
作者|Bex Tuychiev
编译|VK
来源|Towards Datas Science
介绍
本文的目标是让你对使用Seaborn的relplot()函数绘制统计图有一定的了解。
当我开始学习数据可视化时,我第一次被介绍到Matplotlib。它是一个如此巨大的库,你几乎可以看到任何与数据相关的东西。正是这种广阔的空间,使人们能够以多种方式创造一个单一的图表。
虽然它的灵活性对于经验丰富的科学家来说是理想的,但作为一个初学者,要区分这些方法之间的代码对我来说简直是一场噩梦。作为一名程序员,我甚至考虑过使用Tableau的无代码接口,这一点我深感羞愧。我想要一个易于使用的东西,同时,使我能够创建那些其他人(在代码中)正在制作的酷图。
我在学生阶段了解了Seaborn,最后找到了我的选择。我对数据可视化的黄金法则理解是“如果你能在Seaborn做的话,就在Seaborn做”。它比其对应的Matplotlib提供了许多优势。
首先,它非常容易使用。只需几行代码就可以创建复杂的绘图,并且使用内置样式仍然可以使其看起来很漂亮。其次,它与Pandas数据帧配合得非常好,这正是作为数据科学家所需要的。
最后但并非最不重要的是,它构建在Matplotlib本身之上。这意味着你将享受Mpl提供的大部分灵活性,同时仍将代码语法保持在最低限度。
Seaborn将其所有API分为三类:绘制统计关系、可视化数据分布和分类数据绘图。Seaborn提供了三个高级函数,它们包含了它的大部分特征,其中之一是relplot()。
relplot()可以可视化定量变量之间的任何统计关系。在本文中,我们将介绍这个函数的几乎所有特性,包括如何创建子图等等。
概述
- 简介
- 安装
- 带有relplot()的散点图
- 散点图的点大小
- 散点图的色调
- 散点图样式
- 散点图的点透明度
- 散点图中的子图
- 线图
- 多行线图
- 线图线条样式
- 线条的点标记
- 线图置信区间
- 结论
获取此GitHub repo上文章的notebook和示例数据:https://github.com/BexTuychiev/medium_stories/tree/master/learn_one_third_of_seaborn_relplot
安装
# 加载必要的库
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
# 绘制漂亮的图形,避免模糊的图像
%config InlineBackend.figure_format = 'retina'
# 设置环境
sns.set_context('notebook')
# 忽略警告
import warnings
warnings.filterwarnings('ignore')
