
一.什么是机器学习
在开始正式的学习之前,可能需要先了解几个概念,机器学习(Machine Learning简称ML),人工智能(Artificial Intelligence简称AI)和深度学习(Deeping Learning简称DL),人工智能顾名思义通过人工的方式实现机器的智能,是最终要达到的目的。据笔者所知,目前人类还没有实现”真正”的人工智能,即机器还没有具有独立思考的能力,目前的AI主要是通过一些技术使机器能够达到人类的要求,并且看上去具有一定的智能。机器学习是达到人工智能的手段,让机器通过学习达到智能,机器学习本质上就是寻找一个函数,给定输入的图片,文字,语音等内容,输出比如图片标签,文字涵义,语音内容等。而深度学习是机器学习的其中一种方法,近五六年以来,随着GPU运算能力的不断提升,深度学习相关的研究几乎占据了机器学习大部分内容。(因为目前ML领域的论文大多使用英语,而且有一部分术语没有中文翻译,为了严谨性之后的文章中会使用一些英文术语)
先把课程链接放在这里 https://www.bilibili.com/video/BV1Wv411h7kN
也可在台大官网查看全部课程相关资料 https://speech.ee.ntu.edu.tw/~hylee/ml/2021-spring.html
二.基本概念
1.机器学习基本概念
机器学习主要有三类任务,分类(Classification),回归(Regression),结构化学习(Structured Learning)
简单定义分类与回归 1、如果机器学习模型的输出是离散值,让机器去学会分类,例如布尔值,我们称之为分类模型。2、而输出连续值的模型,让机器去拟合数据称为回归模型。
1,分类任务的衡量标准可以用准确率 2.回归任务的衡量标准可以用方差
结构化学习:让机器去产生有结构的内容,比如一段文字,一段语音等
机器学习的步骤,1.定义一个函数,函数的解释详见第一段
2.定义损失(以后称之为loss),loss是机器预测的结果和正确结果相差多少
3.寻找最优结果(以后称之为optimization),寻找loss最小的方法
机器学习使用的数据集种类:训练集:训练模型(以后称之为model)使用的数据
验证集:调整模型的超参数(以后称之为hyperparameter)时用到的数据集
测试集:测试模型性能时用到的数据集
超参数:model中人为定义的参数,定义时需要一些人的经验和知识(domain knowledge)
参数(parameter):可在model的训练中学到的参数
2.深度学习的基本概念
深度学习的流程可能比较难以用语言描述,这个是对深度学习和反向传播的讲述比较生动和透彻的视频
神经网络的结构:https://www.bilibili.com/video/BV1bx411M7Zx
梯度下降法(Gradient Descent):https://www.bilibili.com/video/BV1Ux411j7ri
反向传播:https://www.bilibili.com/video/BV16x411V7Qg
分段线性(piecewise linear):任何一段都是线性的分段函数,可以近似拟合任何曲线
独热向量(one-hot vector):向量中只有一个1,剩下都是0
激励函数(activate function):添加在每层网络后面,使网络可以拟合非线性函数,两个ReLU 神经元的线性叠加即可拟合博雷尔可测函数(不知道也不重要),采用ReLU的神经网络,对于拟合解决实际问题中常见的函数来说是绰绰有余了
为什么引入非线性激励函数? 如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。因此我们决定引入非线性函数作为激励函数,这样深层神经网络就有意义了(不再是输入的线性组合)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入。
为什么引入Relu? 第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。 第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失,从而无法完成深层网络的训练。第三,Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
3.其他的一些概念
token的定义:直译做令牌或记号,在句子中是人为定义的用来进行操作的基本单位,在汉语一个token一般是一个character,一个方块字,在英语中可以是一个单词或一个字母
BOS:begin of sentence,句首标识符,一种special token
EOS:end of sentence,句尾标识符,一种special token
SOTA:state of the art,最先进的,一般指新提出的模型超越以往的模型
4.深度学习任务攻略
课件原图:
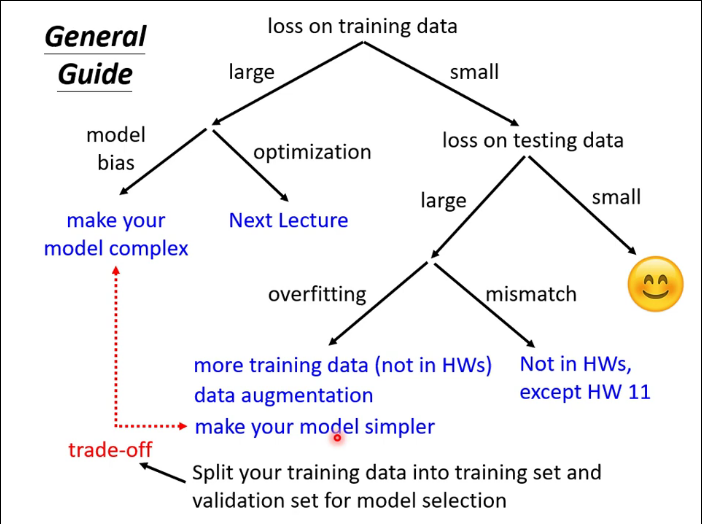
model bias:模型偏差,模型过于简单导致拟合能力太弱
optimazation issue:梯度下降进入critical point(稍后解释)
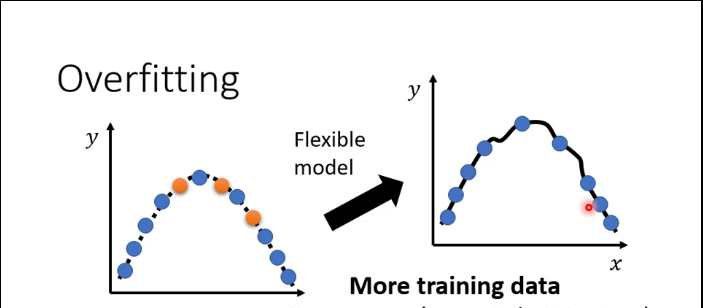
over fitting:过拟合,如图

mismatch:误配,测试集和训练集的数据分布(distribution)不一致,需要用到domain adaptation/transfer learning(后面会解释)
4.类神经网络中的一些概念
critical point:包含local minima(局部最小)和saddle point(鞍点),在loss的超平面中,梯度下降时可能会陷入这样的点从而无法继续优化,可以使用黑塞矩阵来判断error surface某一点附近的地貌。
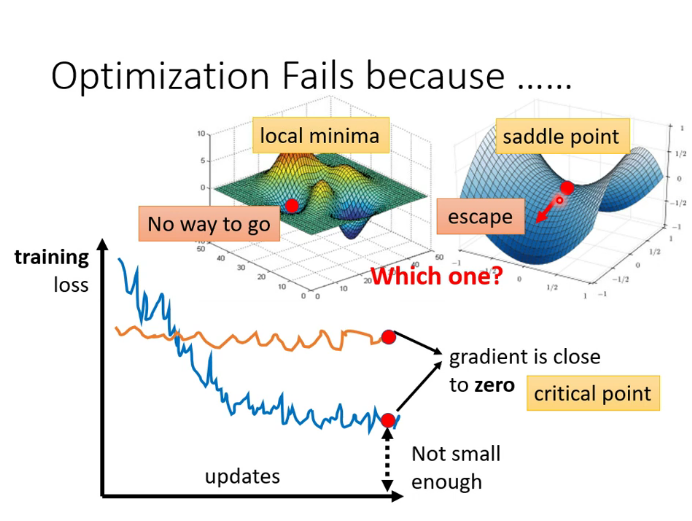
在实际应用中,这样的情况其实不易出现。我们在三维空间中的error surface是一个二维的平面,可以走的方向非常有限。但一般的DL项目中,参数可能几百维甚至上万维,可走的路非常多,所以critical point的情况不易出现。
batch:执行一次梯度下降所用的数据,数据集大小称之为batch size,pytorch读取数据就是以batch读入的
epoch:所有数据集训练一次为一个epoch,执行20个epoch即每个数据都要用来训练20次
iteration:一个epoch中以读取了多少个batch
batch size * iteration = size of data set
批量梯度下降(Batch Gradient Descent,BGD):批量梯度下降法是最原始的形式,它是指在每一次迭代时使用所有样本来进行梯度的更新,即iteration=1。
随机梯度下降(Stochastic Gradient Descent,SGD):随机梯度下降法不同于批量梯度下降,随机梯度下降是每次迭代使用一个样本来对参数进行更新。使得训练速度加快,即batch size=1.
小批量梯度下降(Mini-Batch Gradient Descent, MBGD):小批量梯度下降,是对批量梯度下降以及随机梯度下降的一个折中办法。其思想是:每次迭代使用 batch_size个样本来对参数进行更新。
BGD的并行效果好,一个batch里很多组数据可以做并行的运算,但train的效果不好
SGD的并行效果不好,每个batch只有一组数据,只能一个batch接一个batch的运算,但train的效果好
为什么BGD和SGD训练效果会有这样的差异,说法有很多种,我个人更相信large batch 容易overfitting这个解释。此外,还有说法是BGD更容易被卡在critical point。还有第三种说法如图,large batch更容易陷入sharp minima,这也是一个亟待研究的课题。
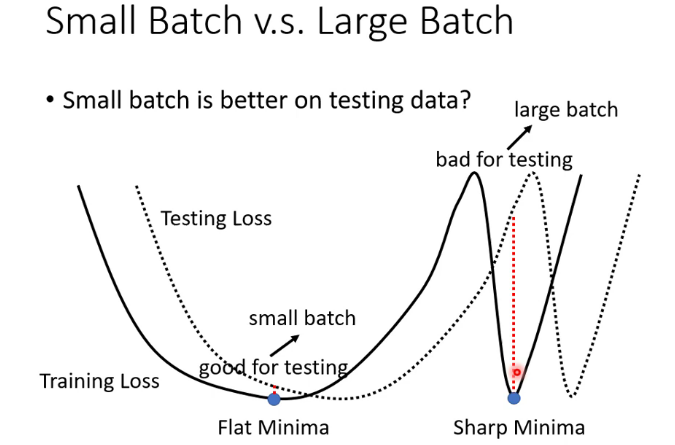
因此,MBGD是一个折衷的方法,也是目前最常用的方法。
动量(Momentum):选定梯度下降的方向时把之前的梯度也考虑进去,这样就更容易“冲过”critical point
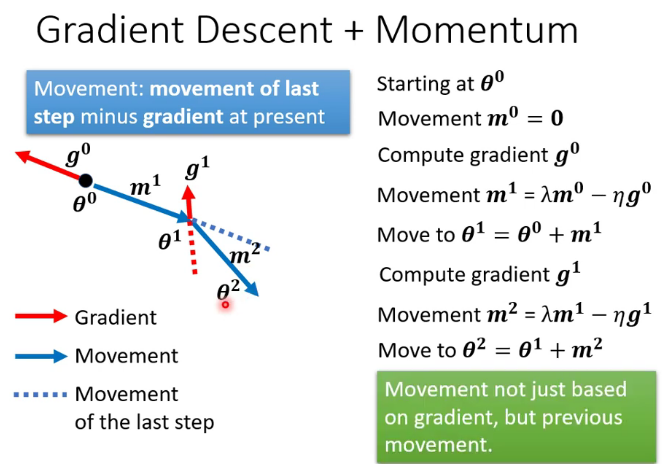
自适应学习率(Adaptive learning rate):固定的学习率会导致梯度大的时候步长过大,梯度小的时候步长太小甚至出现在有限的运算中不收敛的状况,自适应学习率的算法比如RMSprop可以解决这个问题。
Adam算法就是RMSprop+Momentum
softmax:
假设我们有一个数组,V,Vi表示V中的第i个元素,那么这个元素的Softmax值就是
也就是说,是该元素的指数,与所有元素指数和的比值。这个函数可以把一个数组所有的数都按照一定比例映射到[0,1]
loss函数的种类:
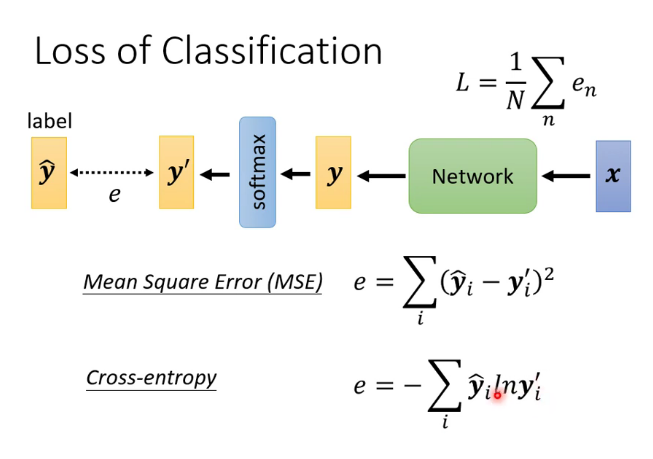
在某些情况下交叉熵(cross-entropy)具有与mse相同的global minima,但是error surface更加平滑,常使用在分类任务里。
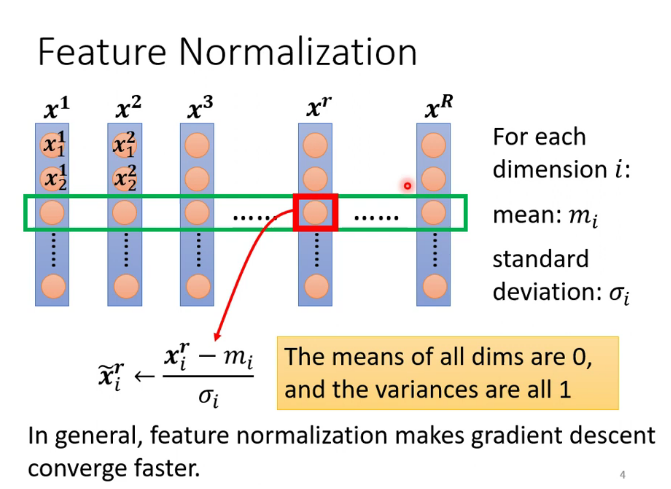
批次标准化(batch normalization):使error surface更加平滑的一种方法,让不同维度的数据 数值范围更加接近。(softmax是纵向,batch normalization是横向)
feature normalization是对数据集中所有数据进行操作,但GPU的memory有限,所以只对一个batch的数据进行操作,就是batch normalization

