置,动作指的是向上、右、下、左的四种移动方式。
Π可用各种方式表达,有时是函数的形式。
这里可通过表格的方式,行表示状态,列表示动作,对应的值表示概率来清楚的表示智能体下一步运动的概率。
若Π是函数,则θ是函数中的参数,在这里表格中,θ表示一个值,用来转换在s状态下采取a的概率。
定义初始值
theta_0=np.array([[np.nan,1,1,np.nan], #S0
[np.nan,1,np.nan,1], #S1
[np.nan,np.nan,1,1], #S2
[1,1,1,np.nan], #S3
[np.nan,np.nan,1,1], #S4
[1,np.nan,np.nan,np.nan], #S5
[1,np.nan,np.nan,np.nan], #S6
[1,1,np.nan,np.nan], #S7
]) # S8位目标 不需要策略
运行结果
:
[m,n]=theta.shape # 获取矩阵大小
pi=np.zeros((m,n))
for i in range(0,m):
pi[i,:]=theta[i,:] / np.nansum(theta[i,:]) # 计算百分比
pi=np.nan_to_num(pi) # 将nan转换成0
return pi
运行结果
就目前来说,可满足不撞墙,并且随机移动的策略。
定义移动的状态
def get_next_s(pi,s):
direction=["up","right","down","left"]
next_direction=np.random.choice(direction,p=pi[s,:])
# 根据概率去选择方向
if next_direction=="up":
s_next=s-3 # 向上移动时状态数字-3
if next_direction=="right":
s_next=s+1 # 向右移动时状态数字+1
if next_direction=="down":
s_next=s+3 # 向下移动时状态数字+3
if next_direction=="left":
s_next=s-1 # 向左移动时状态数字-1
return s_next
定义最终的状态
def goal_maze(pi): # 根据定义的策略持续移动.
s=0 # 设置开始地点
state_history=[0] # 记录智能体轨迹的列表
while (1): # 循环执行,直到智能体到达终点
next_s=get_next_s(pi,s)
state_history.append(next_s) # 在记录表中记录下一步状态
if next_s==8: # 到达终点
break
else:
s=next_s
return state_history
根据我们所设想的,最短路径是下右下右 此时的状态是8 所以选择状态为8 表示最终路径。
但实际上智能体根据我们开始设置好的θ值去运动的话,是随机运动,只要结果为8就停止,所以有各种各样的运动路径,我们需要做的是想办法让智能体自己学习走一条最短路径
上诉代码运行实例
第一个结果为原θ 第二个结果为我们转换成概率的θ,第三个结果为设置智能体的状态,未设置动作,然后根据θ指定策略,通过该策略让智能体持续移动,可能会产生各种各样的结果
上述完整代码
import numpy as np
import matplotlib.pyplot as plt
def plot():
fig=plt.figure(figsize=(5,5))
ax=plt.gca()
# 画墙壁
plt.plot([1,1],[0,1],color='red',linewidth=3)
plt.plot([1,2],[2,2],color='red',linewidth=2)
plt.plot([2,2],[2,1],color='red',linewidth=2)
plt.plot([2,3],[1,1],color='red',linewidth=2)
# 画状态
plt.text(0.5,2.5,'S0',size=14,ha='center')
plt.text(1.5,2.5,'S1',size=14,ha='center')
plt.text(2.5,2.5,'S2',size=14,ha='center')
plt.text(0.5,1.5,'S3',size=14,ha='center')
plt.text(1.5,1.5,'S4',size=14,ha='center')
plt.text(2.5,1.5,'S5',size=14,ha='center')
plt.text(0.5,0.5,'S6',size=14,ha='center')
plt.text(1.5,0.5,'S7',size=14,ha='center')
plt.text(2.5,0.5,'S8',size=14,ha='center')
plt.text(0.5,2.5,'S0',size=14,ha='center')
plt.text(0.5,2.3,'START',ha='center')
plt.text(2.5,0.3,'END',ha='center')
# 设置画图范围
ax.set_xlim(0,3)
ax.set_ylim(0,3)
plt.tick_params(axis='both',which='both',bottom='off',top='off',labelbottom='off',right='off',left='off',labelleft='off')
# 当前位置S0用绿色圆圈
line,=ax.plot([0.5],[2.5],marker="o",color='g',markersize=60)
# 显示图
plt.show()
def int_convert_(theta): # 设置策略中的参数θ
[m,n]=theta.shape # 获取矩阵大小
pi=np.zeros((m,n))
# print(pi,m,n)
for i in range(0,m):
pi[i,:]=theta[i,:] / np.nansum(theta[i,:]) # 通过循环遍历行,对每行里的值进行计算百分比
#nansum(theta[i,:]) 为除了nan之外的数字的个数和
pi=np.nan_to_num(pi) # 将nan转换成0
return pi
def get_next_s(pi,s): # 设置智能体的下一步状态
direction=["up","right","down","left"]
next_direction=np.random.choice(direction,p=pi[s,:])
# 根据概率去选择方向
if next_direction=="up":
s_next=s-3 # 向上移动时状态数字-3
if next_direction=="right":
s_next=s+1 # 向右移动时状态数字+1
if next_direction=="down":
s_next=s+3 # 向下移动时状态数字+3
if next_direction=="left":
s_next=s-1 # 向左移动时状态数字-1
return s_next
def goal_maze(pi): # 根据定义的策略持续移动.
