
软件测试回顾(9)
准备测试数据
35章:如何准备测试数据?
测试数据准备方法主要可以分为四类:
- 基于GUI操作生成测试数据;
- 通过API调用生成测试数据;
- 通过数据库操作生成测试数据;
- 综合运用API和数据库的方式生成测试数据。
1.基于GUI操作生成测试数据
优点:
- 在技术上没有任何复杂性,而且所创建的数据完全来自于真实的业务流程,
- 可以最大程度保证数据的正确性。
缺点:
- 创建测试数据的效率非常低。
- 基于GUI的测试数据创建方法不适合封装成测试数据工具。
- 测试数据成功创建的概率不会太高。
- 会引入不必要的测试依赖。如:要测试登录功能,首先就要保证注册功能没问题的。
在实际的测试过程中,我们很少直接使用基于GUI的操作生成测试数据。基于GUI操作生成测试数据的方法一般只用于手工测试
2.基于API调用生成测试数据
通过API调用生成测试数据,是目前主流的测试数据生成方法。
为了规避在创建测试数据时过于在乎实现细节的问题,在实际工程实践中,我们往往会把调用API生成测试数据的过程封装成测试数据准备函数。
怎么才能知道到底调用了哪些后端API呢?这里,我推荐三种方式:
- 直接询问开发人员,这是最直接的方法;
- 如果你有一定的代码基础,可以直接阅读源代码,这个方法也可以作为直接询问方法的补充;
- 在一个你可以独占的环境上执行GUI操作创建测试数据,与此同时监控服务器端的调用日志,分析这个过程到底调用了哪些API。
优点:
- 保证创建的测试数据的准确性
- 执行效率更高
- 创建测试数据的API调用过程,封装成测试数据函数更方便,因为这个调用过程的代码逻辑非常清晰;
- 依赖于API调用,当创建测试数据的内部逻辑有变更时,由于此时API内部的实现逻辑也会由开发人员同步更新
缺点:
- 并不是所有的测试数据创建都有对应的API支持。
- 创建一条业务线上的测试数据,往往需要按一定的顺序依次调用多个API,并且会在多个API调用之间传递数据,这也无形中增加了测试数据准备函数的复杂性。
- 执行速度上已经得到了大幅提升,并且还可以很方便地实现并发执行,但是对于需要批量创建海量数据的场景,还是会力不从心。
3.通过数据库操作生成测试数据
通过数据库操作生成测试数据,也是目前主流的测试数据生成方法。
常见的做法是,将创建数据需要用到的SQL语句封装成一个个的测试数据准备函数,当我们需要创建数据时,直接调用这些封装好的函数即可。
这样做的前提是,你需要知道前端用户通过GUI操作注册新用户时,到底修改了哪些数据库的业务表。这里,我也推荐三种方式:
- 直接向开发人员索要使用到的SQL语句;
- 直接阅读产品源代码;
- 在一个你可以独占的环境上执行GUI操作产生测试数据,与此同时,监控独占环境的数据库端业务表的变化,找到哪些业务表发生了变化。
缺点:
- 一个前端操作引发的数据创建,往往会修改很多张表,因此封装的数据准备函数的维护成本要高得多
- 容易出现数据不完整的情况,这种错误一般都会比较隐蔽,往往只在一些特定的操作下才会发生异常;
- 当业务逻辑发生变化时,即SQL语句有变化时,需要维护和更新已经封装的数据准备函数
4.综合运用API和数据库的方式生成测试数据
最典型的应用场景是,先通过API调用生成基础的测试数据,然后使用数据库的CRUD操作生成符合特殊测试需求的数据。
36章:测试数据创建的时机
要分为On-the-fly(实时创建)和Out-of-box(事先创建测试数据)两类方法。
1.On-the-fly(实时创建)
在测试用例的代码中实时创建要使用到的测试数据。
采用On-the-fly方式创建的数据,都是由测试用例自己维护的,不会依赖于测试用例外的任何数据,从而保证了数据的准确性和可控性,最大程度地避免了出现“脏”数据的可能