# 启用多个单元输出
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = 'all'
我们以sns的缩写导入Seaborn。你可能一直在想,为什么它不被缩写为sb。好吧,看看这个:它的别名来自电视剧《The West Wing》中的一个虚构人物Samuel Norman Seaborn。这是一个开玩笑的首字母缩写。
对于示例数据,我将使用Seaborn的一个内置数据集和一个我从Kaggle下载的数据集。你可以通过这个链接得到它:https://www.kaggle.com/dgawlik/nyse/download
# 加载示例数据
cars = sns.load_dataset('mpg')
stocks = pd.read_csv('data/prices-split-adjusted.csv',
parse_dates=['date'],
index_col=0)
第一个数据集是关于汽车的数据,包括发动机、车型等。第二个数据集提供了500多家公司的纽约股票价格信息。
基础探索
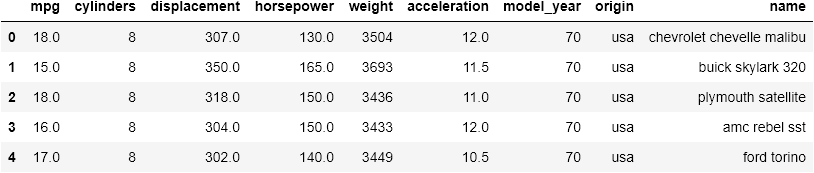
cars.head()
cars.info()
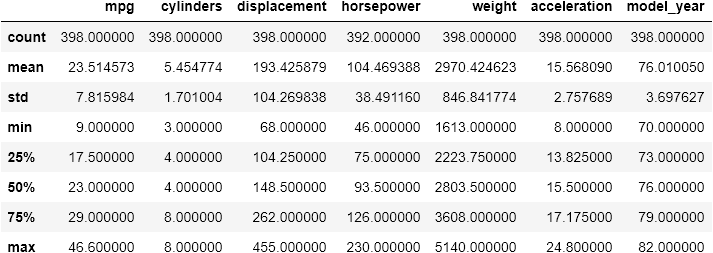
cars.describe()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 398 entries, 0 to 397
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 mpg 398 non-null float64
1 cylinders 398 non-null int64
2 displacement 398 non-null float64
3 horsepower 392 non-null float64
4 weight 398 non-null int64
5 acceleration 398 non-null float64
6 model_year 398 non-null int64
7 origin 398 non-null object
8 name 398 non-null object
dtypes: float64(4), int64(3), object(2)
memory usage: 28.1+ KB
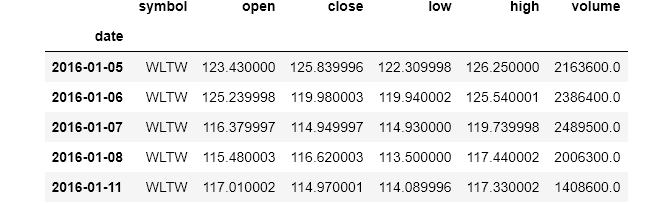
stocks.head()
stocks.info()
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 851264 entries, 2016-01-05 to 2016-12-30