s=0 # 设置开始地点
state_history=[0] # 记录智能体轨迹的列表
while (1): # 循环执行,直到智能体到达终点
next_s=get_next_s(pi,s)
state_history.append(next_s) # 在记录表中记录下一步状态
if next_s==8: # 到达终点
break
else:
s=next_s
return state_history
if __name__=="__main__":
theta_0=np.array([[np.nan,1,1,np.nan], #S0
[np.nan,1,np.nan,1], #S1
[np.nan,np.nan,1,1], #S2
[1,1,1,np.nan], #S3
[np.nan,np.nan,1,1], #S4
[1,np.nan,np.nan,np.nan], #S5
[1,np.nan,np.nan,np.nan], #S6
[1,1,np.nan,np.nan], #S7
]) # S8位目标 不需要策略
print(theta_0)
print(int_convert_(theta_0))
state_history=goal_maze(int_convert_(theta_0))
print(state_history)
print("求解迷宫路径步数为"+str(len(state_history)-1))
plot()
查看智能体运动轨迹
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import animation
from IPython.display import HTML
def plot():
fig=plt.figure(figsize=(5,5))
ax=plt.gca()
# 画墙壁
plt.plot([1,1],[0,1],color='red',linewidth=3)
plt.plot([1,2],[2,2],color='red',linewidth=2)
plt.plot([2,2],[2,1],color='red',linewidth=2)
plt.plot([2,3],[1,1],color='red',linewidth=2)
# 画状态
plt.text(0.5,2.5,'S0',size=14,ha='center')
plt.text(1.5,2.5,'S1',size=14,ha='center')
plt.text(2.5,2.5,'S2',size=14,ha='center')
plt.text(0.5,1.5,'S3',size=14,ha='center')
plt.text(1.5,1.5,'S4',size=14,ha='center')
plt.text(2.5,1.5,'S5',size=14,ha='center')
plt.text(0.5,0.5,'S6',size=14,ha='center')
plt.text(1.5,0.5,'S7',size=14,ha='center')
plt.text(2.5,0.5,'S8',size=14,ha='center')
plt.text(0.5,2.5,'S0',size=14,ha='center')
plt.text(0.5,2.3,'START',ha='center')
plt.text(2.5,0.3,'END',ha='center')
# 设置画图范围
ax.set_xlim(0,3)
ax.set_ylim(0,3)
plt.tick_params(axis='both',which='both',bottom='off',top='off',labelbottom='off',right='off',left='off',labelleft='off')
# 当前位置S0用绿色圆圈
line,=ax.plot([0.5],[2.5],marker="o",color='g',markersize=60)
# 显示图
plt.show()
def int_convert_(theta): # 设置策略中的参数θ
[m,n]=theta.shape # 获取矩阵大小
pi=np.zeros((m,n))
# print(pi,m,n)
for i in range(0,m):
pi[i,:]=theta[i,:] / np.nansum(theta[i,:]) # 通过循环遍历行,对每行里的值进行计算百分比
#nansum(theta[i,:]) 为除了nan之外的数字的个数和
pi=np.nan_to_num(pi) # 将nan转换成0
return pi
def get_next_s(pi,s): # 设置智能体的下一步状态
direction=["up","right","down","left"]
next_direction=np.random.choice(direction,p=pi[s,:])
# 根据概率去选择方向
if next_direction=="up":
s_next=s-3 # 向上移动时状态数字-3
if next_direction=="right":
s_next=s+1 # 向右移动时状态数字+1
if next_direction=="down":
s_next=s+3 # 向下移动时状态数字+3
if next_direction=="left":
s_next=s-1 # 向左移动时状态数字-1
return s_next
def goal_maze(pi): # 根据定义的策略持续移动.