在testing时,数据往往不是以batch的形式输入进来的,那如何计算均值和方差呢?pytorch中是这样实现的,把training时的均值和方差加权计算储存起来,testing时就用这个储存的数。
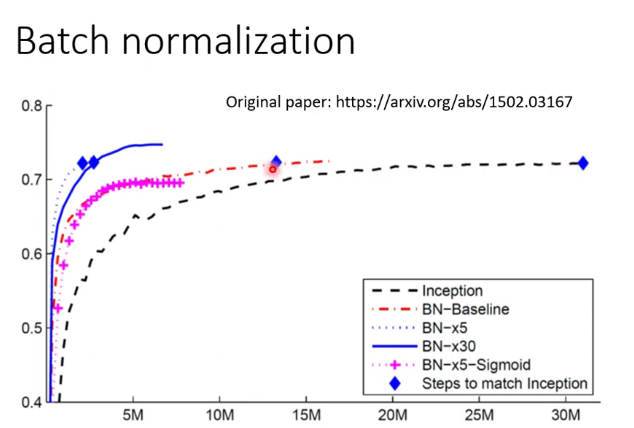
上图可知,经过batch normalization处理的算法有更快的收敛速度,但只要时间足够长,是否batch normalization能达到几乎一样的accuracy
三.卷积神经网络(Convolutional Neural Networks, 简称CNN)
1.计算机是如何处理图片的
把图片变为向量
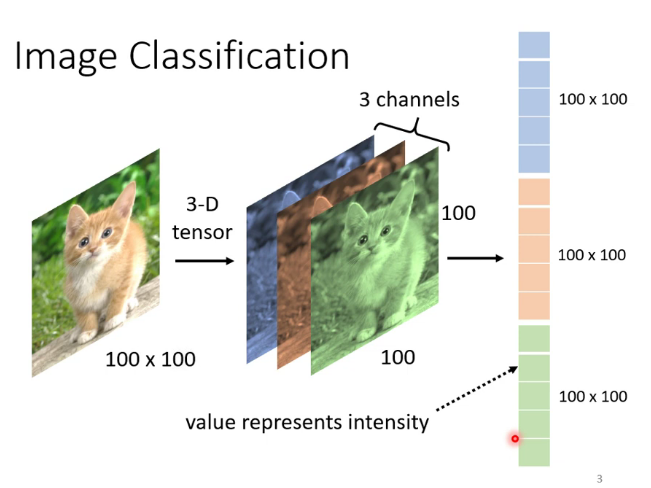
为什么需要CNN:因为对于图片来说,不是每一个像素(pixel)都与其他像素联系起来都能产生信息,比如猫的嘴附近的一些像素可以构成猫脸的一部分,但猫的嘴和后面的树没有任何关系。而且对于图像这样大的向量,做Fully connected network需要耗费大量计算资源。因此就产生了CNN。
2.CNN是如何做的
每个neural只接收上一层部分neural的输出
先定义几个符号:
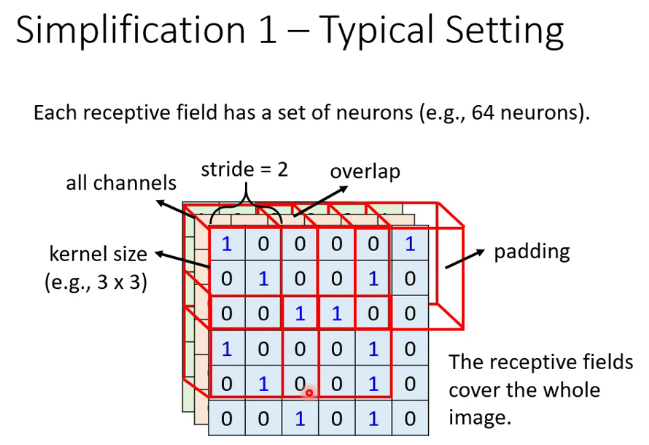
深度(depth) : 顾名思义,它控制输出单元的深度,也就是filter的个数,连接同一块区域的神经元个数。又名:depth column
步幅(stride):它控制在同一深度的相邻两个隐含单元,与他们相连接的输入区域的距离。如果步幅很小(比如 stride = 1)的话,相邻隐含单元的输入区域的重叠部分会很多; 步幅很大则重叠区域变少。
补零(zero-padding) : 我们可以通过在输入单元周围补零来改变输入单元整体大小,从而控制输出单元的空间大小。
感受野(receptive field):一个neural的所摄的范围
这是一个一维的例子,左边模型输入单元有5个,左右边界各补了一个零,步幅是1,感受野是3,因为每个输出隐藏单元连接3个输入单元,右边那个模型是把步幅变为2,其余不变。
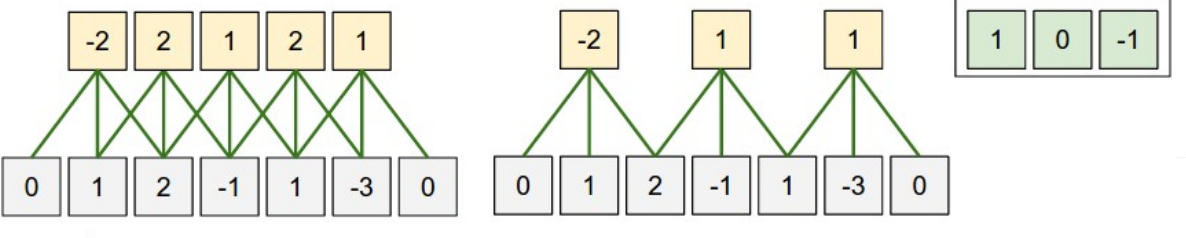
在二维中就是这样
池化(pooling):用于压缩向量大小。在卷积层进行特征提取后,输出的特征图会被传递至池化层进行特征选择和信息过滤。池化层包含预设定的池化函数,其功能是将特征图中单个点的结果替换为其相邻区域的特征图统计量。池化层选取池化区域与卷积核扫描特征图步骤相同,由池化大小、步长和填充控制。
随着当前GPU计算能力的提升,很多CNN现在都不使用池化层。比如围棋AI阿尔法狗就没有pooling layer。
常用的pooling方法比如max pooling,每个范围(比如2*2)保留一个最大值,这也是subsampling(子采样)的一种
四.自注意力机制(Self-attention)
1.两种任务
关于seq2seq
机器翻译是一种典型的sequence to sequence的任务,即输入是一个队列,输出也是一个队列,可以简称seq2seq,那么一个句子是如何用数字来表示的呢?
关于词的表示这里介绍了两种方法
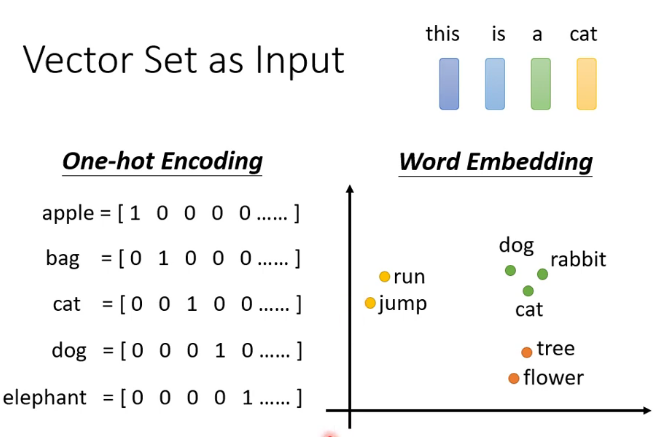
其中one -hot encoding不包含任何的语义咨询,比如猫和狗的关系应该比猫和汽车的关系更近。而且这种表示方法需要的维度很高,比如有八万个汉字,表示其中就需要一个八万维的向量。但是这种方法容易理解,也比较简单。
word embedding 一般可以用auto-coder来生成(之后介绍)
关于Sequence Labeling(序列标注)
词性标注就是一种sequence labeling任务,即输入是一个队列,输出是一串标签,给定一个句子,为句子中的每个词标注词性,这就涉及到了为什么需要Self-attention:举一个简单的例子I saw a saw.翻译成中文是“我看见了一个锯子”,那么如何让机器分辨第一个saw和第二个saw的词性差别呢,这是就需要联系上下文,使用自注意力机制
2.self-attention
自注意力机制有很多种,常见的比如有dot-product attention和additive attention,接下来介绍最常见的一种,也是用在transformer里的方法,dot-product attention(点积型注意力机制)
**节选自某乎的解释**,动画视频详见 https://www.bilibili.com/video/BV1Wv411h7kN?p=23
设一个句子的长度为S,单词embedding空间的维度为D,那么一个句子就会被编码为一个大小为 的矩阵。使用三个大小为
的权重矩阵
与之相乘,会得到为三个大小为
的编码矩阵
。
代表query,
代表key,
代表value,自注意力机制就围绕着这三个矩阵展开的,具体公式如下:
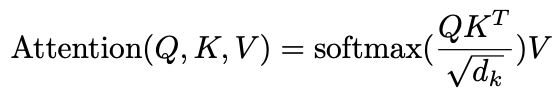
其中 正是注意力中最为重要的交互步骤:
代表着需要编码的词的信息,
代表着句子中其它词的信息,相乘后得到句子中其它词的权重值;
代表着每个位置单词蕴含的语义信息,在被加权求和后作为待编码词的编码。我们会发现,此时的注意力机制将输入矩阵编码成大小为
的矩阵。所谓多头注意力机制,就是将n个这样得到的编码进行拼接,得到大小为
(其中
的个数为
)的矩阵。在原文中,
的结果刚好等于
,两者不相等也没有关系,因为其后还有一个
矩阵,用于将编码从
维转化为
维。
3.基于self-attention的改进
(1)以上介绍的编码方式里没有位置的信息,如果需要位置信息可以使用positional encoding的方法,在词向量中加入positional vector,这个是handcrafted的。
(2)当输入的向量过长时,attention matrix可能会过大导致难以计算,这是可以用truncated self-attention,让每个词只注意它周围的几个词,而不是整个输入的篇章。
(3)muti-head self-attention多头自注意力模型,有多个
4.其他网络和self-attention的联系
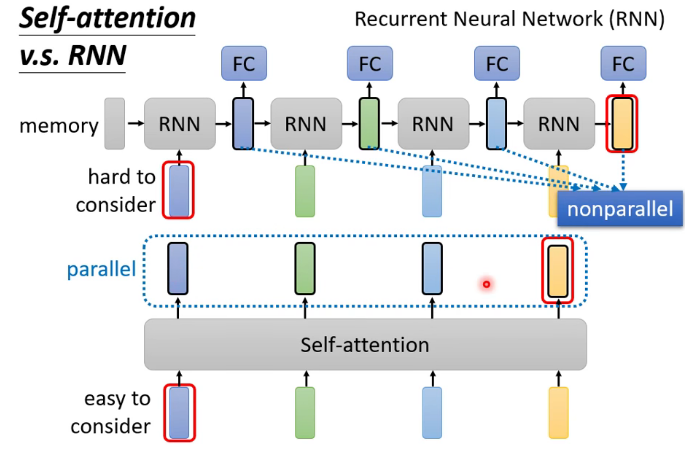
CNN实际上是self-attention的特例

