
今天咱们要爬取花瓣网 https://huaban.com/
设计师寻找灵感的天堂!有海量的图片素材可以下载,是一个优质图片灵感库
这次我们用 requests 登录花瓣网,爬取页面,再用正则与json提取有用信息,最后把获取的图片信息 保存到本地
一 、用到技术
python 基础requests登录页面获取session用户会话,下载图片正则表达式提取页面的有用信息json解析页面中的图片
二、 目标页面
https://huaban.com/search/?q=女神&category=photography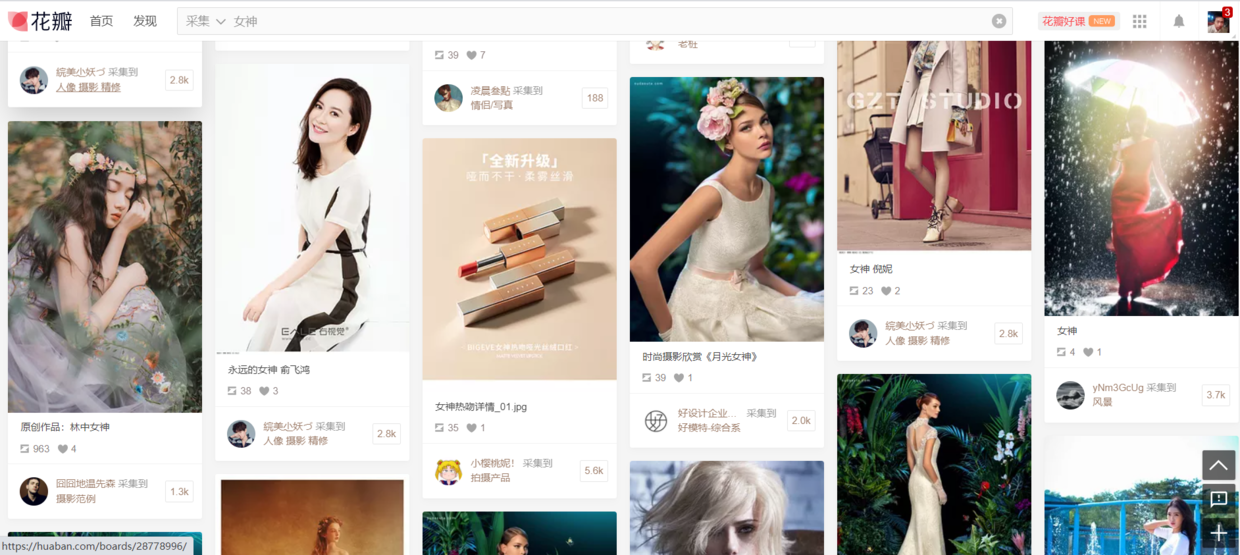
三、结果
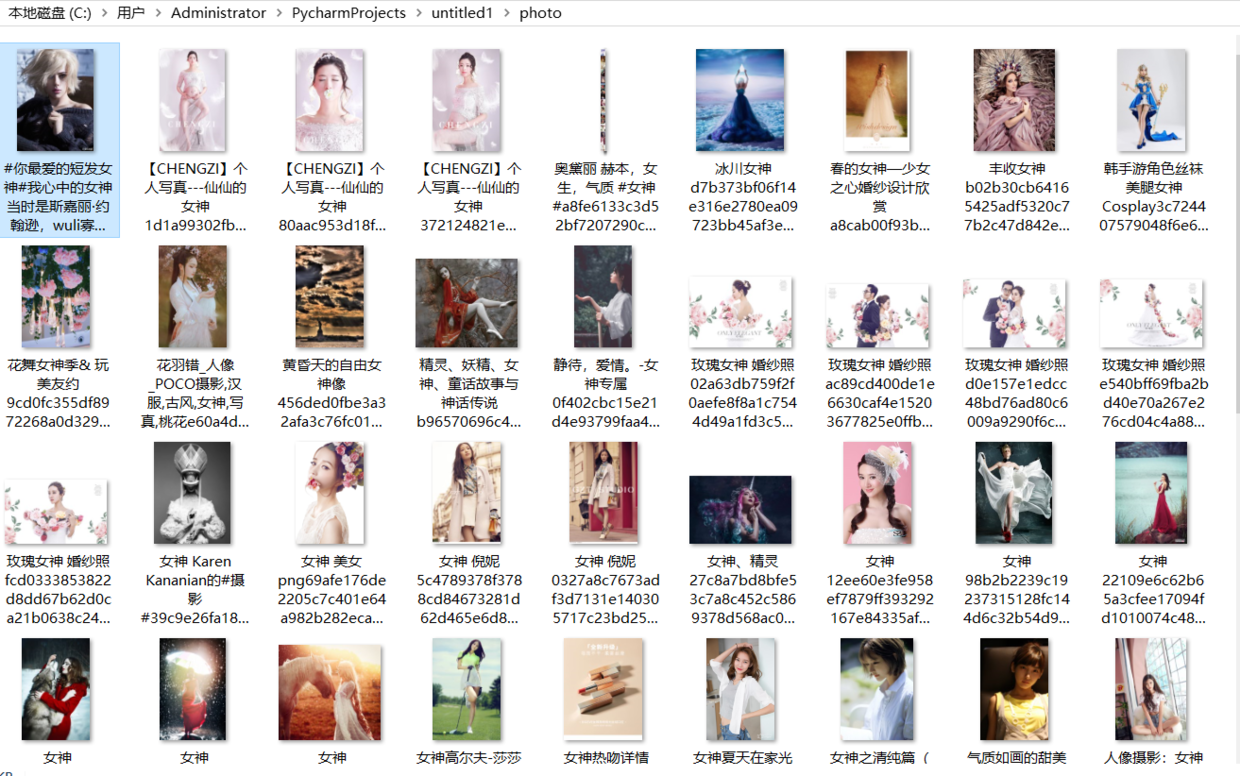
四、安装 必要的库
- win+R 打开运行
- 输出cmd 进入控制台
- 分别安装
requests
pip install requests
五、分析页面
- 页面规律
我们单击分页按钮,拿到页面最后一个参数的规律
第一页:https://huaban.com/search/?q=女神&category=photography&page=1
第二页:https://huaban.com/search/?q=女神&category=photography&page=2
2.登录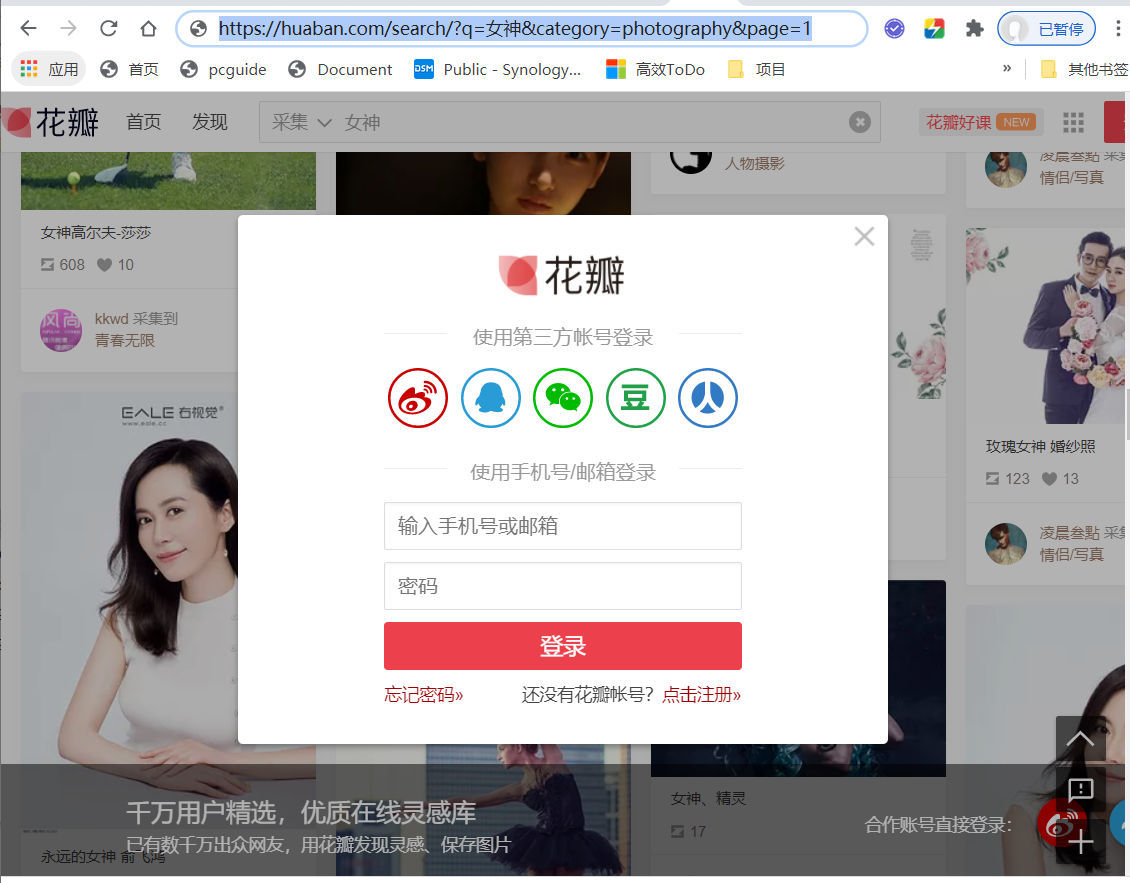
通过Fiddler我们查看到登录请求的地址和参数
# 地址
https://huaban.com/auth/
# 参数
"email": "******",
"password": "*****",
"_ref":"frame"
我决定使用requests的session()功能来获取用户登录后的会话session信息
3. 页面信息
我们通过右键查看源代码发现数据是保存在javascript里面的我们准备用正则表达式提取页面信息
六、全部代码
#-*- coding:utf-8 -*-
import requests
import re
import json
# 导入 requests re正则 json
'''
login
登录花瓣 获取session
'''
def login():
