
Overcoming Language Priors with Self-supervised Learningfor Visual Question Answering
Abstract
大多数可视化问答(VQA)模型都是从语言先验问题出发的,而语言先验问题是由固有的数据偏差引起的。具体来说,vqa模型倾向于基于忽略图像内容的高频应答(例如黄色)来回答问题(例如,香蕉是什么颜色的?)。现有的方法通过创建精细的模型或引入额外的视觉注释来解决这个问题,以减少问题依赖性,同时增强图像依赖性。然而,由于数据偏差甚至没有得到缓解,他们仍然受到语言优先问题的影响。本文提出了一种自监督学习框架来解决这一问题。具体地说,我们首先自动生成标记数据来平衡有偏数据,然后提出了一个自我监督的辅助任务来利用平衡数据作为基础VQA模型来克服语言先验知识。我们的方法可以通过生成平衡的数据而不引入外部注释来补偿数据库。实验结果表明,在最常用的VQA-CP v2基准上,该方法的总体精度从49.50%提高到57.59%,显著优于现有的方法。换句话说,我们可以在不使用外部注释的情况下将基于注释的方法的性能提高16%。
1 Introduction
视觉问答(VQA)作为完整的人工智能的任务越来越受到关注,其目标是根据图像自动回答自然语言问题。VQA的范式[Antolet al., 2015; Yanget al.,2016 年;Andersonet al.,2018 年; Kimet al., 2018]是将图像和问题投影到一个公共特征空间中,然后将它们融合为一个联合向量进行预测。最近,一些研究人员[Agrawalet al., 2018; Goyalet al., 2017]已经证明大多数现有的 VQA 模型都受到了从语言先验问题的影响,忽略图像内容。 例如,“草是什么颜色的?”这个问题,无论给出什么图像,一般都可以用“绿色”来回答,因为数据集中大部分对应的答案都是“绿色”。 因此,记忆语言先验的模型在域外数据集上表现不佳。
现有的语言先验缓解方法侧重于减少问题依赖性,同时增加图像依赖性,大致可以分为非基于注释的方法和基于注释的方法。对于非基于注释的方法,研究人员大多设计具有不同特征的精细模型、 策略。 例如,[Ramakrishnanet al., 2018] 提出了一种对抗性学习策略,通过最小化仅问题分支对抗性的表现来克服语言先验。 Rubi[Cadeneet al., 2019]通过动态调整权重减少了最大偏差实例的影响并增加了最小偏差实例的影响。基于注释的方法试图通过引入外部视觉监督来直接增加图像依赖性 .[Selvarajuet al., 2019]使用人类注意力图来确保模型注意力和人类注意力之间的对齐。[Wu and Mooney, 2019]保持正确答案和人类解释注释的有影响力的对象的一致性。 通常,基于注释的方法可以获得比非基于注释的方法更好的性能,因为它们可以在视觉监督的指导下更好地理解图像。 尽管如此,这些方法需要大规模的视觉注释,这些注释不容易获得。
然而,固有的数据偏差没有被消除,而上述方法只是在一定程度上削弱了它们的不利影响,因此产生的效果表现并不理想。固有的数据偏差将不可避免地迫使 VQA 模型倾向于具有更高置信度的高频答案,最终引起语言先验问题。 因此,解决固有的数据偏差至关重要,即将有偏差的数据转换为平衡数据而不引入外部注释。
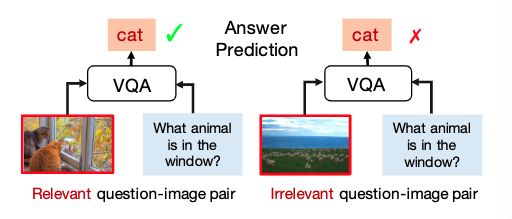