RNN(循环神经网络)可以被self-attention所代替
五.transformer
1. 模型结构
模型结构如下图:
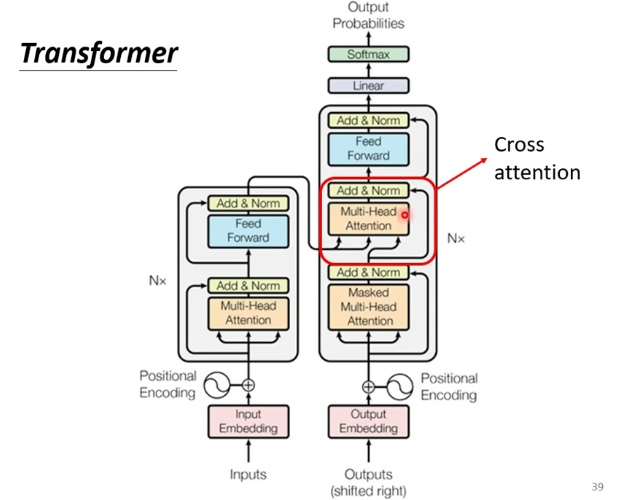
和大多数seq2seq模型一样,transformer的结构也是由encoder和decoder组成。
2.Encoder
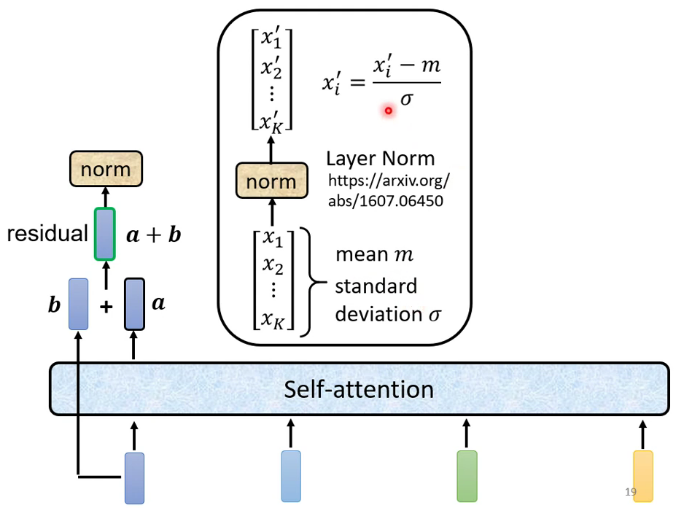
最简单的encoder模型,由许多block组成,每个block是一个self-attention的结构

残差连接和标准化:残差连接是把输入加到输出上。标准化类似于softmax,也是针对一个向量的计算
3.Decoder
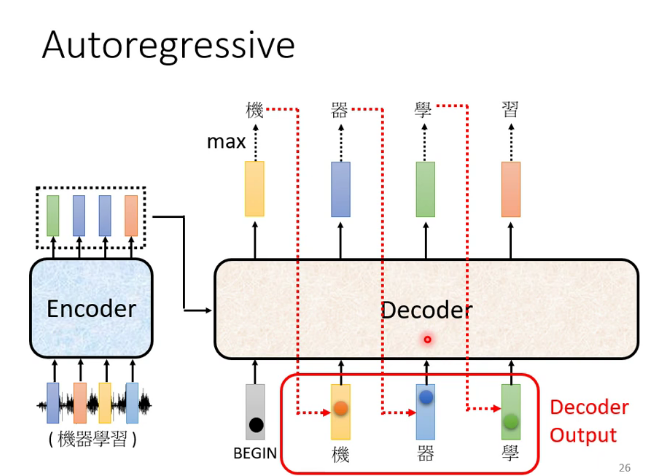
前面的输出当作后面的输入,进行多少个循环由机器自己决定
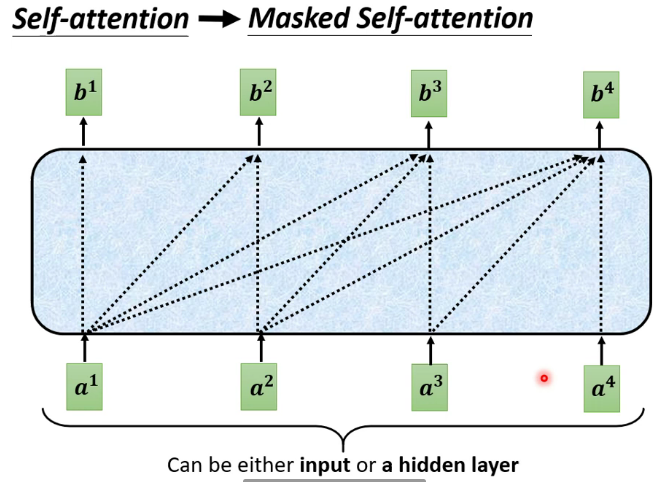
其中的masked self-attention:每个词只能注意到出现在它之前的词
Error propagation问题:前面的错误输出导致后面的输入也是错的,一直错下去,一步错,步步错
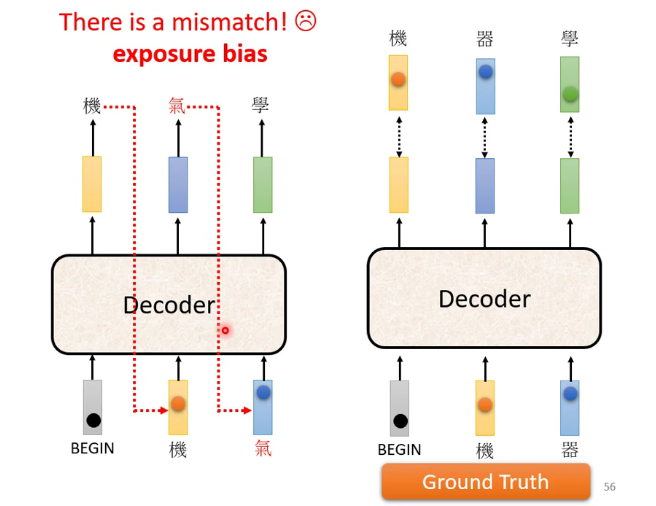
解决的办法可以是训练时就给机器看一些错误的资料
自回归(Autoregression简称AR)和非自回归(Non-Autoregression简称NAR)的Decoder:(这里的T是translation的意思)
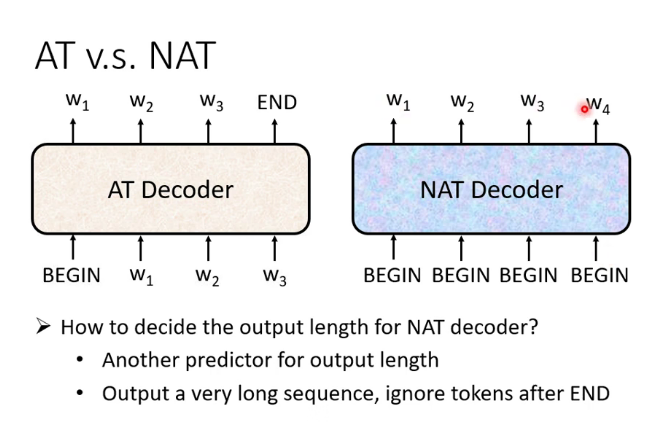
Decoder的训练:
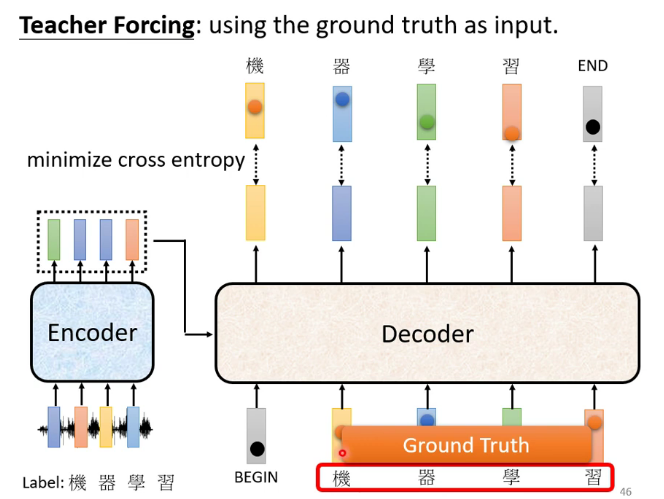
六.生成式对抗网络(Generative Adversarial Networks 简称GAN)
1.为什么需要GAN
(1)有些网络需要一定的随机性,比如去让机器学着去玩电子游戏,以人类玩这个电子游戏的操作作为训练集,而人类在遇到相同的环境时可能会进行不同的决策,而这些决策都是对的,比如向左转或者向右转,把这些操作都给机器学的时候机器可能会作出一些奇怪的决策,因此这类的机器学习任务需要一定的随机性,随机向左转或向右转。
(2)有些网络需要有一定的创新能力,创新也是随机的
2.GAN的原理
首先大家都知道 GAN 有两个网络,一个是 generator,一个是 discriminator,从二人零和博弈中受启发,通过两个网络互相对抗来达到最好的生成效果。流程如下:
主要流程类似上面这个图。首先,有一个一代的 generator,它能生成一些很差的图片,然后有一个一代的 discriminator,它能准确的把生成的图片,和真实的图片分类,简而言之,这个 discriminator 就是一个二分类器,对生成的图片输出 0,对真实的图片输出 1。
接着,开始训练出二代的 generator,它能生成稍好一点的图片,能够让一代的 discriminator 认为这些生成的图片是真实的图片。然后会训练出一个二代的 discriminator,它能准确的识别出真实的图片,和二代 generator 生成的图片。以此类推,会有三代,四代。。。n 代的 generator 和 discriminator,最后 discriminator 无法分辨生成的图片和真实图片,这个网络就拟合了。
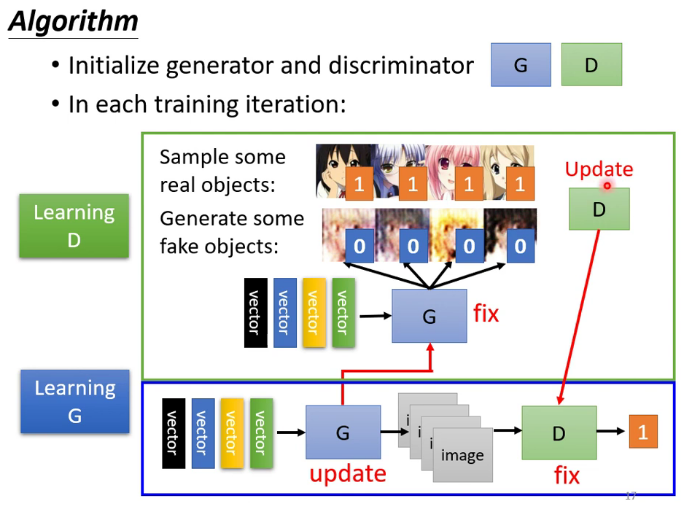
需要注意的是generator也需要输入的向量,只不过向量是随机的,以下是一段generator的代码

