
踩坑过程
服务器部署了一个flask-apscheduler的定时任务项目,每天的几个时间点会自动推送消息或者跑任务。但经过一段时间后,发现有几个任务莫名其妙的没有运行,其他任务又可以正常运行。排查下来也不是代码问题,因为其他任务可以跑,就一两个任务不行,反复排查问题无果。后面在网上找原因,提示说可以在flask-apscheduler项目中增加log来排查,我在项目入口监听了log,果不其然,发现了一些问题
LOG记录
2021-01-23 06:00:00 base.py[line:952] WARNING Error getting due jobs from job store 'default': (pymysql.err.OperationalError) (2006, "MySQL server has gone away (BrokenPipeError(32, 'Broken pipe'))"). [SQL: SELECT apscheduler_jobs.id, apscheduler_jobs.job_state FROM apscheduler_jobs WHERE apscheduler_jobs.next_run_time <= %(next_run_time_1)s ORDER BY apscheduler_jobs.next_run_time] [parameters: {'next_run_time_1': 1611352800.002729}] (Background on this error at: http://sqlalche.me/e/13/e3q8) 2021-01-23 06:00:10 base.py[line:120] WARNING Run time of job "job_cordcloud_sign_in (trigger: cron[month='*', day='*', day_of_week='*', hour='6', minute='0', second='0'], next run at: 2021-01-23 06:00:00 CST)" was missed by 0:00:10.012178
- 以上是截取的部分log记录
问题分析
从log中可以看到,当执行job名为job_cordcloud_sign_in的任务时,报了一个数据库错误。问题就出在这,我这个任务是需要去查库,然后再走job逻辑的,查库的时候报错了,导致后面的代码没有执行。根据这个错误,网上查解决方案就简单了
最终原因
主要是我这个程序里的涉及到数据库操作的任务之间运行间隔时间超过了8小时,而数据库默认8小时不从数据库取数据则断开连接,所以会抛出这个错误
解决方案
-
方案一:
网上说可以优化代码,增加重连场景,但我没有采用这种办法,大家可以去尝试下
-
方案二:
我采用的是直接修改数据库的interactive_timeout配置,默认是28800秒,即8小时
show global variables like '%timeout';
修改方法
修改my.cnf的配置,如下图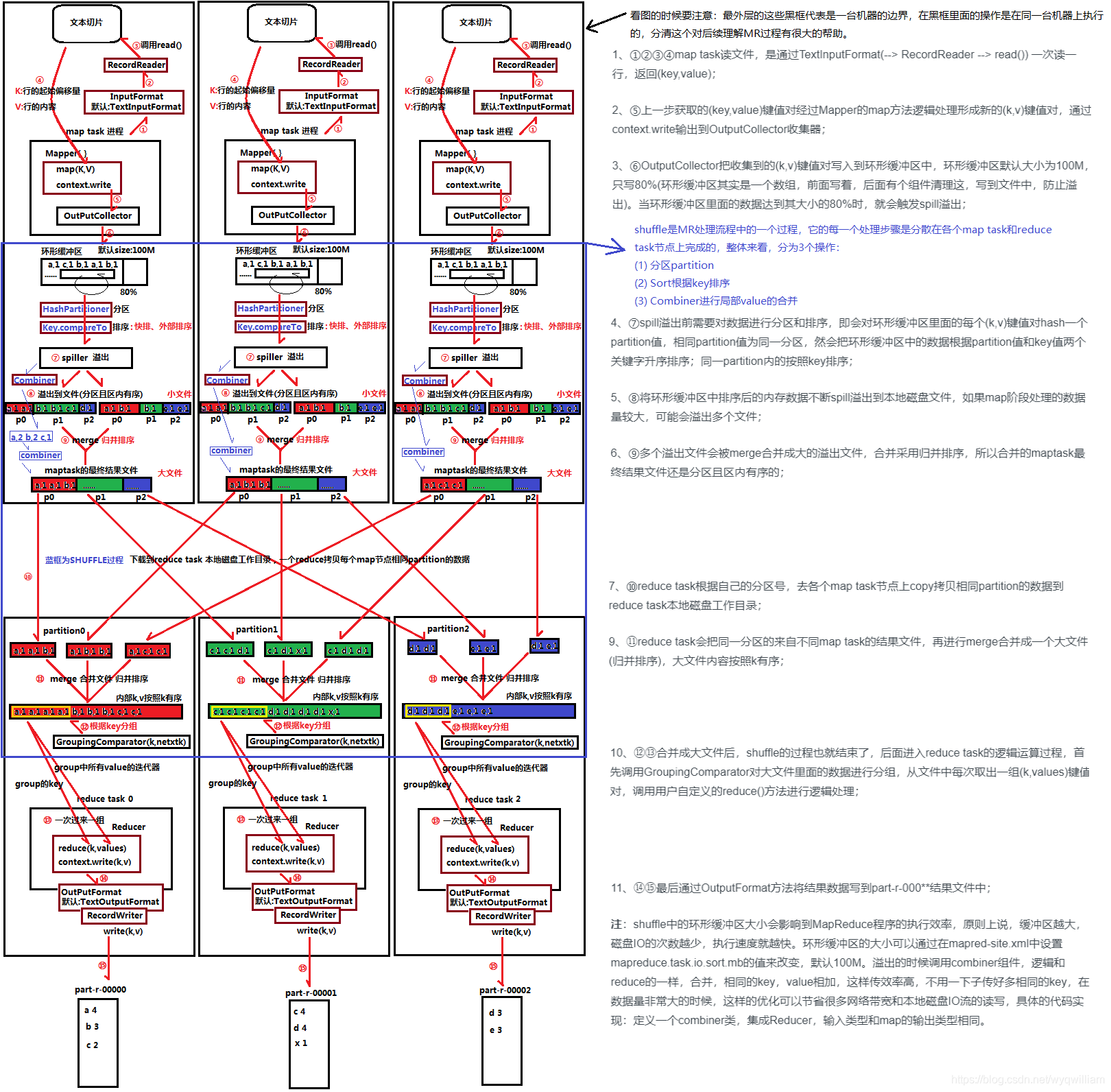
修改后的效果
.png)
总结
还是自己对底层的东西了解的不够透彻,这种问题应该是比较粗浅的,但我因为没有碰到过此类问题,所以走了很多弯路,在这里也记录下,以免以后自己再掉到同样的坑里。碰到同样问题的朋友也可以做个参考
内容来源于网络如有侵权请私信删除
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