s=0 # 设置开始地点
state_history=[0] # 记录智能体轨迹的列表
while (1): # 循环执行,直到智能体到达终点
next_s=get_next_s(pi,s)
state_history.append(next_s) # 在记录表中记录下一步状态
if next_s==8: # 到达终点
break
else:
s=next_s
return state_history
# 动画展示
def init():
# 初始化背景
line.set_data([],[])
return (line,)
def animate(i):
# 每一帧的画面
state=state_history[i]
x=(state % 3)+0.5
y=2.5-int(state/3)
line.set_data(x,y)
return (line,)
if __name__=="__main__":
theta_0=np.array([[np.nan,1,1,np.nan], #S0
[np.nan,1,np.nan,1], #S1
[np.nan,np.nan,1,1], #S2
[1,1,1,np.nan], #S3
[np.nan,np.nan,1,1], #S4
[1,np.nan,np.nan,np.nan], #S5
[1,np.nan,np.nan,np.nan], #S6
[1,1,np.nan,np.nan], #S7
]) # S8位目标 不需要策略
print(theta_0)
print(int_convert_(theta_0))
state_history=goal_maze(int_convert_(theta_0))
print(state_history)
print("求解迷宫路径步数为"+str(len(state_history)-1))
fig=plt.figure(figsize=(5,5))
ax=plt.gca()
# 画墙壁
plt.plot([1,1],[0,1],color='red',linewidth=3)
plt.plot([1,2],[2,2],color='red',linewidth=2)
plt.plot([2,2],[2,1],color='red',linewidth=2)
plt.plot([2,3],[1,1],color='red',linewidth=2)
# 画状态
plt.text(0.5,2.5,'S0',size=14,ha='center')
plt.text(1.5,2.5,'S1',size=14,ha='center')
plt.text(2.5,2.5,'S2',size=14,ha='center')
plt.text(0.5,1.5,'S3',size=14,ha='center')
plt.text(1.5,1.5,'S4',size=14,ha='center')
plt.text(2.5,1.5,'S5',size=14,ha='center')
plt.text(0.5,0.5,'S6',size=14,ha='center')
plt.text(1.5,0.5,'S7',size=14,ha='center')
plt.text(2.5,0.5,'S8',size=14,ha='center')
plt.text(0.5,2.5,'S0',size=14,ha='center')
plt.text(0.5,2.3,'START',ha='center')
plt.text(2.5,0.3,'END',ha='center')
# 设置画图范围
ax.set_xlim(0,3)
ax.set_ylim(0,3)
plt.tick_params(axis='both',which='both',bottom='off',top='off',labelbottom='off',right='off',left='off',labelleft='off')
# 当前位置S0用绿色圆圈
line,=ax.plot([0.5],[2.5],marker="o",color='g',markersize=60)
anim=animation.FuncAnimation(fig,animate,init_func=init,frames=len(state_history),interval=20,repeat=False,blit=True)
plt.show()
看动画很直观的反映,智能体虽然最终会到S8,但是并不是真的直接到S8,我们需要通过强化学习算法来让智能体学会怎么样以最短路径到达S8
主要有2种方式
- 根据策略到达目标时,更快到达目标的策略所执行的动作是更重要的,对策略进行更新,以后更多采用这一行动,强调成功案例动作。 (策略迭代法)
- 从目标反向计算在目标的前一步,前两步的状态,一步步引导智能体行为,它是一种给目标以外的位置附加价值的方案 。(价值迭代法)
这里可使用softmax函数将theta转成以指数的百分比。
def softmax_convert_into_pi_from_there(theta):
beta=1.0
[m,n]=theta.shape
pi=np.zeros((m,n))
exp_theta=np.exp(beta * theta)
for i in range(0,m):
pi[i,:]=exp_theta[i,:] / np.nansum(exp_theta[i,:])
pi=np.nan_to_num(pi) # 将nan转换成0
return pi
然后获取智能体的状态和动作
def get_action_and_next_s(pi,s): # 设置智能体的下一步状态
direction=["up","right","down","left"]
next_direction=np.random.choice(direction,p=pi[s,:])
# 根据概率去选择方向
if next_direction=="up":
action=0
s_next=s-3 # 向上移动时状态数字-3
if next_direction=="right":
action=1
s_next=s+1 # 向右移动时状态数字+1
if next_direction=="down":
action=2
s_next=s+3 # 向下移动时状态数字+3
if next_direction=="left":
action=3
s_next=s-1 # 向左移动时状态数字-1
return s_next
设置目标函数
def goal_maze_ret_s_a(pi): # 根据定义的策略持续移动.