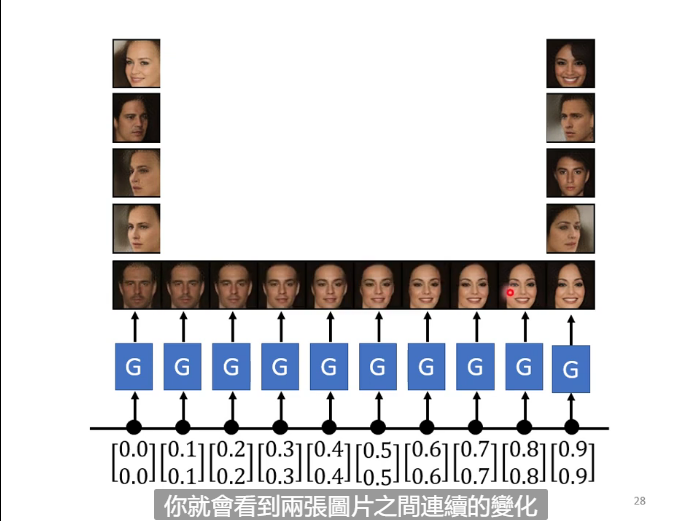
GAN也可以用来生成一段渐变的图像
GAN的目标

3.GAN里面的问题
因为GAN实际上是一个很难train的模型,所以经常会出现各种问题。比如:


4.cycle GAN
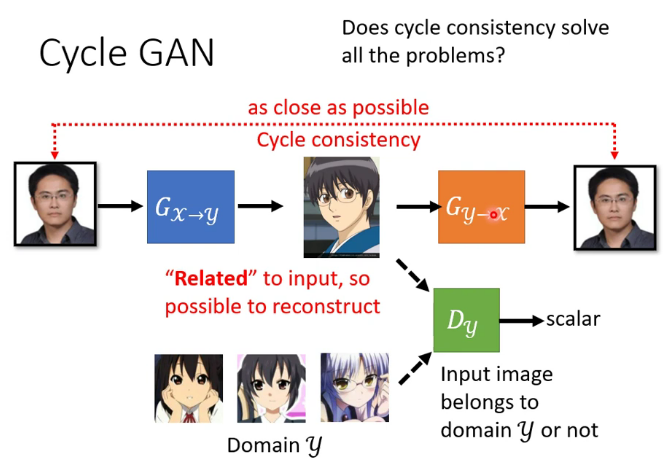
但cycle GAN会不会学到一些奇怪的准换,比如蓝色的G把眼镜转换为一颗痣,橙色的G再把痣转换为眼镜,但这样的情况不太容易出现,因为G这个network很“懒惰”,不太容易出现相似度差别比较大的结果,甚至有时不加那个橙色的G也能产生很好的结果。
七.BERT
1.监督学习,无监督,半监督,自监督
(1)首先比较监督和无监督学习,其最主要的区别在于模型在训练时是否需要人工标注的标签信息。
监督学习利用大量的标注数据来训练模型,模型的预测和数据的真实标签产生损失后进行反向传播,通过不断的学习,最终可以获得识别新样本的能力。
无监督学习不依赖任何标签值,通过对数据内在特征的挖掘,找到样本间的关系,比如聚类相关的任务。
(2)半监督学习在训练阶段结合了大量未标记的数据和少量标签数据。与使用所有标签数据的模型相比,使用训练集的训练模型在训练时可以更为准确,而且训练成本更低。
(3)和其他无监督学习不同,自监督学习主要是利用辅助任务(pretext)从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。换句话说自监督学习的监督信息不是人工标注的,而是算法在大规模无监督数据中自动构造监督信息,来进行监督学习或训练。自监督学习比如训练机器做填空等。
2.BERT和自监督学习
BERT在pretrain阶段使用了自监督方法
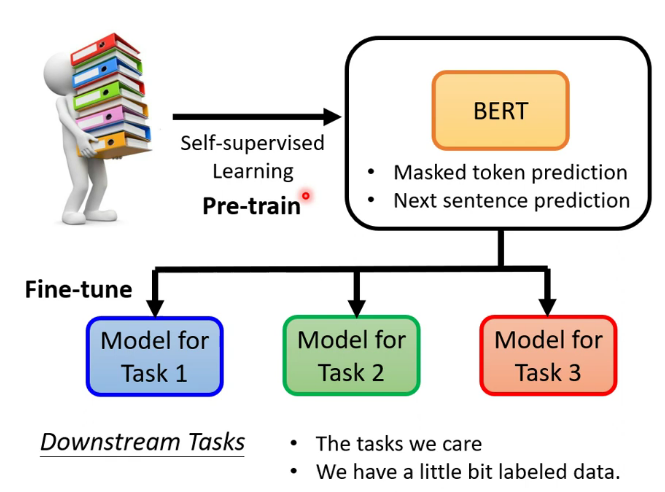

Bert的pretrain通常是以transformer的encoder为架构,最终的fine-tune可以较快降低loss的原因可能是pretrain的参数确实适合下游任务,也可能是pretrain的参数就适合于这种大型训练
评判pretrain模型性能的方法:在语言处理上的公认标准:GLUE,包括七个待fine-tune的任务,用这些任务上的表现来评判