为此,我们为 VQA 提出了一种自监督学习框架,以自动平衡有偏见的数据以克服语言先验问题。我们的方法受到一个有趣且直观的发现的启发。 如图所示,只有当给定的图像包含回答问题的关键信息时,才能回答问题。 我们将这样的问题-图像对定义为相关的,否则是不相关的。基于以上观察,有必要在回答问题之前估计给定的问题和图像是否相关。为此,我们引入了一个名为问题-图像相关性估计的辅助任务来估计问题和图像之间的相关性。具体来说,我们首先自动生成一组带有二元标签(相关和不相关)的平衡问题-图像对,然后输入自监督辅助任务,以帮助 VQA 模型克服语言先验。我们通过提供相关和不相关的对,将辅助任务合并到基础 VQA 模型中。 当输入相关的问题-图像对时,鼓励VQA模型以高置信度预测正确答案,其中置信度得分是问题-图像对相关的概率。相反,当输入对不相关时,VQA模型被推到低置信度的情况下预测正确答案。此外,不相关对的置信度得分可以作为衡量语言先验的指标,避免过度拟合,通过同时优化这两个目标,我们可以在回答问题和克服语言先验之间取得平衡。因此,我们的方法也可以解释为一个潜在的多任务学习框架。
总而言之,我们的贡献如下:
我们通过将固有偏见数据自动转换为平衡数据来引入自监督框架,并提出一个辅助任务来利用这种平衡数据从根本上克服语言先验。 据我们所知,这是第一个在该领域使用自监督学习的作品。在流行的基准 VQA-CP v2 上进行了大量实验。 实验结果表明,我们的方法在不使用外部注释的情况下可以显着优于最先进的方法,包括使用人工监督的模型。 我们将整体准确率从 49.50% 提高到 57.59%
2 Related Works
2.1 Visual Question Answering
视觉问答(VQA)旨在根据图像回答问题,涉及自然语言处理和计算机视觉的技术[Liuet al., 2016; Parkhiet 等人,2015 年; Conneau等人,2016 年; Liu等人,2018 年]。现有的 VQA 方法可以粗略地分为四类:1) 联合嵌入方法 [Antolet al., 2015] 首先将图像和问题投影到一个公共特征空间中,然后通过分类器将它们组合起来预测答案。 2)基于注意力的方法[Andersonet al., 2018]主要侧重于学习问题词和图像区域之间的相互作用,使回答过程更具可解释性。 3) 组合模型[Andreaset al., 2016]利用问题的组合结构来组装在注意力空间中运行的模块。 4) 基于知识的方法 [Wuet al., 2016] 被提议通过利用外部知识来回答常识问题。
然而,现有模型倾向于在训练过程中记忆语言先验而不考虑图像信息。这种模型可能会在与训练集共享相同分布的测试集上取得意想不到的令人印象深刻的结果,但在域外测试集上往往表现不佳
2.2 Overcoming Language Priors in VQA
现有的旨在克服语言先验的方法可以粗略地分为非基于注释的方法和基于注释的方法。 非基于注释的方法专注于创建精细模型以减少问题依赖性,而基于注释的方法则专注于通过引入额外的人类视觉监督来加强视觉基础。
对于非基于注释的方法,[Agrawalet al.,2018] 提出了一个手工设计的 VQA 框架,该框架将不同问题类型的视觉识别与答案空间预测有效分离。 同样,[Jinget al.,2020]也将概念发现和问答解耦。 除了缩小答案空间之外,[Ramakr-ishnanet al., 2018]提出了一种对抗性学习策略,通过对抗性地最小化仅问题分支的性能。[Guoet al., 2019]采用了成对排序模式,强制仅问题 分支做出比基本模型更糟糕的预测。 Rubi [Cadeneet al., 2019] 通过仅问题分支学习的先验掩码动态调整训练实例的权重,减少最偏向实例的影响并增加偏向较少实例的影响。 [?] 提出了一种神经网络 -符号模型将符号程序执行器纳入DNN进行视觉推理,与上述模型不同,也可以解决偏差问题。 [?]将神经符号模型与课程概念学习相结合,使其更具泛化性。