login_url = 'https://huaban.com/auth/'
# 登录地址
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0",
"Accept": "application / json",
"Content-type": "application/x-www-form-urlencoded; charset=utf-8",
"Referer": "https://huaban.com/",
}
# 请求头信息
session = requests.session()
#sesson 会话
login_data = {
"email": "zengmumu%40126.com",
"password": "zmm123",
"_ref":"frame"
}
response = session.post(login_url, data=login_data, headers=headers,verify=False)
# 登录页面
getPic(session,5)
# 获取图片,前5页
'''
getPic
解析页面中的图片地址
session 会话信息
num 最大是页数
'''
def getPic(session,num):
for i in range(1,num+1):
response = session.get("https://huaban.com/search/?q=%E5%A5%B3%E7%A5%9E&category=photography&page="+str(i))
# 获取页面信息("美女"文字编码后的结果是"%E5%A5%B3%E7%A5%9E" )
data = re.search('app.page["pins"] =(.*);napp.page["page"]', response.text, re.M | re.I | re.S)
# 提取到当前页面所在的所有图片信息
data = json.loads(data.group(1))
# 转换字符串为列表
for item in data:
url = "https://hbimg.huabanimg.com/" + item["file"]["key"]
# 拼接图片地址
index = item["file"]["type"].rfind("/")
type = "."+item["file"]["type"][index + 1:]
# 获取图片的类型
file_name = item["raw_text"]
# 获取图片的中文名
download_img(url, file_name,type)
# 下载图片
'''
下载图片
url 图片的地址
name 图片的中文名
type 图片的类型
'''
def download_img(url,name,type):
response = requests.get(url,verify=False)
# 使用requests 下载图片
index = url.rfind('/')
file_name = name+url[index + 1:]+type
# 获取图片的hash值
print("下载图片:" + file_name)
# 打印图片名称
save_name = "./photo/" + file_name
# 图片保存的地址(注意photo要自己建一个,与当前.py文件同一个文件夹)
with open(save_name, "wb") as f:
f.write(response.content)
# 写入图片到本地
'''
定义主函数
'''
def main():
login()
# 如果到模块的名字是__main__ 执行main主函数
if __name__ == '__main__':
main()
单词表
main 主要的 login 登录
response 响应 content 内容
write 写入 save 保存
print 打印 rfind 从右边查找
download 下载 type 类型
group 组 search 查找
session 会话 group 组
headers 头部 data 数据
request 请求 coding 编码格式
在线练习:https://www.520mg.com/it
IT 入门 感谢关注
内容来源于网络如有侵权请私信删除
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