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 symbol 851264 non-null object
1 open 851264 non-null float64
2 close 851264 non-null float64
3 low 851264 non-null float64
4 high 851264 non-null float64
5 volume 851264 non-null float64
dtypes: float64(5), object(1)
memory usage: 45.5+ MB
两个数据集中都有一些空值。我们目的是演示,我们就可以放心的丢弃它们。
cars.dropna(inplace=True)
stocks.dropna(inplace=True)
专业提示:让你的数据集尽可能的整洁,这样Seaborn才能表现出色。确保每一行都是一个观察值,每一列都是一个变量。
使用relplot绘散点图
让我们从散点图开始。散点图是用来找出变量之间的模式和关系的最好和最广泛使用的图之一。
这些变量通常是定量的,例如测量值、一天中的温度或任何数值。散点图将x和y值的每个元组可视化为一个点,并且该图将形成一个点云。这些类型的图是人眼探测模式和关系的理想选择。
你可以使用sb(我将从现在开始缩写为sb)的内置scatterplot()函数创建散点图。但是这个函数缺少relplot()中版本所提供的灵活性。让我们看一个使用relplot()的示例。

利用汽车数据集,我们想知道重型汽车是否具有更大的马力。由于这两个特征都是数值型的,我们可以使用散点图:
sns.relplot(x='weight', y='horsepower',
data=cars, kind='scatter');
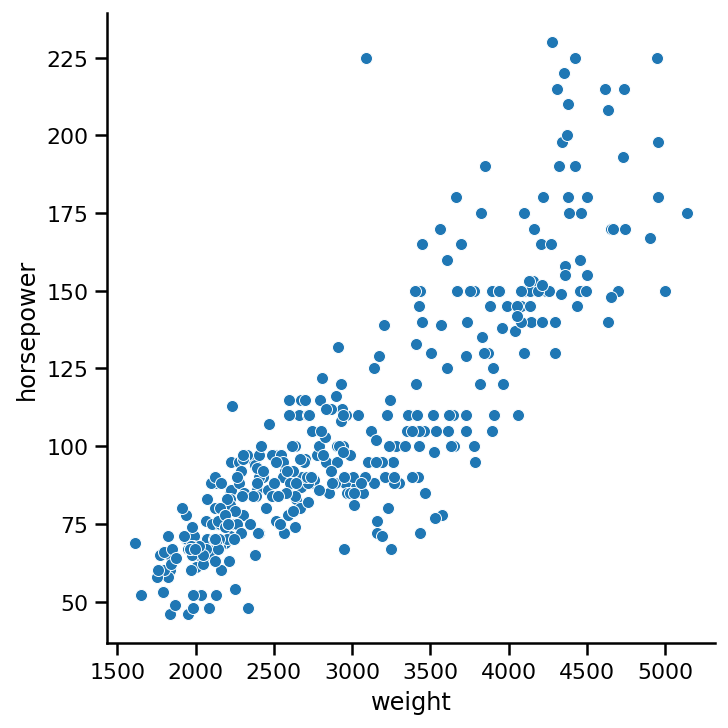
函数具有参数x、y和data参数,分别指定要在X、Y轴上绘制的值以及它应该使用的数据。我们使用kind参数指定它应该使用散点图。实际上,默认情况下,它被设置为scatter。
从图表来看,可以解释为较重的汽车确实有更大的马力。很明显,还有更多的汽车重量在1500到3000之间,马力50-110。
散点图的点大小
在前面的图的基础上,现在我们还想添加一个新变量。让我们看看重车是否有更大的排量(他们能储存多少燃料)。理想情况下,我们希望将此变量绘制为点的大小:
sns.relplot(x='weight',
y='horsepower',
data=cars,
kind='scatter',
size='displacement');
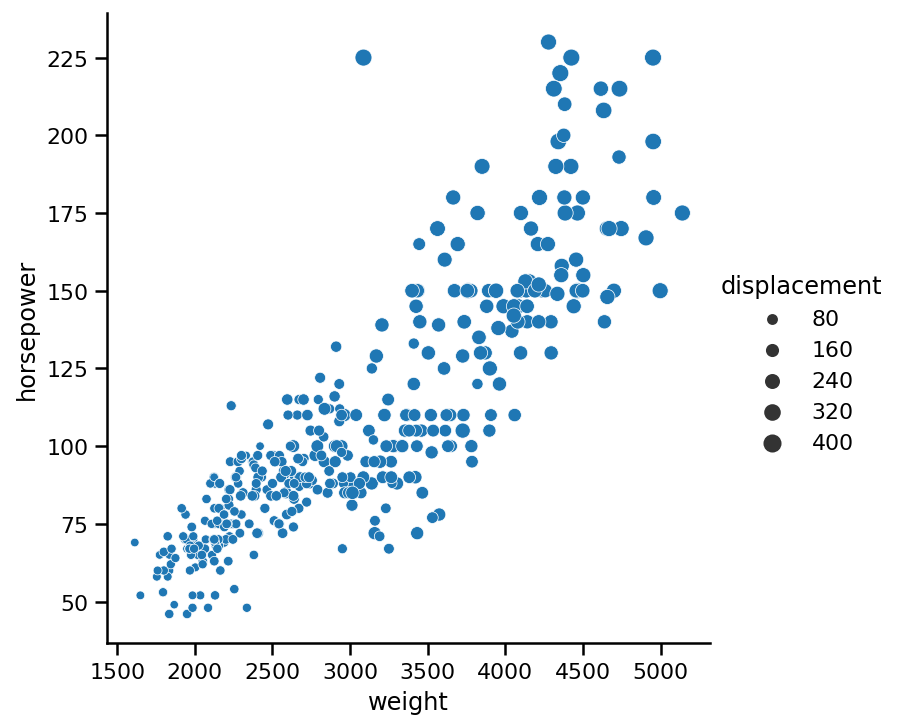