在其它类型的任务上目前还没有公认标准
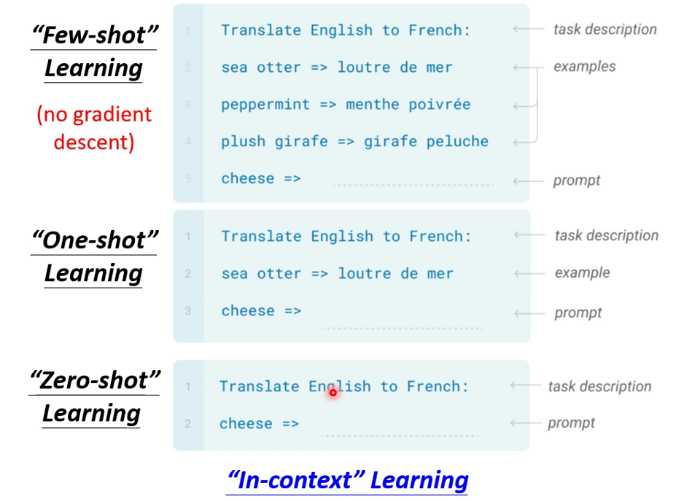
3.Few-shot Learning
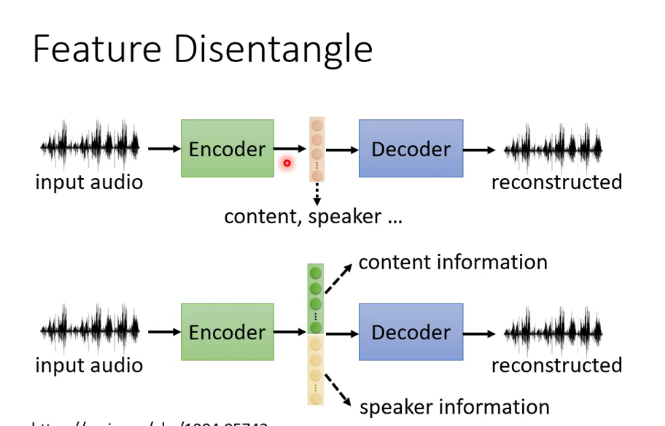
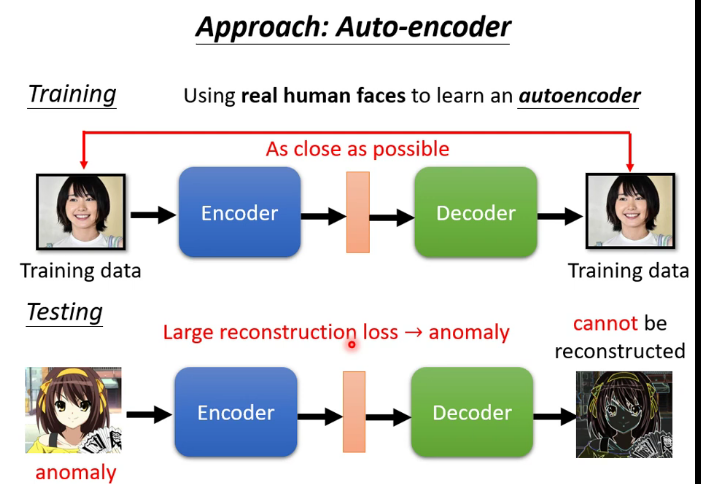
八.自编码器(Auto-encoder)
1.什么是自编码器
类似于cycle GAN,可用于dimension reduction

Discrete Representation
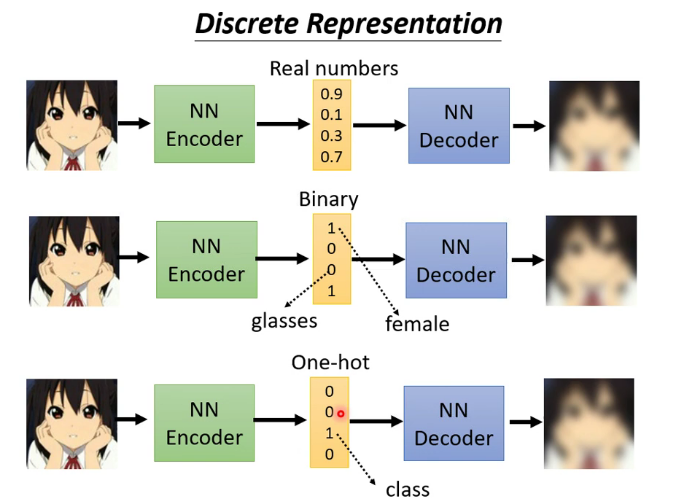
其中最后一个表示方法可以达到无监督聚类的效果
2.自编码器应用
(1)decoder部分可以被看作一个generator
(2)异常检测:根据能否重构来判断这个输入的数据是不是训练时见过的类型
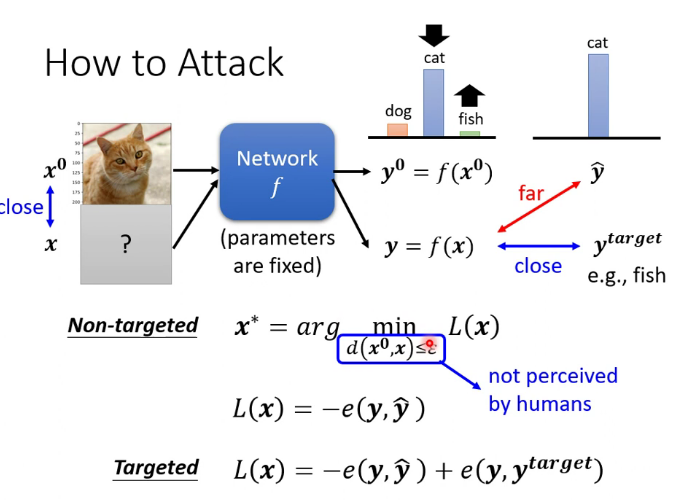
九.Adversarial Attack
1.来自人类的恶意攻击
通过在图片中加一点杂讯,让图片产生误判,最佳效果是Non-perceivable,即人类无法感知到,但机器可以

2.最简单的攻击方法:FGSM
只进行一次调整

3.黑箱攻击和白箱攻击
白箱攻击:已知网络的内部结构进行攻击
黑箱攻击:未知网络的内部结构进行攻击
已知训练集时可以使用代理网络攻击:

未知训练集时,可以向目标网络输入大量数据,再把输出和输入构成一个集合训练代理网络
4.其他有趣的应用
寄生:
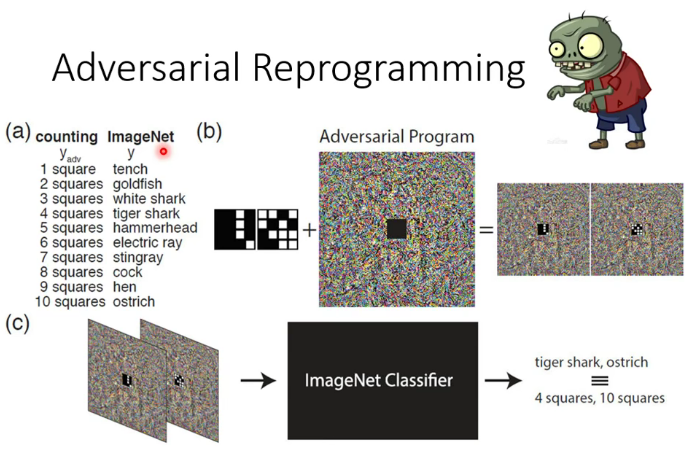
后门:

5.防御攻击
(1)被动防御:比如使图片模糊化(但如果在攻击中把模糊化考虑为network中的一层,就会失去作用)
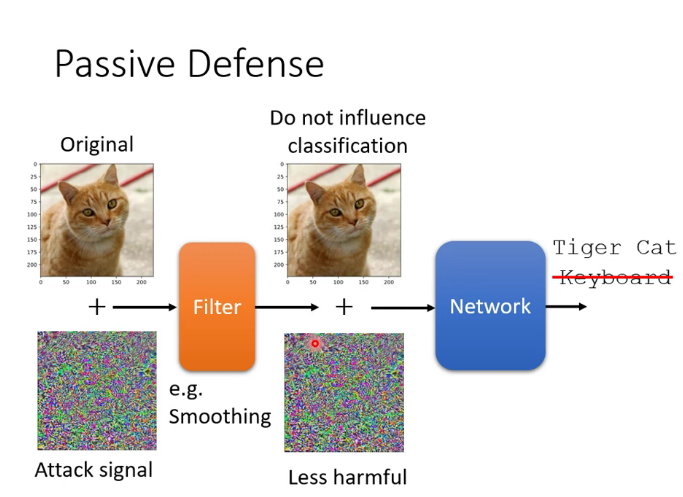
在网络中加入随机的一层(不让别人知道我出什么招的最好办法就是我自己都不知道我接下来要出什么招)
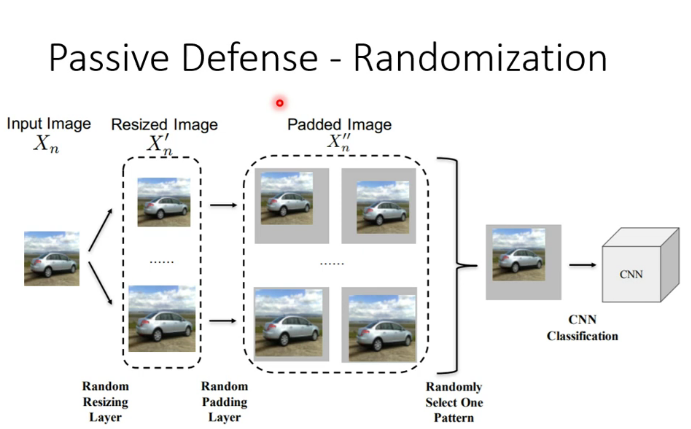
(2)主动防御:在训练阶段加入攻击资料

十.可解释性
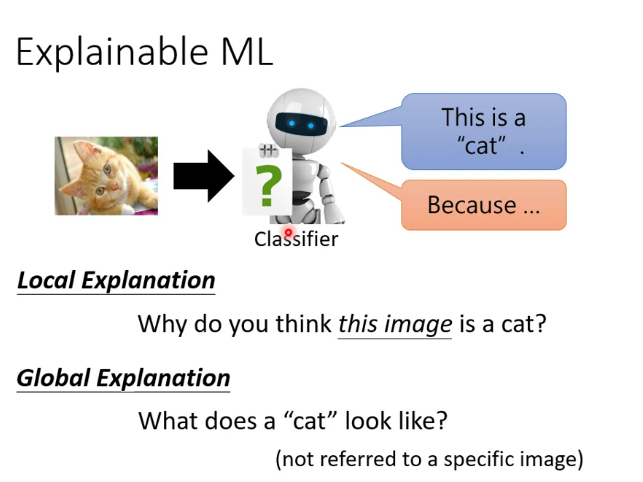
1.为什么需要可解释性
当我们在DL中调整了一大堆hyperparameter,我们可能需要理解机器在干什么,机器是否真正的理解了任务,如果模型具备了可解释性,之后在当DL犯错时,我们可能会更有效地找到它为什么犯错,错在什么地方。但可解释性只是作为DL模型众多指标中的一个,况且可解释性也没有一个公认的量化评判标准,如果仅仅因为可解释性就抛弃一个表现良好的模型,无异于削足适履,因噎废食。
2.可解释性的分类
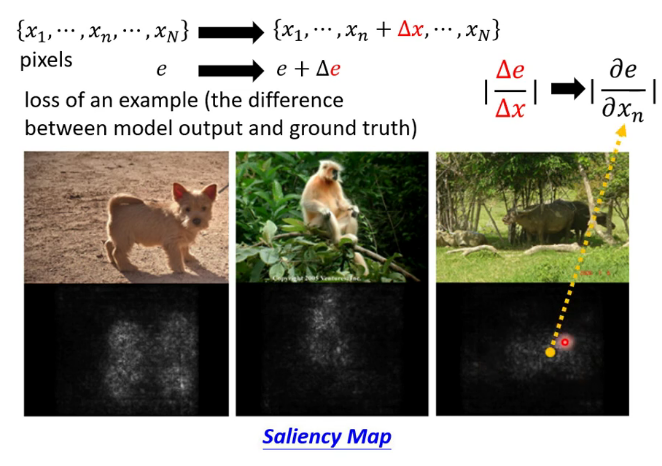
3.解释模型的技术
(1)制作显著性图