除此之外,通过在外部视觉监督的指导下突出重要的视觉区域,基于注释的方法被证明是有效的。 提示 [Selvarajuetal., 2019] 通过优化人类注意力图和基于梯度的视觉重要性之间的对齐来增加图像依赖性。 SCR[Wu and Mooney, 2019] 也强调了正确答案与人类文本解释标注的有影响的对象之间的对应关系。然而,这些模型严重依赖于人类的监督,这并不总是可以访问的。
除此之外,通过在外部视觉监督的指导下突出重要的视觉区域,基于注释的方法被证明是有效的。[Selvarajuetal., 2019] 通过优化人类注意力图和基于梯度的视觉重要性之间的对齐来增加图像依赖性。 SCR[Wu and Mooney, 2019] 也强调了正确答案与人类文本解释标注的有影响的对象之间的对应关系。然而,这些模型严重依赖于人类的监督,这并不总是可以办到的。
与所有这些方法不同,我们的自监督方法不需要构建复杂的架构或引入外部监督。我们首先平衡原始的偏差数据通过自动生成平衡标签,克服了基于平衡数据的语言先验知识,并以自监督的方式辅助任务。
2.3 Self-supervised Learning
自监督学习从输入数据中自动计算出一些监督信号,并有效地利用输入本身来学习一些下游任务的高级表示。 例如,[Gidarisetal., 2018] 提出将图像随机旋转四个可能的角度之一,让模型预测该旋转。除了尝试预测旋转之外,还可以尝试恢复部分数据,例如图像补全 [Pathaket al., 2016]。 在本文中,我们利用自监督学习进行问题图像相关性估计作为辅助任务来帮助 VQA 模型克服语言先验。 我们随机改变原始相关问题-图像对中的图像,然后让模型预测其相关性。
3 Method
我们方法的框架如图所示。接下来,我们将详细描述它是如何工作的。

我们的自我监督方法的框架。 (a) 部分描述了基本 VQA 模型,其目的是根据图像回答问题。 (b) 显示我们如何自动生成平衡的问题-图像对。 更清楚地说,(c) 显示了问题-图像相关性估计如何分别对相关和不相关对起作用。 G-T 表示基本事实。
3.1 The Paradigm of VQA
VQA 的目的是根据图像自动回答文本问题。具体来说,给予一个包含N个数据的VQA的数据集(D={I_i,Q_i,A_i}_{i=1}^N),其中(I_iin I,Q_iin Q)分别是第i个数据的图像和问题。(A_iin A)作为答案。VQA的模型指向去学习一个映射函数(F:Itimes Q rightarrow R^A)去预测答案的精确分布。它通常由三部分组成:提取图像和问题的特征,融合它们以获得联合多模态表示,以及预测答案空间的分布。因此我们可以将第(i)个图像和为题的答案预测写为(F(A|I_i,Q_i))。几乎所有现有的 VQA 模型[Yanget al., 2016; Kimet al., 2018; Andersonet al., 2018]遵循这个范式,它们的参数通常通过最小化交叉熵损失方程或多标签软损失方程来优化。
答案预测:
最小化交叉熵损失方程:
多标签软损失方程:
其中(sigma (cdot))表示sigmoid函数,(t_i)是第(i)个样本的每个答案的软注意力,表示为(t_i=frac{number of votes}{n}),其中(n)表示为第(i)问题的有效答案数量,(number of votes)是人类为该问题注释的每个答案的数量。
3.2 Question-Image Correlation Estimation