使用size参数来改变相对于第三个变量的点大小。只需将列名作为字符串传递,就可以进行设置,就像我们的示例中一样。此图显示了重量和发动机尺寸之间的明确关系。但是,你可以在中心看到一些不符合趋势的点。
重要的是传递一个数值变量,它将具有较少的“值周期”。如果太多的话,你的眼睛会很难理解这些事情。如果我们用第三个变量weight创建上面的图,你可以看到:
sns.relplot(x='displacement',
y='horsepower',
data=cars,
kind='scatter',
size='weight');
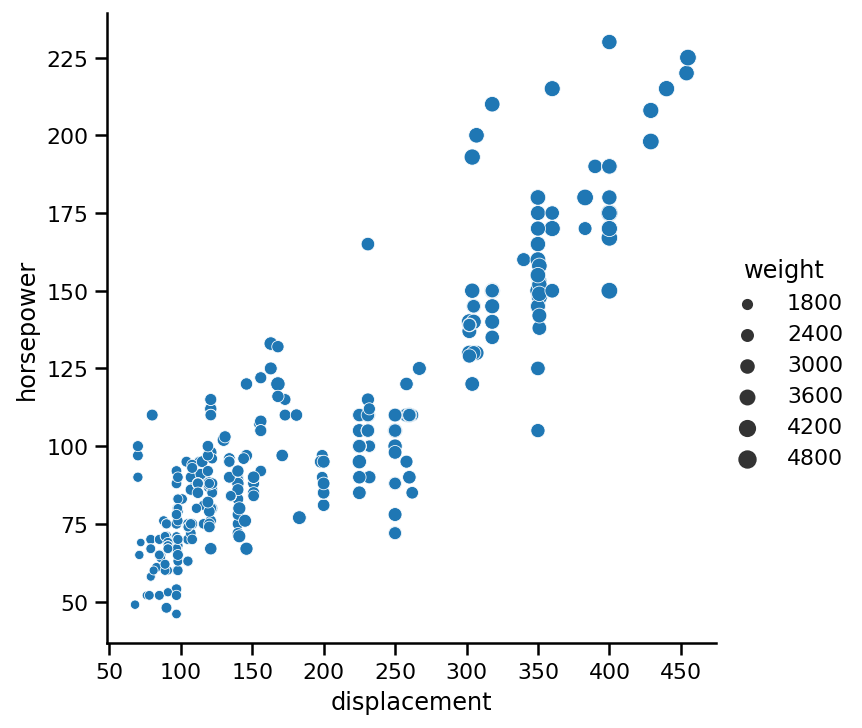
正如你所见,趋势并不明显,很难区分大小。
散点图的色调
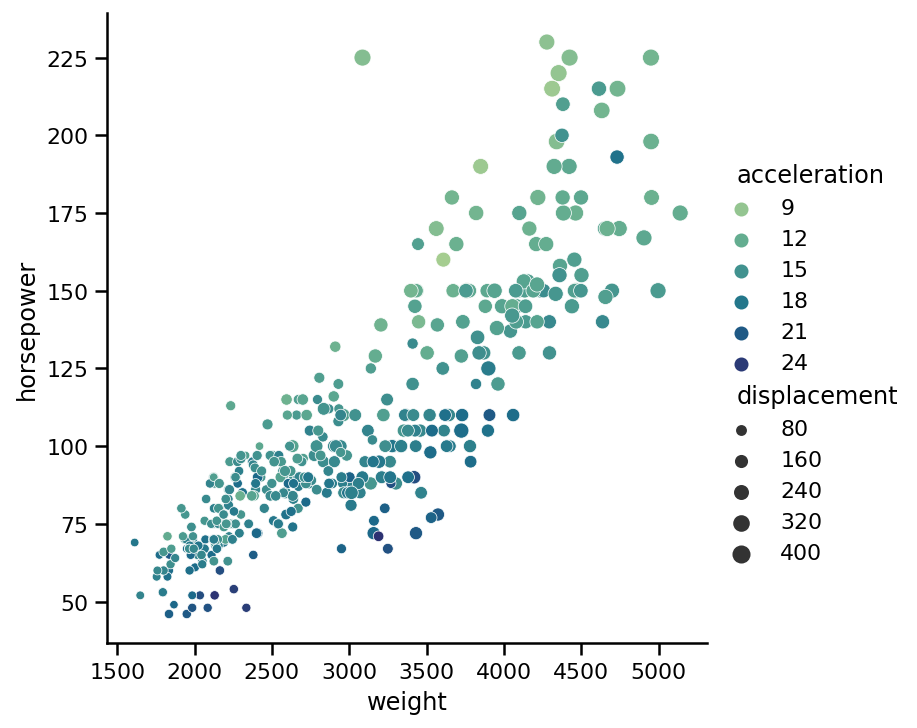
也可以将颜色标记用于散点图中的第三个变量。它也非常简单,就像点大小一样。假设我们还想将加速度(汽车达到60英里/小时(秒)的时间)编码为点颜色:
sns.relplot(x='weight',
y='horsepower',
data=cars,
kind='scatter',
size='displacement',
hue='acceleration');
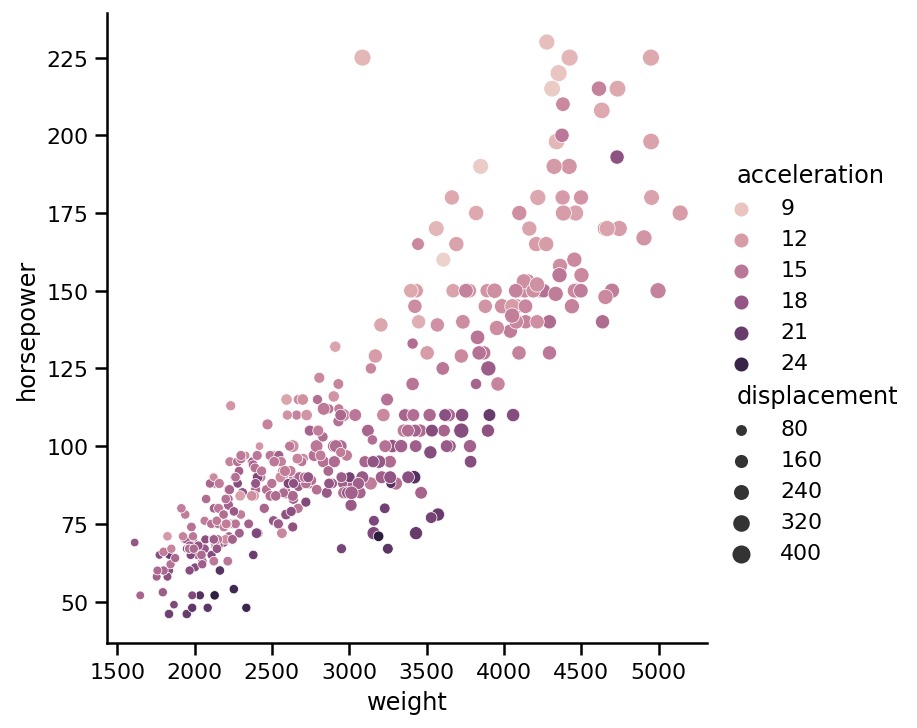
从图中,我们可以看到数据集中一些速度最快的汽车(较暗的点)马力较低,但重量也较轻。注意,我们使用hue参数来编码颜色。颜色根据传递给此参数的变量类型而变化。如果我们传递origin列,它是一个范畴变量,那么它将有三个颜色标记,而不是一个连续的(从亮到暗)色调:
sns.relplot(x='weight',
y='horsepower',
data=cars,
kind='scatter',
size='displacement',
hue='origin');
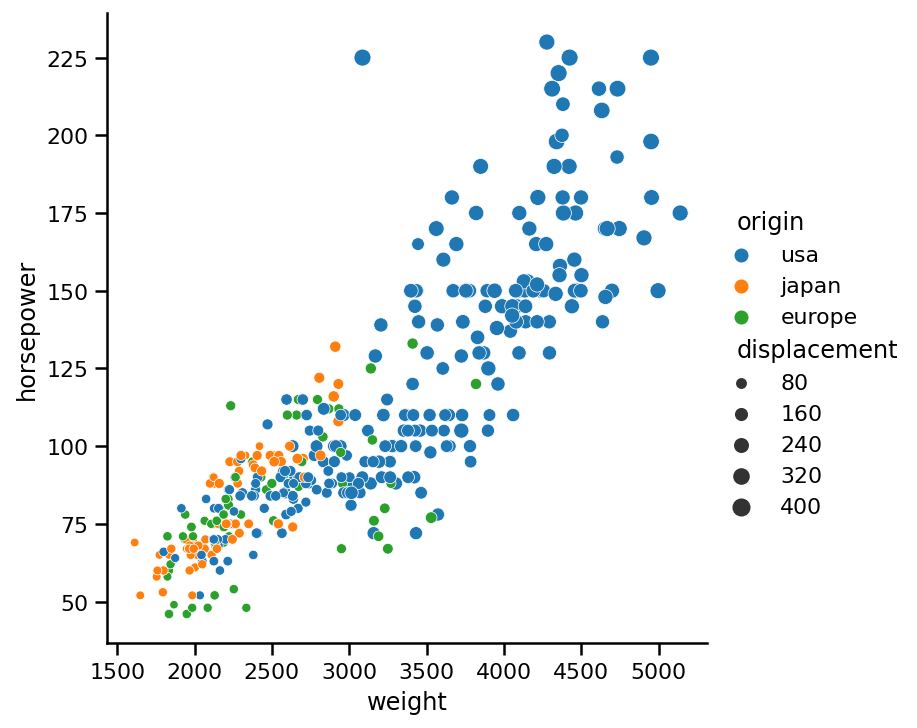
专业提示:注意输入到hue参数的变量类型。类型可以完全更改结果。
如果你不喜欢默认调色板(默认情况下非常好),可以轻松自定义:
sns.relplot(x='weight',
y='horsepower',
data=cars,
kind='scatter',
size='displacement',
hue='acceleration',
palette='crest');
将palette参数设置为你自己的颜色映射。可在此处找到可用选项板的列表:http://seaborn.pydata.org/tutorial/color_palettes.html
散点图样式
让我们回到第一个图。我们绘制了重量与马力的散点图。现在,让我们添加origin列作为第三个变量:
sns.relplot(x='weight', y='horsepower',
data=cars, hue='origin');
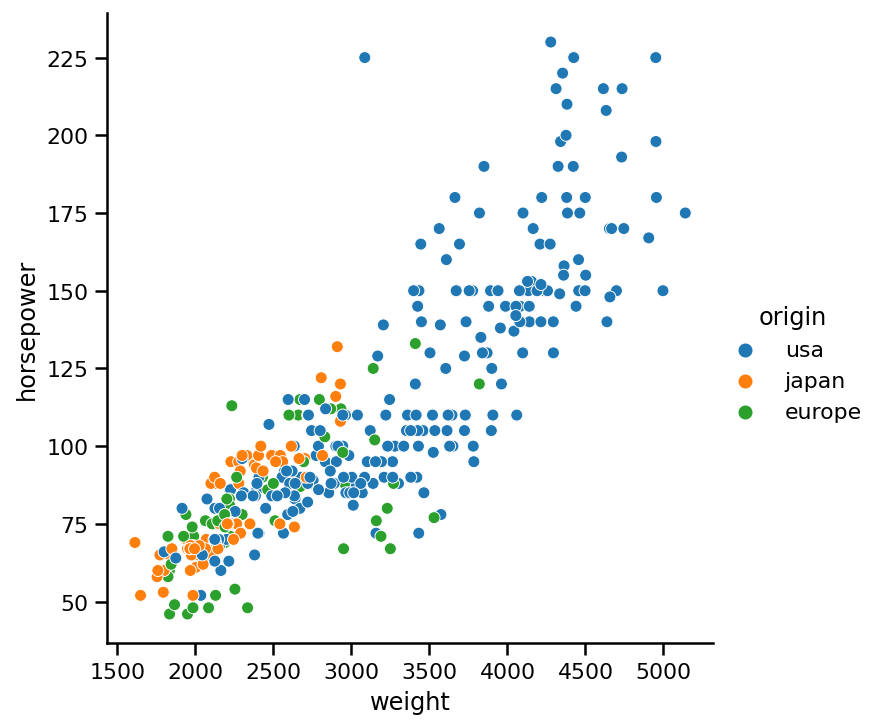
虽然颜色在这张图中增加了一层额外的信息,但在更大的数据集中,可能很难区分点群中的颜色。为了更清晰起见,我们将点的样式添加到绘图中:
sns.relplot(x='weight',
y='horsepower',
data=cars,
hue='origin',
style='origin');
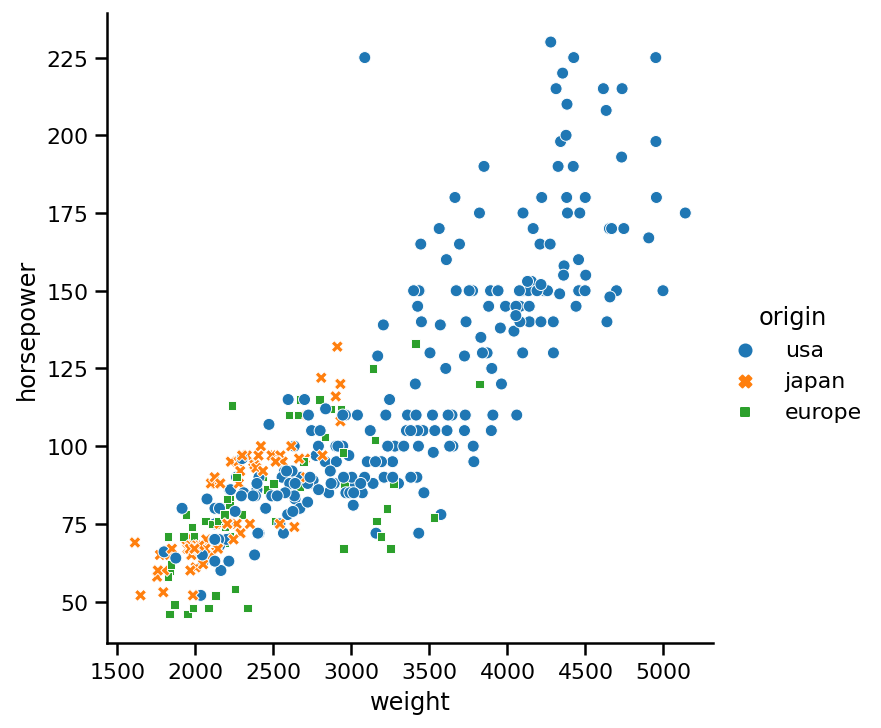
好一点了。改变点的样式和颜色是非常有效的。如果我们只使用点的样式来指定原点,看看会发生什么:
sns.relplot(x='weight', y='horsepower',
data=cars, style='origin');
提示:将色调和样式参数结合使用,可以使绘图更加清晰。
我们去掉了色调的参数,这使得我们的图表更难理解。如果不喜欢默认颜色,你可以更改:
首先,你应该创建一个字典,将各个颜色映射到每个类别。请注意,该字典的键应该与图例中的名称相同。
hue_colors = {'usa': 'red',
'japan': 'orange',
'europe': 'green'}
sns.relplot(x='weight',
y='horsepower',
data=cars,
hue='origin',
style='origin',
palette=hue_colors);

从图中可以看出,我们数据集中的大部分汽车都来自美国。
散点图的点透明度
让我们再次回到我们的第一个例子。让我们再画一次,但要增加一点透明度:
sns.relplot(x='weight', y='horsepower',
data=cars, alpha=0.6);
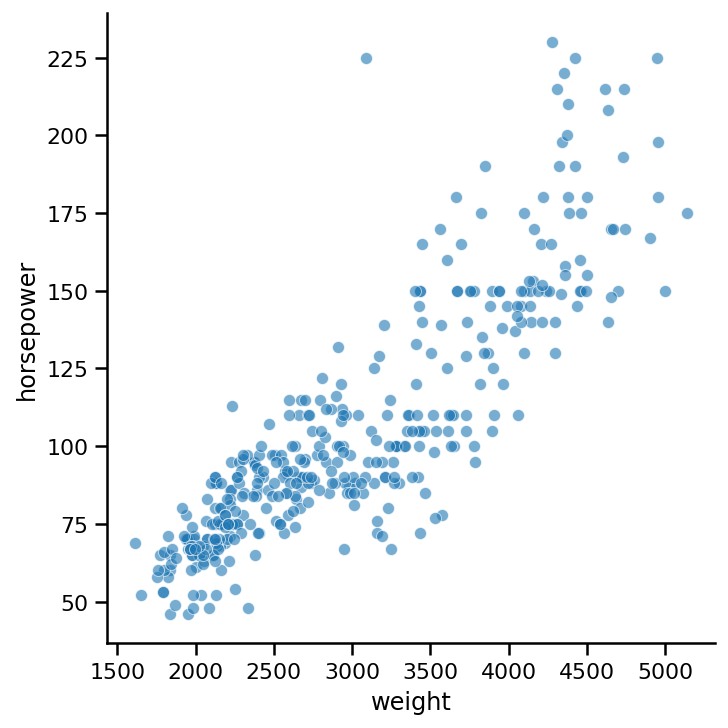
我们使用alpha参数来设置点的透明度。它接受0到1之间的值。0是完全透明的,1是完全不透明的。当你有一个大的数据集并且你想找出图中的簇或组时,它是一个非常有用的特性。降低透明度时,图中有许多圆点的部分将变暗。
散点图中的子图
在Seaborn也可以使用子图。我之所以使用relplot()而不是scatterplot(),因为它不能创建一个子图。
由于relplot是一个图形级别的函数,它生成一个FacetGrid(一个由多个绘图组成的网格)对象,而scatterplot()只打印到一个matplotlib.pyplot.Axes(单个绘图)不能转换为子图的对象:
fg = sns.relplot()
print(type(fg))
plot = sns.scatterplot()