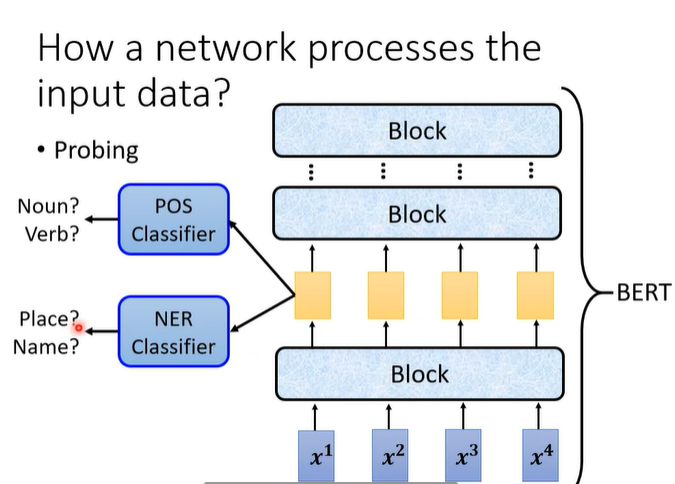
(2)probing
(3)一种global explaination技术
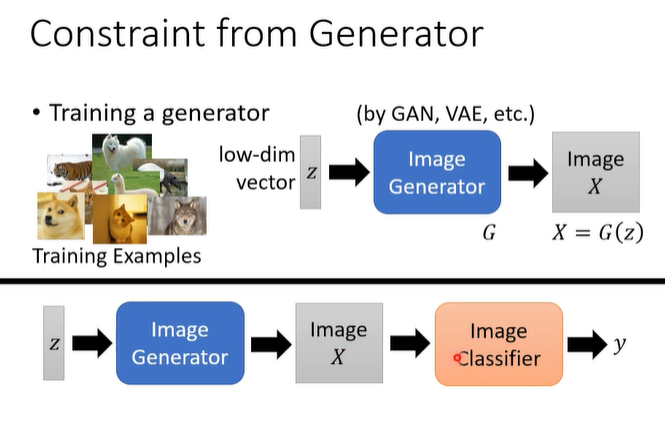
十一.领域自适应(Domain adaption)
1.概念
Domain shift:训练集和测试集有不同的分布,类似于前面的mismatch
Domain adaption就是解决Domain shift的问题
2.两种最简单的情况
(1)待适应领域的数据集有少量labeled data:直接用这些数据做fine-tune
(2)有大量无标注数据:
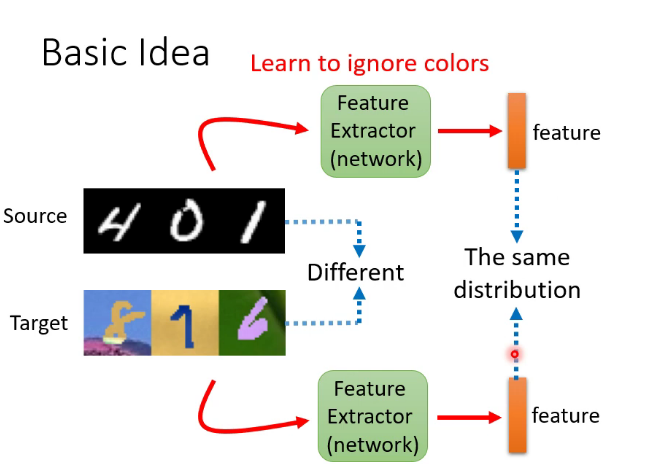

特征提取器实质就是network的前几层,具体是几层可以自己决定,也是一个hyperparameter,结果是尽量让上图红框处来自不同数据集的特征分布接近
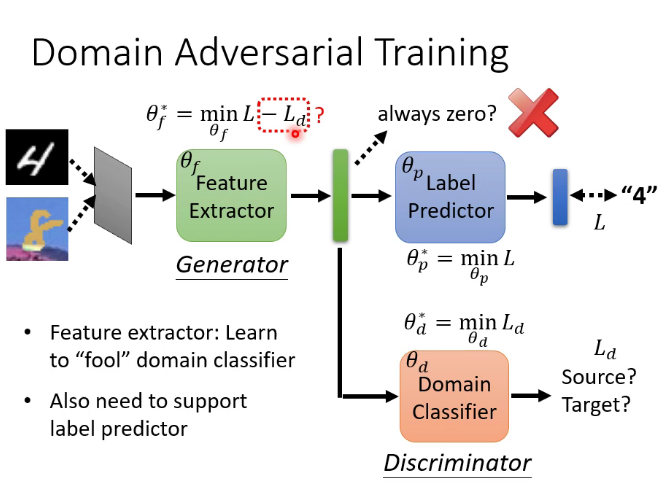
十二.强化学习(Reinforcement Learning简称RL)
RL既不属于监督学习,也不是无监督学习。RL实际上是一个内容庞大的主题,这里只做简单介绍,之后有时间再专门学习然后更新这一块的知识。
RL的训练过程属于马尔可夫决策过程(Markov Decision Processes,MDPs)简单说就是一个智能体(Agent)采取行动(Action)从而改变自己的状态(State)获得奖励(Reward)与环境(Environment)发生交互的循环过程。MDP 的策略完全取决于当前状态(Only present matters),这也是它马尔可夫性质的体现。
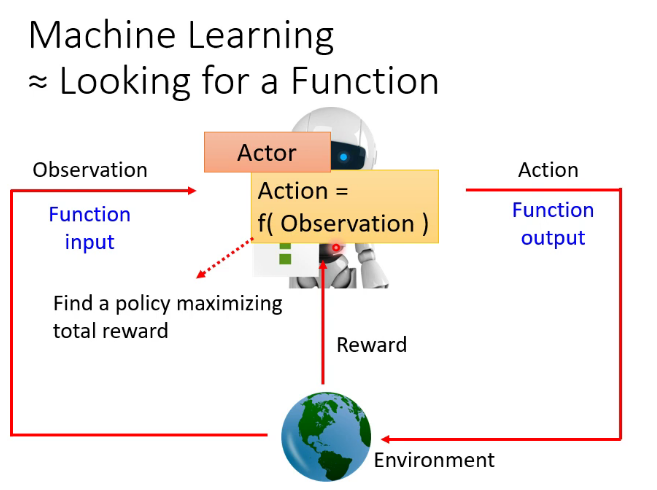
在不同的状态(State)采取的动作 Action 也就是我们所说的策略 Policy 。常用符号 来表示策略。
我们的目的是让reward达到最大,常用的方法是策略梯度下降,详见原课程 https://www.bilibili.com/video/BV1Wv411h7kN?p=73
十三.机器终身学习
1.简述
让已经学会某些任务的机器模型去学习新的任务
终身学习的upper bound:
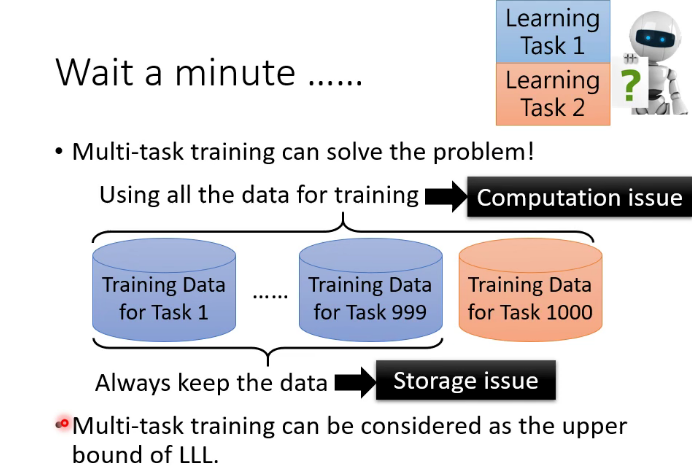
2.灾难性遗忘
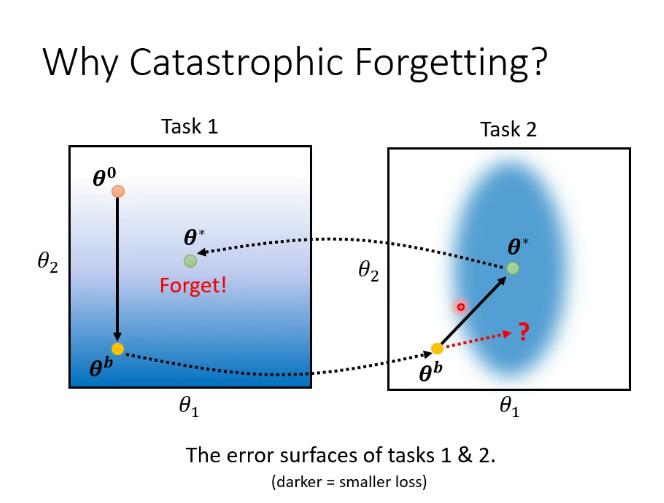
解决方案:
(1)Selective Synaptic Plasticity(可选择的突触可塑性):意思是训练完一个任务后,模型中的一部分链接参数不能够再动了,以后的训练只能选择修改另外一部分参数。这部分研究是发展的最为完整的,因此我们也主要学习这种做法