缺点:
- 实时创建测试数据比较耗时。
- 测试数据本身存在复杂的关联性。
- 微服务架构的调整
- 很多时候测试环境并不是100%处于全部可用的状态。也就是说,并不是所有的服务都是可用的,这就给测试数据准备带来了新的挑战。
2.Out-of-box(事先创建)
为了解决上述三个问题,Out-of-box(即事先创建测试数据)的方式就应运而生
Out-of-box方法,又称开箱即用方法,指的是在准备测试环境时就预先将测试需要用到的数据全部准备好,而不是在测试用例中实时创建。
缺点:
Out-of-box最致命的问题是“脏”数据。
那到底什么是“脏”数据呢?这里的“脏”数据是指,数据在被实际使用前,已经被进行了非预期的修改。
这些事先创建好的测试数据,在测试用例执行的那个时刻,是否依然可用其实是不一定的,因为这些数据很有可能在被使用前已经发生了非预期的修改。
这些非预期的修改主要来自于以下三个方面:
- 其他测试用例使用了这些事先创建好的测试数据,并修改了这些数据的状态;
- 执行手工测试时,因为直接使用了事先创建好的数据,很有可能就会修改了某些测试数据;
- 自动化测试用例的调试过程,修改了事先创建的测试数据;
为了解决这些“脏”数据,我们只能通过优化流程去控制数据的使用。业内有些公司会将所有事先创建好的测试数据列在一个Wiki页面,然后按照不同的测试数据区段来分配使用对象。
更糟糕的是,如果自动化测试用例直接采用硬编码的方式,去调用那些只能被一次性使用的测试数据(比如订单数据、优惠券等)的话,你会发现测试用例只能在第一次执行时通过,后面再执行都会因为测试数据的问题而失败。
Out-of-box方法不适用于只能一次性使用的测试数据场景。
3.综合运用On-the-fly和Out-of-box
实际的工程实践中,往往是采用综合运用On-the-fly和Out-of-box的方式来实现测试数据的准备的。
在实际的测试项目中,我们可以根据测试数据的特性,把它们分为两大类,用业内的行话来讲就是“死水数据”和“活水数据”。
“死水数据”是指那些相对稳定,不会在使用过程中改变状态,并且可以被多次使用的数据。比如,商品分类、商品品牌、场馆信息等。这类数据就非常适合采用Out-of-box方式来创建。
这里需要特别说明的是,哪些数据属于“死水数据”并不是绝对的,由测试目的决定。
比如,用户数据在大多数的非用户相关的测试用例中基本属于“死水数据”,
但是,对于那些专门测试用户账号的测试用例来讲,往往会涉及到用户撤销、激活、修改密码等操作,那么此时的用户数据就不再是“死水数据”了,而应该按照“活水数据”处理。
“活水数据”是指那些只能被一次性使用,或者经常会被修改的测试数据。最典型的数据是优惠券、商品本身、订单等类似的数据。这类数据通常在被一次性使用后状态就发生了变化,不能反复使用。那么这类测试数据,就更适合采用On-the-fly方式来创建。
个人觉得一定要大家使用一套产生测试数据的脚本,无论是api还是数据库,做到一键配置、恢复测试数据。还有就是死水数据的准备大家最好有统一的平台进行发放,而不是随便写,随便测
37+38章:统一测试数据平台
1.测试数据准备1.0时代
这个阶段最典型的方法就是,将测试数据准备的相关操作封装成数据准备函数。
利用这种数据准备函数创建测试数据方法的最大短板,在于其参数非常多、也非常复杂。
其实,绝大多数的测试数据准备场景是,你仅仅需要一个所有参数都使用了缺省值的测试数据,或者只对个别几个参数有明确的要求,而其他参数都可以是缺省值的测试数据。
为了解决这个问题,在工程实践中,就引入了如图1所示的封装数据准备函数的形式。