s=0 # 设置开始地点
s_a_history=[[0,np.nan]] # 记录智能体轨迹的列表
while (1): # 循环执行,直到智能体到达终点
[action,next_s]=get_action_and_next_s(pi,s);
s_a_history[-1][1]=action # 代入当前状态 表示最后一个状态的动作
s_a_history.append([next_s,np.nan])
# 代入下一个状态,因为不知道他的动作,所以用nan
if next_s==8:
break
else:
s=next_s
return s_a_history
相比之前的策略,新的策略多了智能体的动作,从理论上来说,现在才真正有了智能体的雏形。
但只是这样 强化学习还是死的。
一定要通过数据使得策略中的θ发生改变,因为是策略迭代,每次运行时用的路径短则算优,在此基础上不断进行路径缩短,进行训练,最终找到最短路径。
根据策略梯度法更新策略
- 新的策略=旧策略+学习率*增加的策略
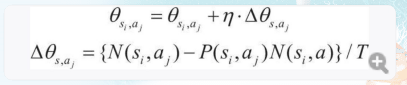
θsi,aj 表示一个参数,用来确定在状态si 下采取动作aj的概率 n被称为学习系数,控制θsi,aj在单次学习中更新的大小。n太小,则学习的慢,n太大则无法正常学习。
N(si,aj)是在状态si下采取动作aj的次数, P(si,aj)是在当前策略中状态si下采取动作aj的概率,N(si,a)是在状态si下采取动作总数。
仔细观察就能发现 假设智能体一开始在S0,准备向下运动,那么在该状态下的动作总为1 概率为 0.5 而在该状态下采取该动作次数为1 这样其实就是 0.5/T
而 如果 智能体 是 准备向下和右运动,该状态下动作总为2 对于 下动作来说 概率为0.5 而在该状态下采取该动作次数为1 这样其实θ并没发生改变。
如果 智能体是在S3准备运动,准备进行 下 右 上 三个方向运动 该状态下 动作 总为 3 每个的概率为1/3 而 采取某个动作的次数为1 这样其实也相当于θ没变化。
如果是重复 比如 S0-S3-S0-S3 对于这种情况,S0向动作向下,动作总数是1 概率为0.5 在该状态下采取动作次数为2 这样其实是 2-0.5/T而T,很明显这种情况T也会增大。
算法意义就是在保证θ几乎不变使得T减小,而T减小智能体智能在某个方向上走1次。
因为如果是重复走的话 T上的计算式会相对较大,此时T也会随之变大。
代码实现
def update_theta(theta,pi,s_a_history):
eta=0.1
T=len(s_a_history)-1
[m,n]=theta.shape
delta_theta=theta.copy()
for i in range(0,m):
for j in range(0,n):
if not(np.isnan(theta[i,j])):
SA_i=[SA for SA in s_a_history if SA[0] == i]
# 取状态i
SA_ij=[SA for SA in s_a_history if SA == [i,j]]
# 取状态i下应该采取的动作
print(SA_i)