(2)Additional Nerual Resource Allocation(额外的神经资源分配):
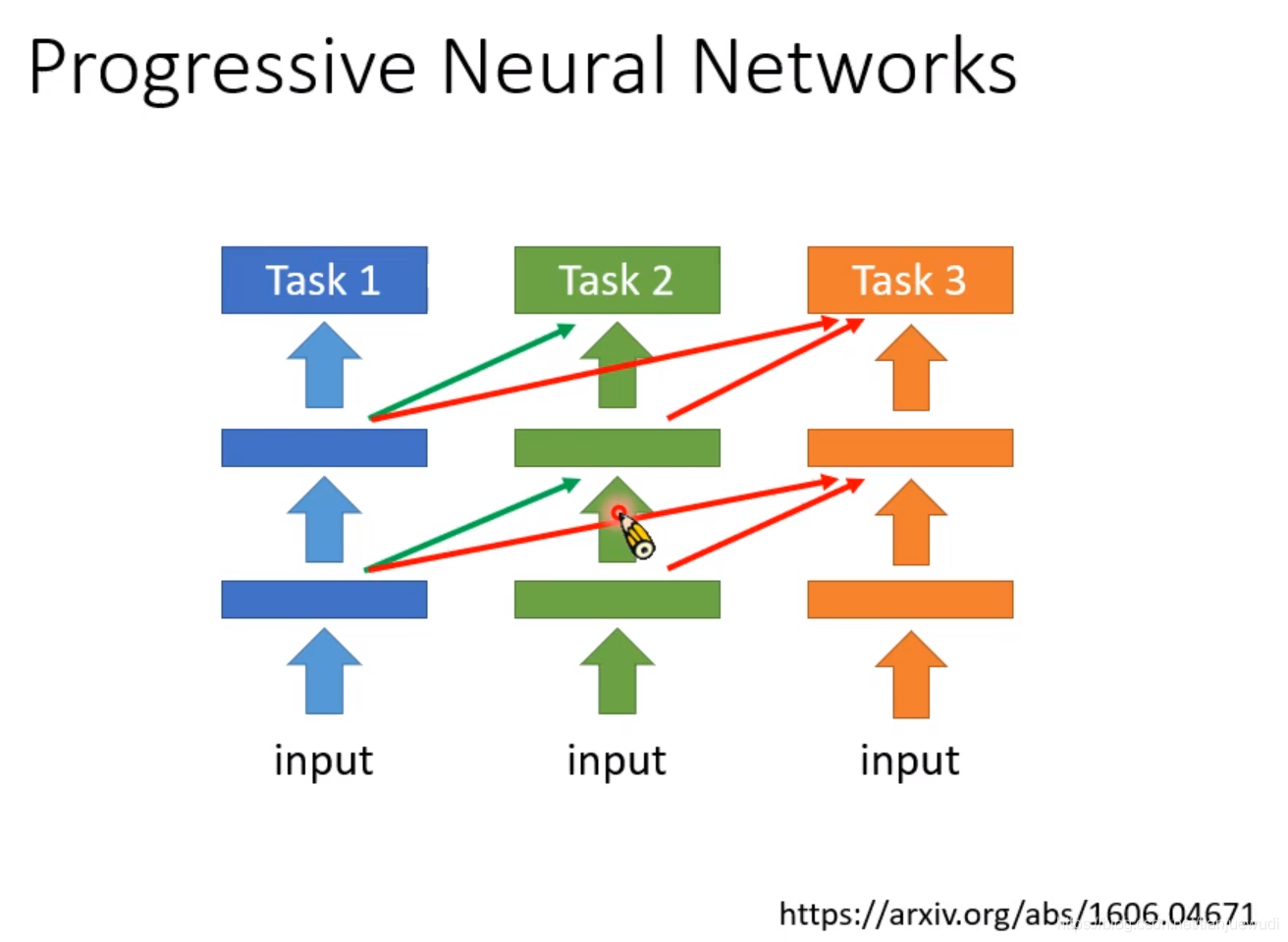
1.Progressive Neural Networks:这是最早的做法,当任务一训练完成之后,我们就不要再动里面的参数了,我们可以再新开一个模型,这个模型使用任务一隐藏层中的输出作为输入,然后再训练自己的参数。任务三亦然。这个方法的缺点是模型随着训练任务数量的增多而增大,最后可能难以保存。但在任务量没有太多的时候,这个也是可以派上用场的。
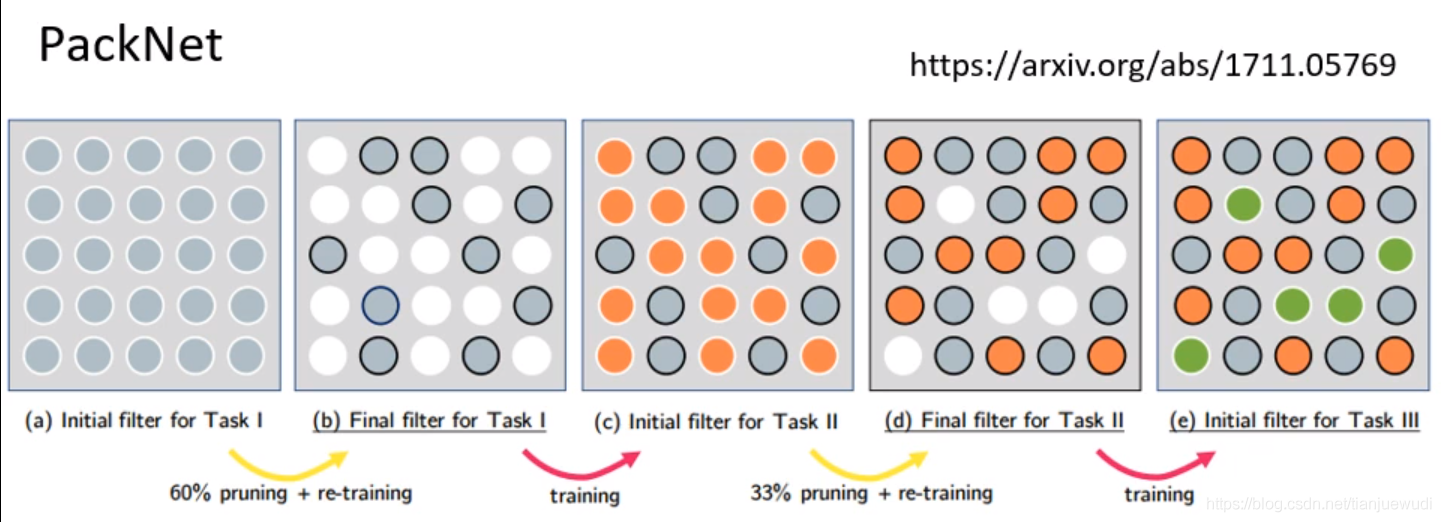
2.PackNet:这种做法是和Progressive Neural Networks相反,首先就建立一个比较大的Network,每次训练任务只使用一小部分的参数
3.Compacting,Picking,and Growing(CPG):这种做法是上两种的结合。生成一个比较大的网络但是我们一边只使用部分参数,一边新增新的网络,确保参数不会用完。
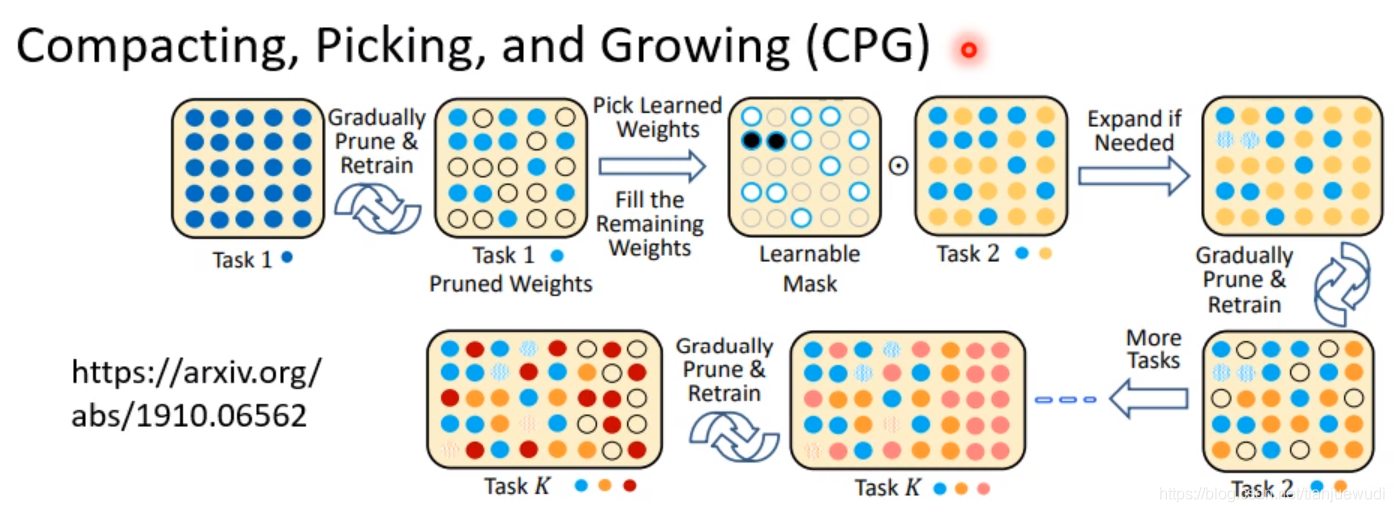
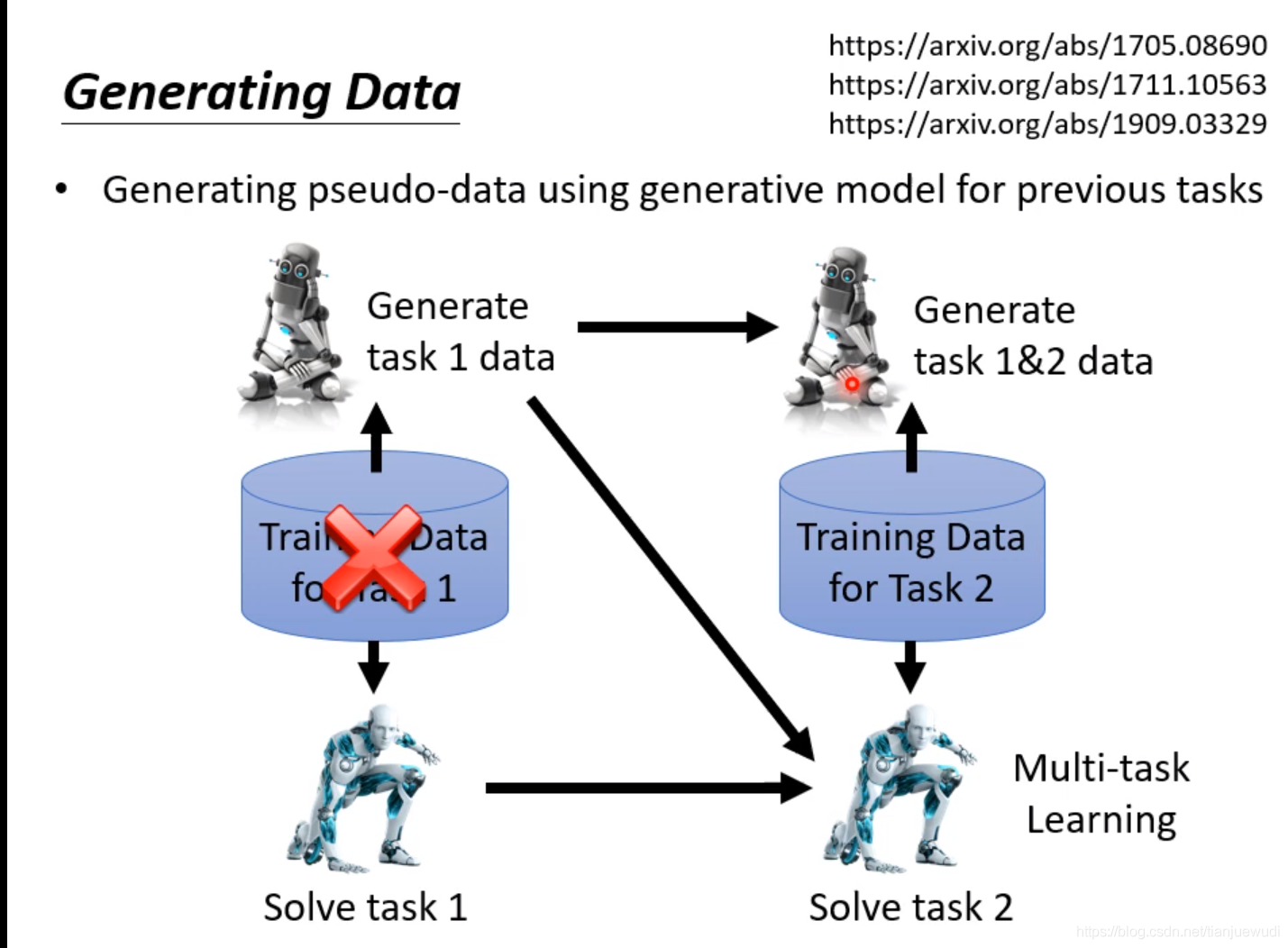
(3)Generating Data:这种做法是直接训练一个Generator,这个Generator可以直接产生过去任务的资料,因此我们就不用保存过去的资料,直接用这个Generator生成过去的资料和现在任务的资料混合进行训练,以达到同时学习所有数据的效果。这种做法是非常有效的,经过实验证明,往往可以达到跟Multi-Task Learning差不多的结果。
十四.神经网络压缩
因为有时候我们需要让神经网络运行在资源有限的设备上,因此需要神经网络压缩
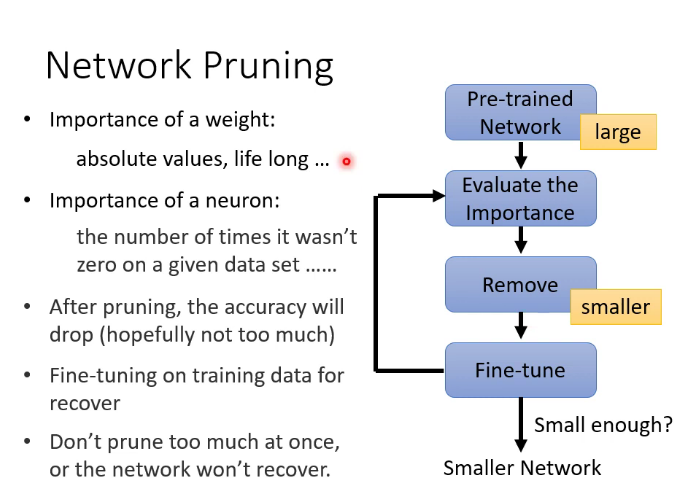
1.剪掉什么
剪掉权重边,神经网络会变成irregular,无法在pytorch里直接使用,因为参数不再是矩阵,也不能用GPU加速,因此不常用。常常直接剪掉神经元
2.为什么不直接训练一个小的network
大乐透假说:大的network有更多机会随机出适合任务的模型参数
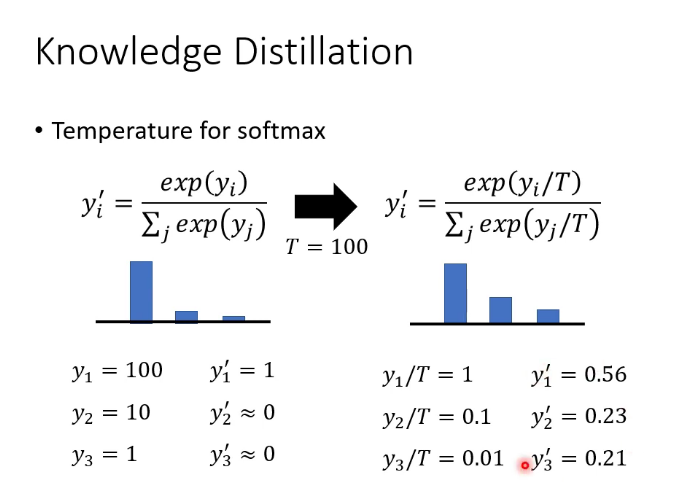
3.知识蒸馏(暗知识提取)
训练一个teacher network,让student network学习teacher的输出,也可以训练很多teacher求平均