当测试用例中仅仅需要一个没有特定要求的默认用户时,你就可以直接调用这个createDefaultUser函数,
对于那些测试用例只对个别参数有要求的场景,比如只对参数A有要求的场景,我们就可以为此封装一个createXXXUser(A)函数,用默认值初始化参数B、C、D、E,然后对外暴露参数A。
如果是对多个参数有特定要求的场景,我们就可以封装出createYYYUser这样暴露多个参数的函数。
通过这样的封装,对于一些常用的测试数据组合,我们通过一次函数调用就可以生成需要的测试数据;而对于那些比较偏门或者不常用的测试数据,我们依然可以通过直接调用最底层的createUserImpl函数完成数据创建工作。可见,这个方法相比之前已经有了很大的进步。
缺点:
- 对于参数比较多的情况,会面临需要封装的函数数量很多的尴尬。
- 当底层Impl函数的参数发生变化时,需要修改所有的封装函数。
- 数据准备函数的JAR包版本升级比较频繁。
- 一旦封装的数据准备函数发生了变化,我们就要升级对应JAR包的版本号。
为了可以进一步解决这三个问题,最大程度地简化测试数据准备工作,将测试数据准备推向了2.0时代。
2.测试数据准备2.0时代
数据准备函数不再以暴露参数的方式进行封装了,而是引入了一种叫作Builder Pattern(生成器模式)的封装方式。这个方式能够在保证最大限度的数据灵活性的同时,提供使用上的最大便利性,并且维护成本还非常低。
就是之前是代码直接调用生成函数,而现在是生成函数类似使用了生成器设计模式而已
你需要准备一个用户数据,而且对具体的参数没有任何要求。
UserBuilder.build();
你现在还需要一个用户,但是这次需要的是一个美国的用户。
UserBuilder.withCountry("US").build();
你又需要这样一个用户数据:英国用户,支付方式是Paypal,其他参数都是默认值。
UserBuilder.withCountry("US").withPaymentMethod("Paypal").build();
在实际工程项目中,随着Builder Pattern的大量使用,又逐渐出现了更多的新需求,为此我归纳总结了以下4点:
- 有时候,出于执行效率的考虑,我们不希望每次都重新创建测试数据,而是希望可以从被测系统的已有数据中搜索符合条件的数据;
- 但是,还有些时候,我们希望测试数据必须是全新创建的,比如需要验证新建用户首次登录时,系统提示修改密码的测试场景,就需要这个用户一定是被新创建的;
- 更多的时候,我们并不关心这些测试数据是新创建的,还是通过搜索得到的,我们只希望以尽可能短的时间得到需要的测试数据;
- 甚至,还有些场景,我们希望得到的测试数据一定是来自于Out-of-box的数据。
为了能够满足上述的测试数据需求,我们就需要在Builder Pattern的基础上,进一步引入Build Strategy的概念。顾名思义,Build Strategy指的是数据构建的策略。
就是在简单的生成器模式下合入了策略模式,,通过策略进行生成
我们引入了Search Only、Create Only、Smart和Out-of-box这四种数据构建的策略。这四类构建策略在Builder Pattern中的使用很简单,只要按照以下的代码示例指定构建策略就可以了:
UserBuilder.withCountry(“US”).withBuildStrategy(BuildStrategy.SEARCH_ONLY.build();
UserBuilder.withCountry(“US”).withBuildStrategy(BuildStrategy.CREATE_ONLY).build();