N_i=len(SA_i) # 状态i下动作总次数
print(N_i)
print(pi[i,j])
N_ij=len(SA_ij) # 状态i 下采取动作j的次数
print(SA_ij)
print(N_ij)
delta_theta[i,j]=(N_ij-pi[i,j]*N_i)/T
new_theta=theta+eta*delta_theta
return new_theta
然后再通过重复搜索和更新迷宫中的参数θ,直到可以一路直线行走来解决迷宫问题
关键代码
stop_epsilon=10**-3 # 策略变化小于10的-4次方则结束学习
theta=theta_0
pi=pi_0
is_continue=True
count=1
while is_continue:
s_a_history=goal_maze_ret_s_a(pi) # 由策略Π去搜索
new_theta=update_theta(theta,pi,s_a_history) # 更新参数
new_pi=softmax_convert_into_pi_from_there(new_theta) # 更新策略
print(np.sum(np.abs(new_pi-pi))) # 输出策略变化
print("求解迷宫问题的步数"+str(len(s_a_history)-1))
if np.sum(np.abs(new_pi-pi))<stop_epsilon:
is_continue=False
else:
theta=new_theta
pi=new_pi
最后运行 结果 真实太妙了! 注意这里必须通过循环及时更新参数和策略。因为你一旦更新了第一波策略后,第二波策略相当于在进行不断试错,如果在某个方向上走一直导致出现很大的T,则会在第三波策略中降低这个方向的概率。这里设置theta为一个范围就是为了保证θ基本不变的情况下,因为如果重复次数多对于那个参数增加量的等式来说分子在增加,相应的分母也会变大,而对于某个状态只走一次的情况,分子是在减小的,所以T自然也会减小,那么问题来了,为什么更新策略,他们之间的差量会变小呢,策略的更新受到参数更新的影响,而参数更新是为了保证每次每个状态只走一个方向,一开始可能有一个状态走3个方向,更新一次后一个状态走2个方向,这之间策略的差值还是较大,通过不断试错,最终实现T不变,θ增加量一直减小,可确定一条最短路径。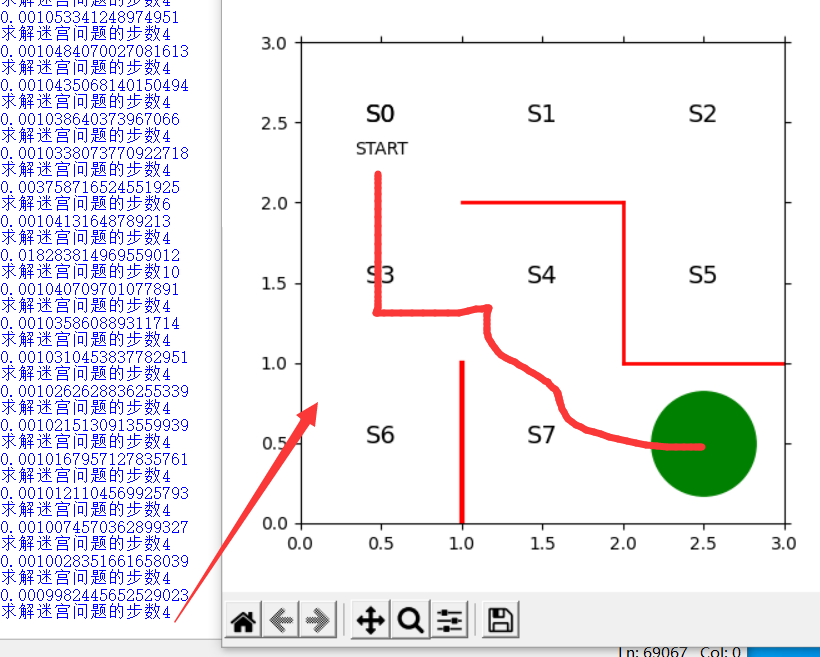
0x04 简单总结
策略迭代法让我感受到了强化学习的魅力所在,算法首先是通过策略定义了智能体的状态和动作,然后定义了参数θ作为控制量,同时代表了智能体下一步运动方向的概率,然后利用策略迭代,不断通过更新参数来更新策略,因为参数的变化由实际方向数-理想方向数的差与上一次记录的步数决定。而且有个隐含的定性条件,那就是在某个状态下某个方向只走一次,参数变化为几乎为0,考虑到每次更新参数后,单一状态的方向概率在改变。但是最终拟合的话T是接近一个常量,使得θ能够不断缩小,这样我们只需要设置θ的变化范围,使得θ保持几乎不变,可以认为已经找到了最短路径。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