print(type(plot))
<class 'seaborn.axisgrid.FacetGrid'>
<class 'matplotlib.axes._subplots.AxesSubplot'>
让我们看一个例子,我们想在其中使用子图。在上面的其中一个图中,我们将4个变量编码到一个单独的图中(重量,马力,排量和加速度)。现在,我们还要添加汽车的原产地。为了使信息更易于解释,我们应该将其划分为子图:
sns.relplot(x='weight',
y='horsepower',
data=cars,
kind='scatter',
size='displacement',
hue='acceleration',
palette='crest',
col='origin');
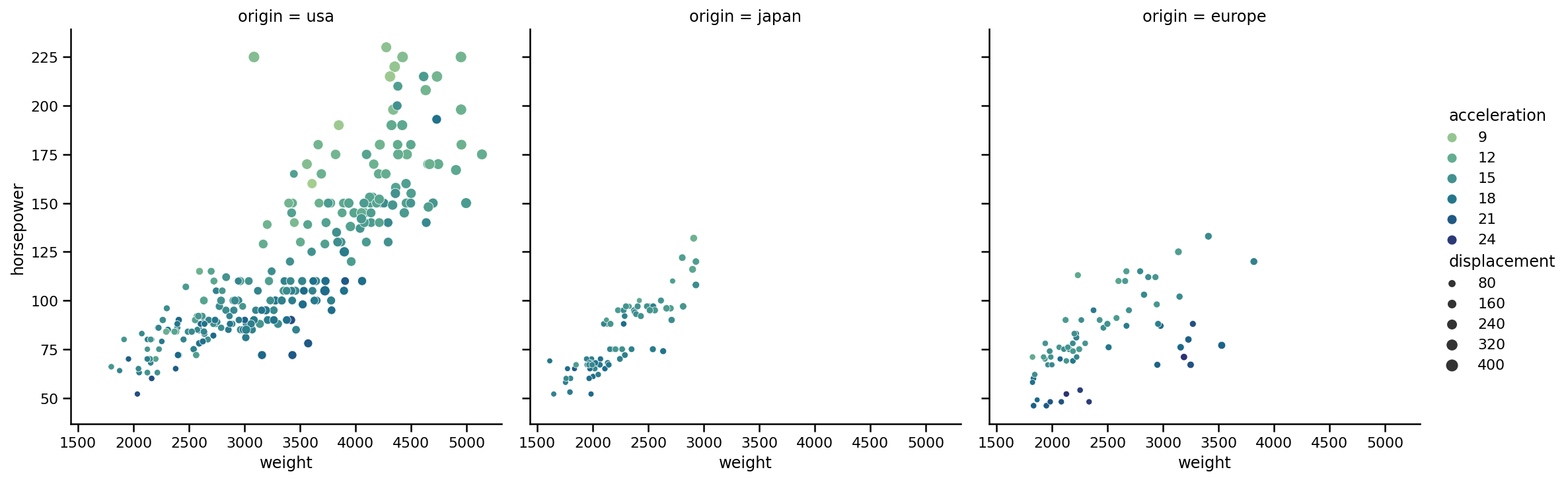
这一次,我们添加了一个新参数col,指出我们希望在列中创建子图。这些类型的子区间非常有用,因为现在很容易看到第五个变量的趋势。顺便说一句,传递给col的变量应该是离散的,这样才能起作用。此外,SB在一行中显示列。如果有多个类别需要绘制,我们不希望这样。让我们看一个使用我们的数据的用例,尽管它的类别较少:
sns.relplot(x='weight',
y='horsepower',
data=cars,
kind='scatter',
size='displacement',
hue='acceleration',
palette='crest',
col='origin',
col_wrap=2);
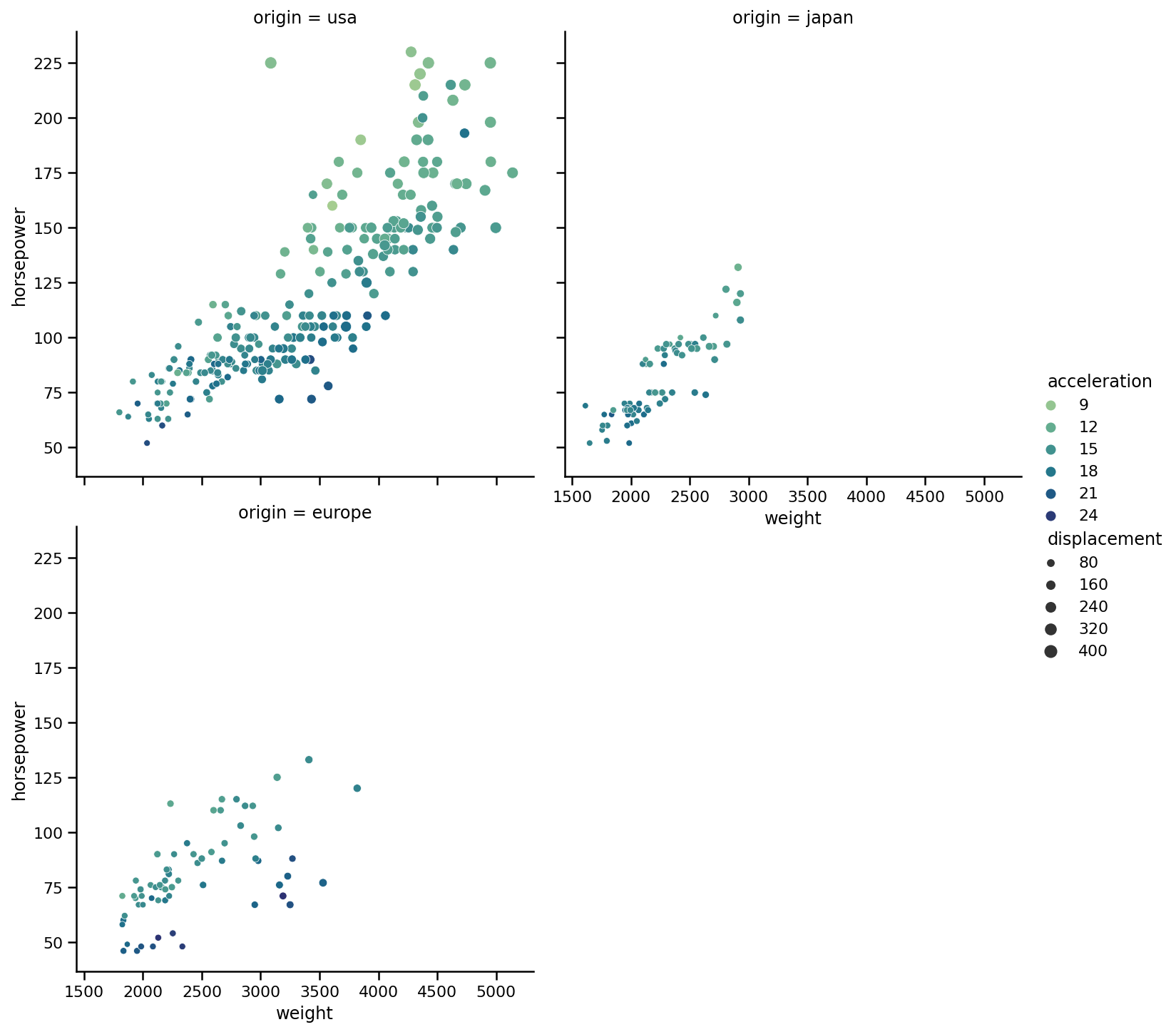
col_wra参数告诉SB我们希望一行中有多少列。
还可以指定列中类别的顺序:
sns.relplot(x='weight',
y='horsepower',
data=cars,
kind='scatter',
size='displacement',
hue='acceleration',
palette='crest',
col='origin',
col_order=['japan', 'europe', 'usa']);
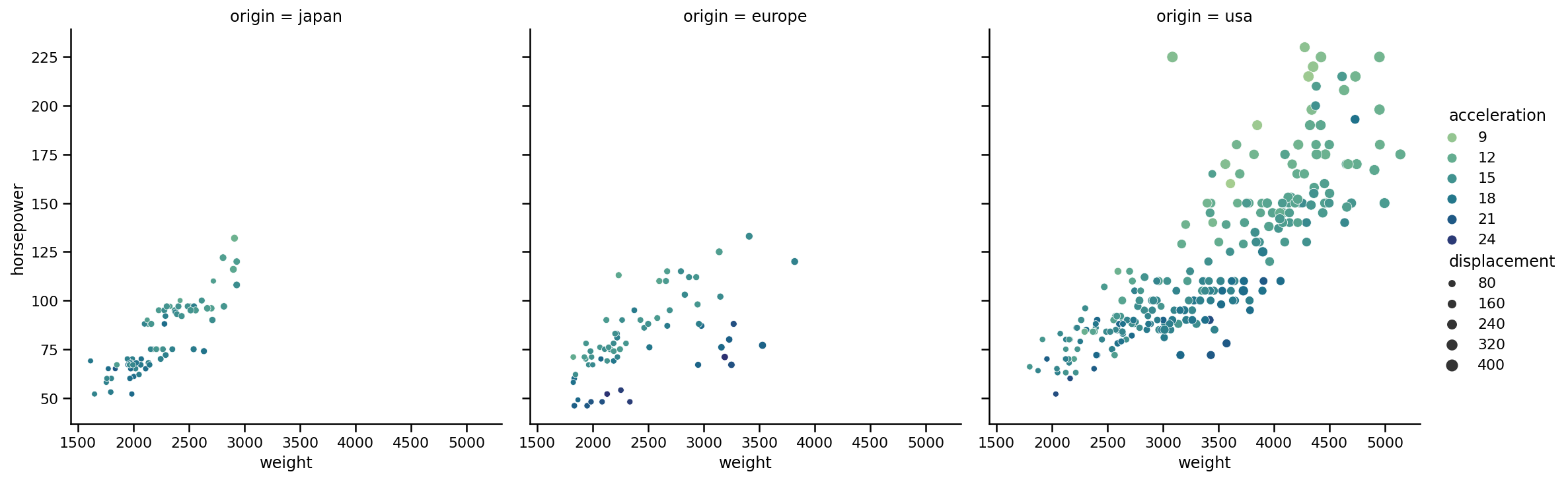
也可以在行中显示相同的信息:
sns.relplot(x='weight',
y='horsepower',
data=cars,
kind='scatter',
size='displacement',
hue='acceleration',
palette='crest',
row='origin');

如果有很多类别,那么使用行并不是很有用,最好还是坚持使用列。你可以再次使用row_order指定行的顺序。