记忆语言先验的VQA模型倾向于直接忽略图像进行预测。理想情况下,一个问题只有在给定的图像包含与之相关的信息时才能得到回答。因此,要求VQA模型在回答特定问题之前判断给定的图像是否可以作为参考是非常重要的,这一点几乎被以往所有的工作所忽略,因为现有的测试中所有的问题图像对都是正确匹配的。我们说明,这种评估对于减轻VQA中的语言先验性是必要的,因为它会迫使模型引用图像内容,而不是盲目地回答。为此,我们提出了一个辅助任务,称为问题图像相关估计(QICE),一个二分类任务,在回答问题之前预测问题图像对是否相关。在本文中,我们定义了相关的问题-图像对,因为图像可以用来回答具有特定答案的问题。
Generate balanced question-image pairs
我们首先从原始数据集自动生成一组带标签的问题-图像对,而不需要人为注释,用于辅助任务,如图2(b)所示。具体地说,训练集中的每个问题图像对((Q,I))都被视为标签(c=1)的相关对,因为在数据集中有这一对的答案。然后对每一对相关的((Q,I)),我们从图像集中随机选择图像来替换原始图像。通过这种方法,我们可以得到另一个问题图像对((Q,I')),该图像对为相关的概率非常小,因此我们使用标签(c=0)表示不相关。因此,我们可以得到一个平衡的问题-图像对匹配数据集,其中相关对的数目与不相关对的数目相等。注意,平衡数据的构造不需要任何人工注释。
Correlation estimation
利用生成的均衡数据,通过优化交叉熵损失,训练QICE模型预测每个问题图像对的相关标签。
(L_{self})可以解释为一种自我监督的训练损失,它只利用我们生成的数据的标签监督。目标函数保证了QICE模型对问题和图像内容的理解,因为每个Q对应于平衡的相关和不相关的立场,不依赖任何语言先验。在下一小节中,我们将讨论如何利用辅助任务QICE和平衡数据来帮助VQA模型在统一的框架中消除语言偏见。
3.3 Unified Self-supervised Framework
在本节中,我们提出了一个统一的VQA框架,可以在训练期间同时回答问题和估计问题-图像相关性。显然,上面定义的QICE任务可以与VQA共享相同的网络结构,因为它们具有完全相同的输入和相似的输出:它们都以问题-图像对((I,Q))为输入,VQA预测答案空间上的分布,而QIC在特定答案上产生一个二进制标签。这种特性促使我们在统一的VQA框架中同时解决这两个任务,如方法的框架图所示。
对于图(a)中描述的VQA模型。取相关的问题图像对((Q,I))作为输入,预测其答案的分布(F(A|Q,I)),可以通过最小化VQA损失(L_{vqa_{ce}})或者是(L_{vqa_{ml}})来训练。这个目标函数教导模型学习回答问题的能力。对于图(c)所示的QICE,给定与特定答案相对应的图像对((I,Q)),VQA模型的预测概率(P(A|Q,I))可以视作为两者相关的置信度,概率越大,匹配度越高。因此(L_{self})能够被重写为:
该模型要求对问题-图像相关估计任务做出正确的二值预测,因为每个问题都有等量的相关和不相关的图像配对,从而使模型更好地理解图像。更具体地说,(L_{self})项旨在最大限度地提高问题-图像对的可信度,这与VQA任务的目标一致,VQA任务的目标是以高可信度对地面真实情况进行预测。
最重要的是,(L_{self})的第二项被设计为最小化相关对的置信度,正好可以满足语言先验知识的约简。直观地说,VQA模型的问题依赖性可以通过给定不相关图像时正确回答问题的可信度来衡量。置信度越大,依赖性越强。最小化相关的不相关对的可信度可以明确地防止VQA模型被语言先验的过度驱动,这里我们称之为问题依赖损失(L_{qd}):
我们省略了(c_i)因为(L_{qd})支队无关的问题图像对((Q,I'))有效。数学上,最小化(-log(1-P(A|Q,I')))等同于最小化(P(A|Q,I'))。实验上,训练过程中最小化(P(A|Q,I'))比最小化(-log(1-P(A|Q,I')))更稳定。这是因为(P(A|Q,I')) 的梯度比(-log(1-P(A|Q,I')))更加稳定。因此损失函数(L_{qd})更新为如下:
