
不同的自然语言有不同的语法结构,因此需要对语言数据进行语法解析,才能让机器更准确地学到相应的模式。儿语言不同于图像,数据标注工作需要有一定的语言学知识,因此数据的整理也相对更困难。下面以英语为例(别的咱也看不懂),对NLP研究中常见的基本语言学概念进行记录。
词性(Part Of Speech)
词性(Part Of Speech, POS)通常在初中就学过:名词、动词、形容词、副词等,这里不再赘述。由于同一个词有多种不同词性的可能,因此数据标注时对语句中各个词的词性的标注就十分重要,从而消除词性歧义。如:
There are many chairs in the room.
He chairs the weekly meeting.
两个chairs分别是名词和动词。以下是宾夕法尼亚大学定义的词性标签(Penn Treebank POS Tags),NLP数据集中常见,在此进行记录以便查询:

短语结构语法(Phrase Structure Grammar)
短语结构语法是一种重写规则,用于描述给定语言的句法,从而消除语法歧义。这是一种基于成分的语法(constituency-based),每次分解对应的词汇可以有多个(与下面的依赖语法不同)。一般来说,每个句子(Sentence, S)都能被分为主语(名词短语, Noun Phrase, NP)和谓语(动词短语, Verb Phrase, VP)。NP和VP则能被进一步分解更小的NP和VP,或最终分解为不可分解的某种性质的词汇。例子如下:
The children ate the cake.

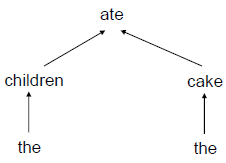
依存语法(Dependency Grammar)
依存语法将句子每个词汇看做是互相依赖的关系,因此每次分解只对应一个词汇。具体分解方式先占个坑,以后再记录。
内容来源于网络如有侵权请私信删除
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