线图
关系图的另一种常见类型是线图。而在散点图中,每个点都是一个独立的观察点,在线图中,我们绘制了一个变量和一些连续变量,通常是一段时间。我们的第二个样本数据集包含2010年至2016年跟踪的501家公司的纽约证券交易所数据。
为了便于说明,让我们观察给定时间段内所有公司的收盘价。由于涉及日期,因此线条图是此任务的最佳视觉类型:
专业提示:如果数据集中有一个日期列,请将其设置为日期类型,然后使用set_index()函数将其设置为索引。或使用pd.read_csv(parse_dates=['date_column'], index_col='date_column')。它将允许你绘制线图,并使日期的设置更容易。
对于线图,我们再次使用relplot()并将kind设置为line。这将绘制第二个连续变量(通常是时间)上跟踪的单个变量。
sns.relplot(x=stocks.index, y='close',
data=stocks, kind='line');
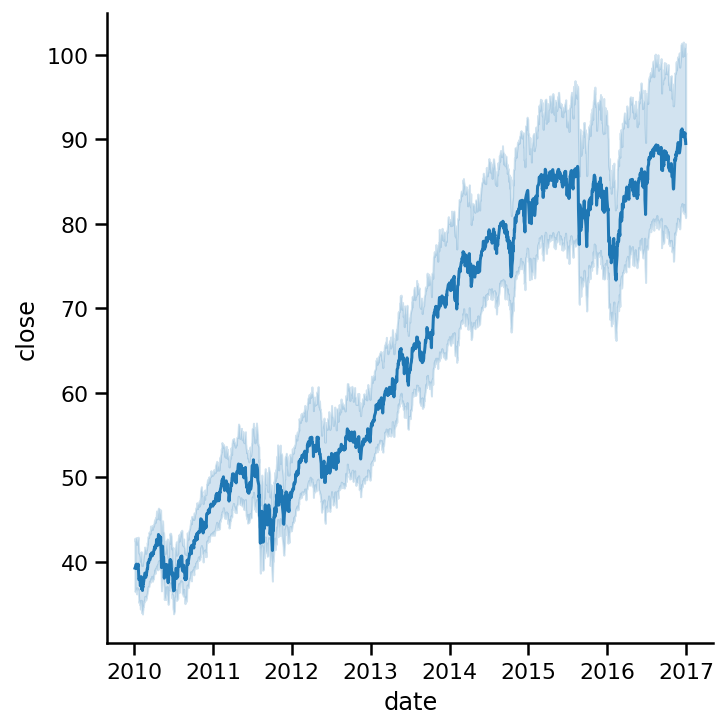
我们可以看到明显的趋势。所有公司的股票在给定的时间段内都在增长。蓝色较深的线代表6年来追踪的所有公司收盘价的平均值。
SB会自动增加一个置信区间,如果对一个点有多个观测会添加那条线周围的阴影区域,稍后会详细介绍。现在,让我们把数据集中到3家公司:
am_ap_go = stocks[stocks['symbol'].isin(['AMZN', 'AAPL', 'GOOGL'])]
am_ap_go.shape
(5286, 6)
多行线图
现在,让我们通过将数据分组到三个公司来重新创建上面的线图。这将在同一绘图中创建三条线,而不是一条:
sns.relplot(x=am_ap_go.index,
y='close',
data=am_ap_go,
kind='line',
hue='symbol');
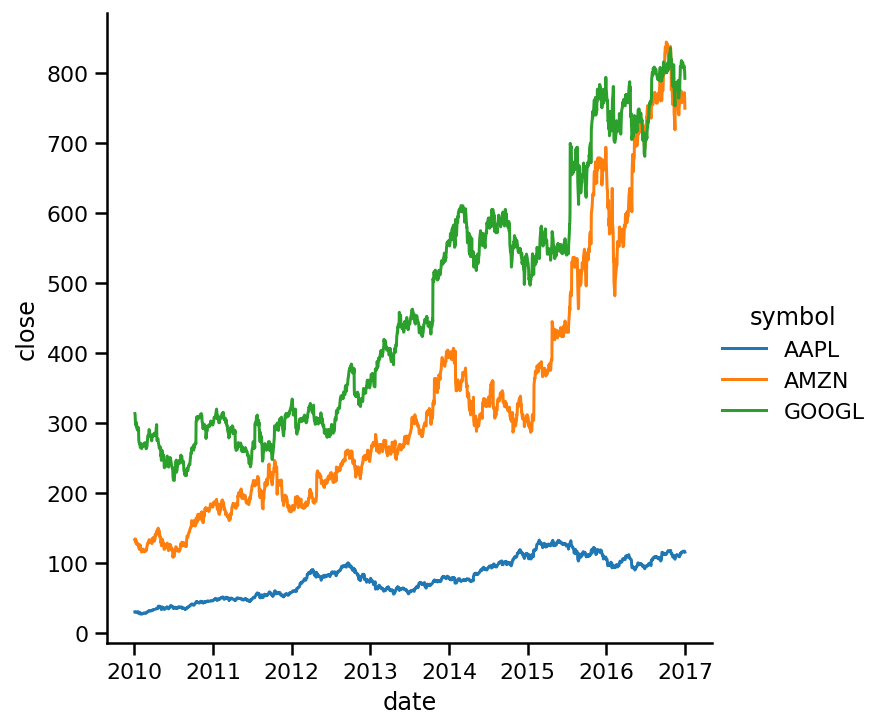
就像我们在散点图示例中所做的那样,我们使用hue参数在数据中创建子组。同样,你必须将一个范畴变量传递到hue中。在这幅图中,我们可以看到,在2016年之后,亚马逊和谷歌的股价非常接近,而苹果在整个期间都处于底部。现在,让我们看看我们是如何将每一行与颜色区分开来的:
线图线条样式
我们使用style参数来指定每一行需要不同的线条样式:
sns.relplot(x=am_ap_go.index,
y='close',
data=am_ap_go,
kind='line',
hue='symbol',
style='symbol');
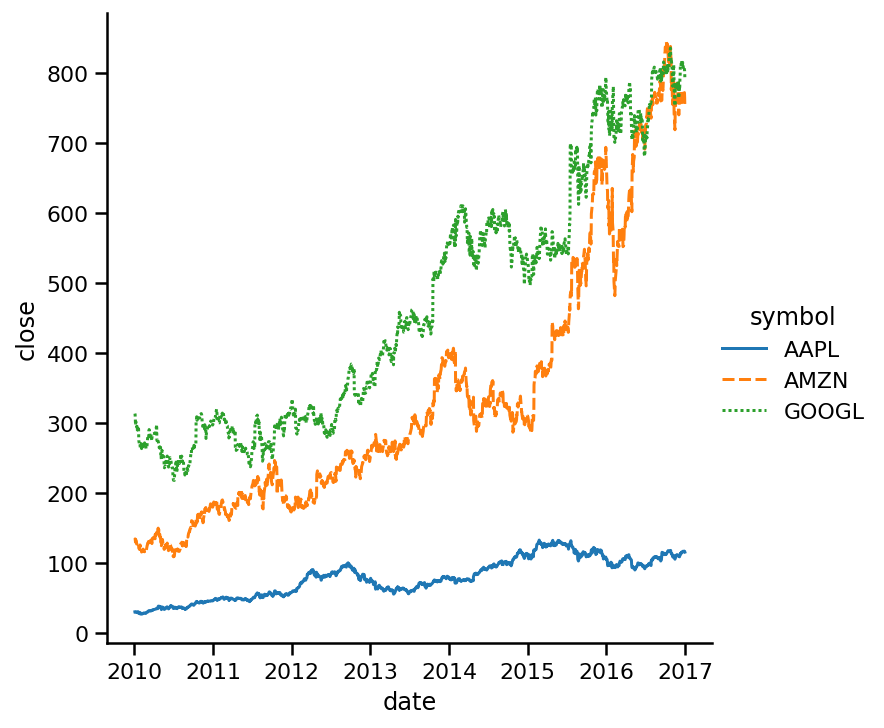