因此,QICE任务可以自然地看作是一种潜在的的多任务学习,它包含两个任务:原始VQA任务和语言先验约简任务。我们可以将(L_{self})重新组织如下
其中(L_{vqa})可以是任何的VQA损失函数(L_{vqa_{ce}})或者(L_{vqa_{ml}})然后(alpha)是一个超参数。很明显,(L_{self})可以被看作是一种普遍的VQA损失,当(alpha=0)时,它将退化为(L_{vqa}),这意味着问题依赖损失(L_{qd})实际上起到了正则化的作用,阻止了VQA模型记忆语言的先验知识,迫使它更好地理解图像。因此,(L_{self})在控制回答问题和减少语言优先级之间的平衡方面提供了灵活性。此外,我们不需要显式地优化模型,就可以熟练地估计问题图像对的相关性,我们只需要使用它的平衡监督来补偿VQA中的偏差和我们的自我监督损失,我们的方法可以在不使用外部监督的情况下,以一种自我监督的方式减少语言先验知识。
4 Experiments
4.1 Datasets and Baselines
Datasets
我们的方法基于最常用的基准VQA-CP v2[Agrawalet al.,2018],使用标准评估指标[Antolet al.,2015]进行评估。VQA-CPv2数据集源自VQA v2[Goyalet al.,2017],通过重新组织训练和验证拆分,训练集和测试集中的QA对具有不同的分布。因此,它适合于评估模型的可推广性,我们也在包含强偏差的vqav2数据集上评估了我们的模型,并报告了其验证结果。
Baselines
我们的方法与几种方法进行了比较,包括(1)基于非注释的方法:UpDn[Ander sonet et al.,2018]、AdvReg[Ramakrishnanet al.,2018]、Rubi[Anderson et al.,2018]和DLR[Jinget al.,2020](2) 基于注释的方法:HINT[Selvarajuet al.,2019]和SCR(最佳执行方法)[Wu和Mooney,2019]。
4.2 Implementations Details
我们的方法是模型不可知的,可以很好地应用于不同的VQA模型。在本文中,我们主要评估我们基于UpDn的方法[Anderson等人,2018],并在分类器之前添加一个批处理规范化层。按照基线,我们使用预先训练的Faster R-CNN来提取图像特征。对于每幅图像,它被编码为一组36个具有2048维特征向量的对象,所有问题被填充到相同的长度14。对于每个问题,单词被300维手套嵌入初始化,然后输入GRU,得到一个1280维的句子级表示。
我们用12个epochs的VQA损失对模型进行预训练,并用20个epochs的自监督损失对模型进行微调,批量大小为256,从小批量中随机选择不相关的图像。采用Adam优化器,初始学习率为0.001,10个周期后每5个周期减半一次。在我们的主要实验中,我们用不同的VQA损失来评估我们的方法,多标签VQA损失设置α=3,交叉熵VQA损失设置α=1.2。本文的其他实验都是基于α=3的多标签VQA损失,下一小节还讨论了超参数α的设置。
4.3 Experimental Results and Analysis
Comparison with state-of-the-art
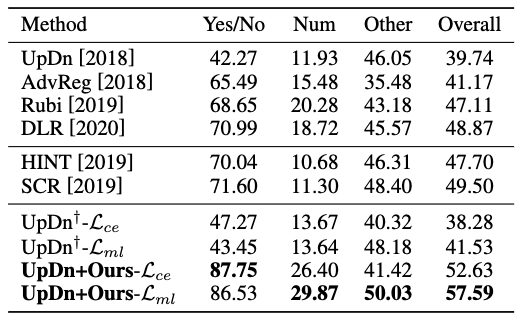