4.Parameter Quantization:
降低参数精度,把参数取为低精度近似值
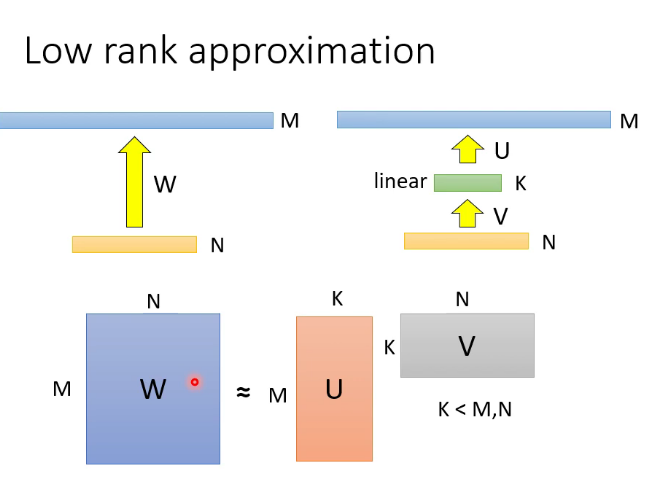
5.重新设计架构:
比如CNN,可以是使用低秩近似
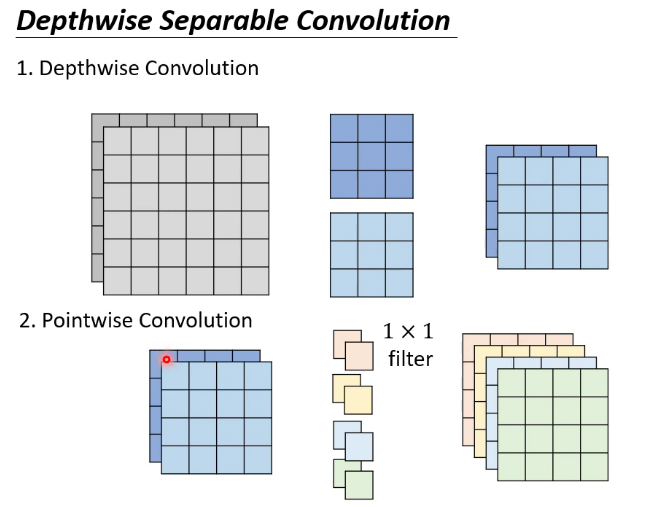
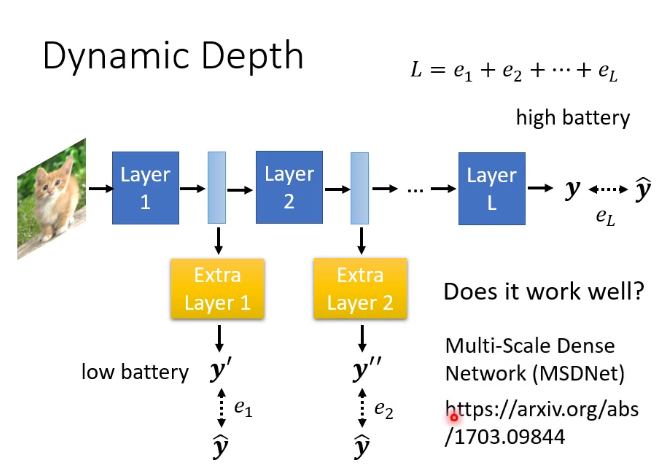
6.动态调整运算资源
动态高度和动态宽度

十五.元学习(Meta Learning)
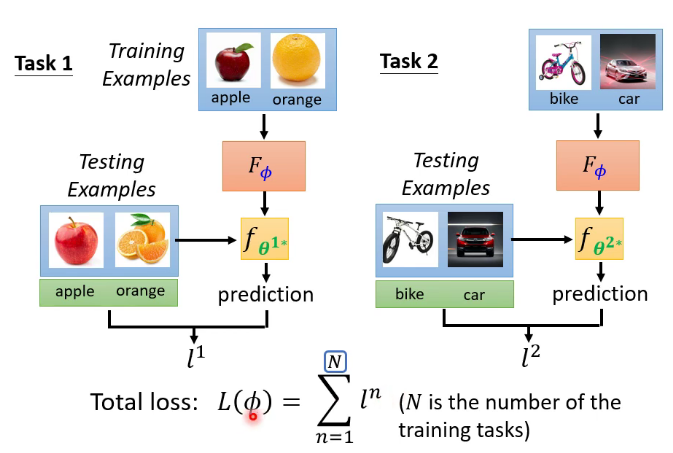
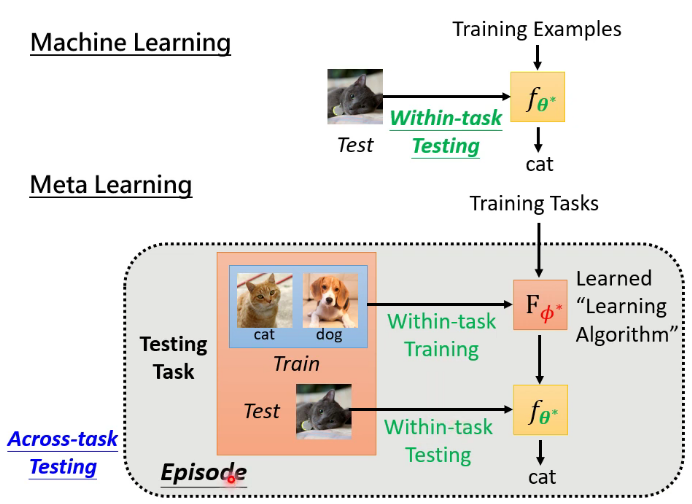
meta learning实质就是learn to learn,比如下图就是让机器去学会一个能力,这个能力就是可以学会所有的二分类任务,即学会学习的能力。为了达成这个目标需要调整这个模型的参数,如果有了这个模型,之后的二分类任务就不用再调参数,“一劳永逸”,( 下图的每一个epoch数据集相同,每个episode数据集可能不同)当前的算法比如MAML。

十六.结语
李宏毅机器学习这门课只是对机器学习的热门领域做了一个笼统的介绍,它的内容很全面很先进但又不是很细致。我的文章更是对这门课的一个简要概括,这个角度看这篇文章是对机器学习概括的概括(meta概括 ╮( ̄▽  ̄)╭ ),深度学习作为计算机学科一个发展时间并不长分支领域,有很多问题尚待解决。希望未来能更加努力地学习,与君共勉!
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