UserBuilder.withCountry(“US”).withBuildStrategy(BuildStrategy.SMART).build();
UserBuilder.withCountry(“US”).withBuildStrategy(BuildStrategy.OUT_OF_BOX).build();
这里的Builder Pattern是基于Java代码实现的,如果你的测试用例不是基于Java代码实现的,那要怎么使用这些Builder Pattern呢?我们不希望、也不可能为每套基于不同开发语言的测试框架都封装一套Builder Pattern。所以,我们就希望一套Builder Pattern可以适用于所有的测试框架,这也就是我在前面提到的测试准备函数的“跨平台的能力”了。
为了解决这个问题,测试数据准备走向了3.0时代。
3.测试数据准备的3.0时代
为了解决2.0时代跨平台使用数据准备函数的问题,我们将基于Java开发的数据准备函数用Spring Boot包装成了Restful API,并且结合Swagger给这些Restful API提供了GUI界面和文档。
就是将测试准备函数 变成了web工具,通过restful api进行统一调用,来实现跨平台
我们就可以通过Restful API调用数据准备函数了,而且由于Restful API是通用接口,所以只要测试框架能够发起http调用,就能使用这些Restful API。于是,几乎所有的测试框架都可以直接使用这些Restful API准备测试数据。
最初,统一测试数据平台就是服务化了数据准备函数的功能,并且提供了GUI界面以方便用户使用,除此以外,并没有提供其他额外功能。如图1所示就是统一测试数据平台的UI界面。
后来,随着统一测试数据平台的广泛使用,我们逐渐加入了更多的创新设计,统一测试数据平台的架构也逐渐演变成了如图2所示的样子。
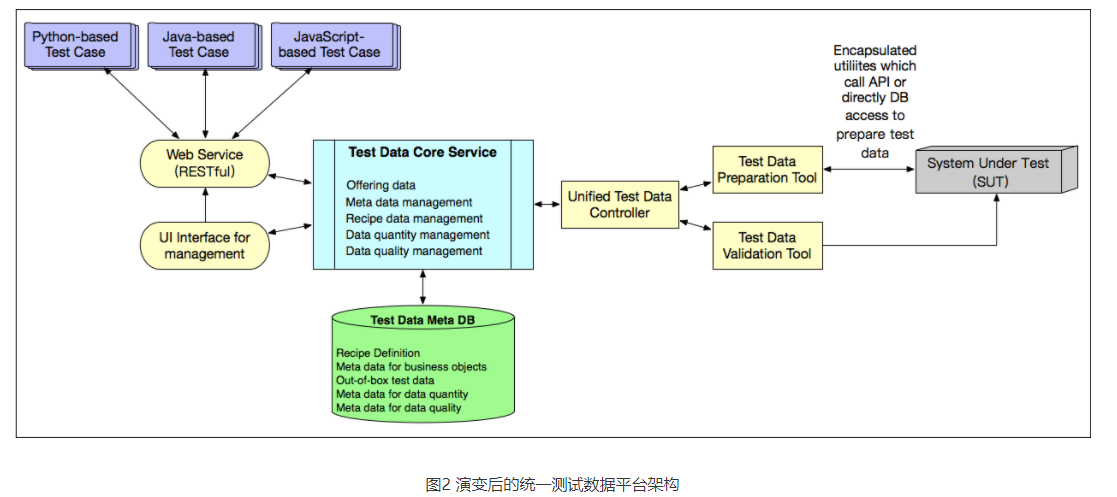
接下来,我和你分享一下统一测试数据平台的架构设计中最重要的两个部分:
- 引入了Core Service和一个内部数据库。其中,内部数据库用于存放创建的测试数据的元数据;Core Service在内部数据库的支持下,提供数据质量和数量的管理机制。
- 当一个测试数据被创建成功后,为了使得下次再要创建同类型的测试数据时可以更高效,Core Service会自动在后台创建一个Jenkins Job。这个Jenkins Job会再自动创建100条同类型的数据,并将创建成功的数据的ID保存到内部数据库,当下次再请求创建同类型数据时,这个统一测试数据平台就可以直接从内部数据库返回已经事先创建的数据。
在一定程度上,这就相当于将原本的On-the-fly转变成了Out-of-box,缩短整个测试用例的执行时间。当这个内部数据库中存放的100条数据被逐渐被使用,导致总量低于20条时,对应的Jenkins Job会自动把该类型的数据补足到100条。而这些操作对外都是透明的,完全不需要我们进行额外的操作。
我看老师的留言下面有个人说怎么一直在科普概念。我认为老师的这段回复很好
很多时候概念本身比会使用工具来得重要的多,对于测试数据准备的文章中介绍的很多方法和理念都是外面找不到的,都是来自于大项目中的工程实践,如果大家对工具本身的使用更感兴趣,我还是建议通过官方文档进行学习,但是怎么找到适合你的工具,以及学习这些工具设计的思路,还是要能够掌握原理。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!
 客服
客服