我们的方法分别基于两个VQA损失(交叉熵损失和多标签损失)进行了测试。为了消除随机抽样策略的随机性,我们在测试集上报告了10个实验的平均分数。从下表的结果可以看出:(1)我们的方法不仅可以提高基线UpDn的整体性能(交叉熵损失为+14.35%,多标签损失为+16.06%),而且显著优于性能最好的方法SCR(交叉熵损失为+3.13%,多标签损失为+8.09%)(2) 基于这两个VQA损失的改进都是显著的。通常,使用多标签损失可以获得更好的性能,因为它与评估方法一致,并考虑了多个可行的答案,这表明更具普遍性(3)无论VQA的损失使用什么我们可以在“是/否”问题类型上获得极高的准确率(87.75%和86.53%),这表明我们的策略确实能够有效地克服语言先验知识,因为这些简单问题中更可能存在偏见(4) 对于最难的“Num”问题,我们也可以得到令人惊讶的改进,这有力地说明我们的方法可以共同理解图像和问题,并有效地进行推理。
Performance on smaller training sets
为了进一步证明这种方法的优越性,我们对原始训练集随机抽取不同数量的训练数据进行了一系列实验。所有的实验都在标准测试集上进行了测试,结果如下表所示。我们发现我们的方法比基线UpDn的平均精度提高了+16.6%。最重要的是,即使有20%的训练数据,我们的方法也可以大大超过在整个训练集中由外部监督训练的最佳表现方法。我们相信,这是因为我们的方法可以在正则化器的帮助下有效地撬动平衡数据,更可能表现出极大的普遍性。

Performance based on different baselines
我们还基于另外两个VQA模型进行了实验:SAN[Yanget al.,2016]和BAN[Kimet al.,2018]。结果如下表所示,我们可以观察到不同基线的改进都是显著的和一致的,这表明我们的方法是模型不可知的。

Performance on biased VQA dataset
我们还对包含强语言偏差的VQA v2数据集进行了评估。我们对模型进行6个epochs的VQA损失预训练,然后对其进行10个epoches的微调。结果如表4所示。我们的方法在VQA v2 val上获得了精度改进,而其他方法可能会导致下降。这背后的原因是我们的自我监督损失能够在回答问题和消除语言先验之间取得平衡。

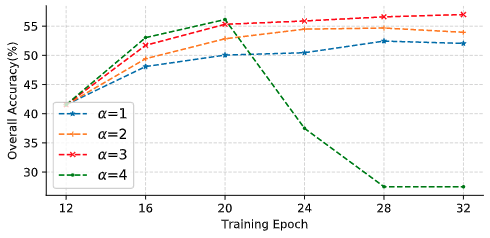
Impact of different (alpha)
为了研究在回答问题和克服语言先验之间进行权衡的超参数(alpha)的影响,我们在不同的(alpha)设置下进行了广泛的实验。由于篇幅的限制,本文只分析了使用多标签VQA损失的情况,如下图所示。当(alpha=3)时,模型的性能更高。而且,一个大的α可能会导致模型在几个时期后崩溃,而一个小的(alpha)则会导致性能不理想。
Qualitative analysis
我们定量地评估了我们方法的有效性。如下图所示,我们的方法可以正确地回答问题,并将重点放在正确的区域。例如,在回答“这是职业游戏吗?”这一问题时,我们的方法可以更多地关注男人衣服上的人物,这可能是判断游戏是否职业的重要视觉线索。

5 Conclusion
本文提出了一种新的自监督学习框架来克服VQA中的语言先验问题。基于一个模型无关辅助任务,该框架能够有效地利用自动生成的平衡数据来减轻数据集偏差的影响。实验结果表明,该方法在回答问题和克服语言先验知识之间取得了平衡,取得了较好的整体学习效果,在最常用的VQA-cpv2标准上取得了新的水平,我们相信,我们的工作可以成为现实的VQA和解决语言偏差问题的一个有意义的步骤,并且这种自我监督可以推广到其他受固有数据偏差影响的任务(例如,image caption)。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