好吧,这可能不是不同线条风格的最佳例子,因为观察是针对每一天的,而且非常紧凑。让我们仅对2015-2016年期间进行子集划分,并绘制相同的线图:
am_ap_go_subset = am_ap_go.loc['2015-01-01':'2015-12-31']
sns.relplot(x=am_ap_go_subset.index,
y='close',
data=am_ap_go_subset,
kind='line',
hue='symbol',
style='symbol');
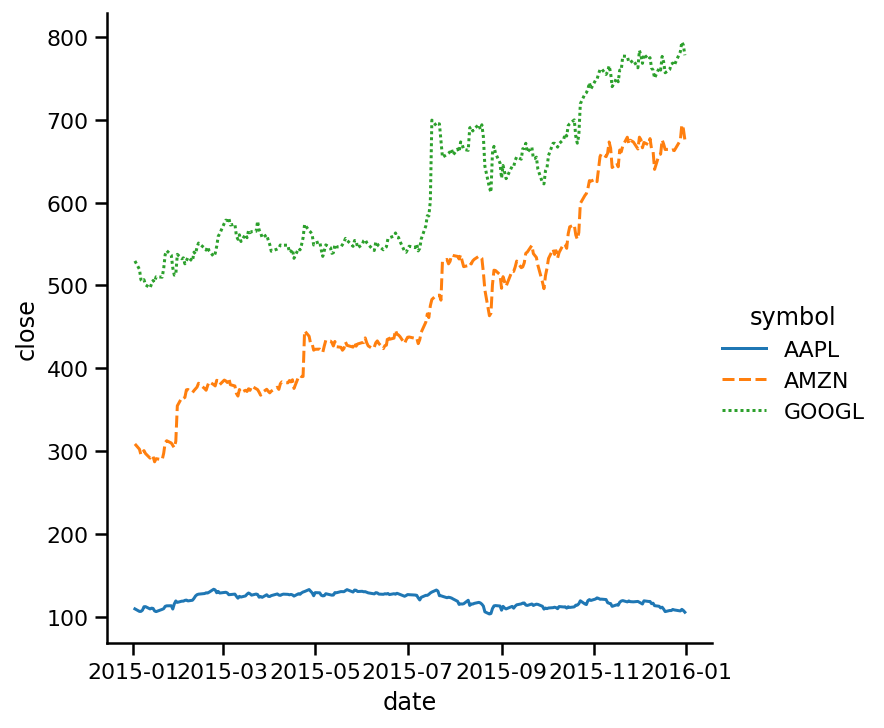
现在线条风格更清晰了。你可能会说,这好像没什么分别。但是当你有一个图表,它的线非常紧凑的话,这可能可以帮助你理解某些东西。
线图的点标记
当你有一个较小的数据集并且想要创建一个线图时,用点标记来标记每个数据点可能会很有用。对于我们较小的股票价格分布数据来说仍然是非常紧张的。所以,让我们用一个更小的时间段,来看看如何使用点标记:
smaller_subset = am_ap_go_subset.loc["2015-01-01":"2015-03-01"]
sns.relplot(x=smaller_subset.index,
y='close',
data=smaller_subset,
kind='line',
hue='symbol',
style='symbol',
markers=True)
plt.xticks(rotation=60);
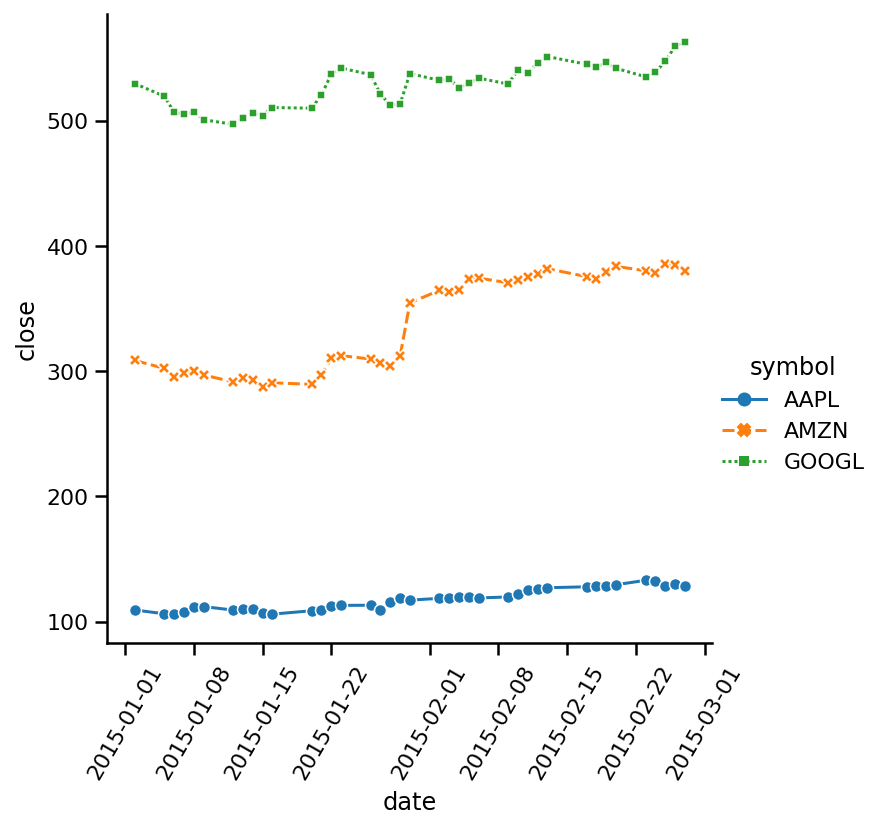
现在每行都有不同的标记。我们将markers参数设置为True以激活此功能。
线图置信区间
接下来,我们将探讨在SB中计算线图的置信区间。如果对一个点有多个观测值,则会自动添加置信区间。
在我们对这三家公司的数据中,每一天都有三个观察结果:一个是亚马逊,一个是谷歌,一个是苹果。当我们创建不带子组(不带色调参数)的线条图时,默认情况下,SB取这三个值的平均值:
sns.relplot(x=am_ap_go.index, y='close',
data=am_ap_go, kind='line');
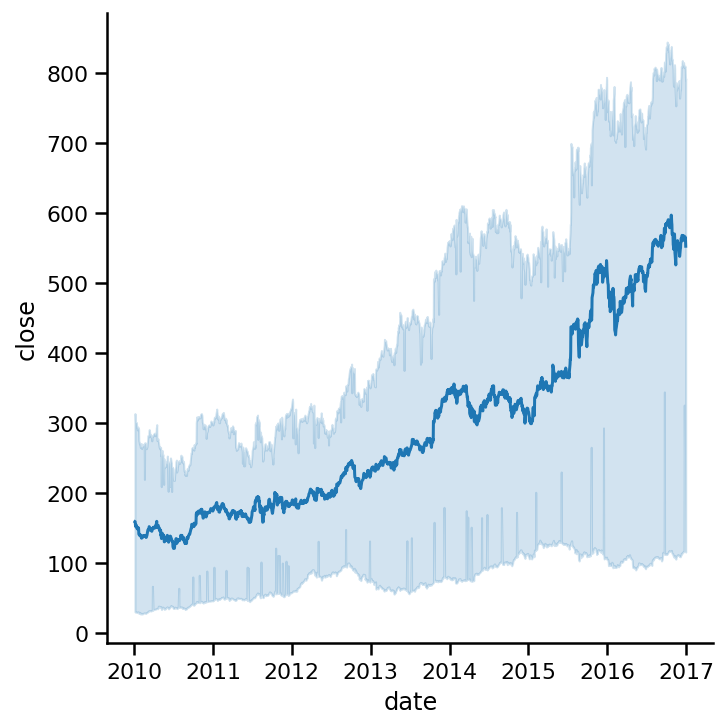
较暗的线表示这三家公司股价的平均值。阴影区域为95%置信区间。这是非常巨大的,因为我们的样本数据只有三家公司。阴影区意味着95%的人的平均值在这个区间内。它表明了我们数据的不确定性。
例如,2017年,人口平均数在100到800之间。置信区间的范围是巨大的。将ci参数设置为“None”可以关闭置信区间:
sns.relplot(x=am_ap_go.index,
y='close',
data=am_ap_go,
kind='line', ci=None);
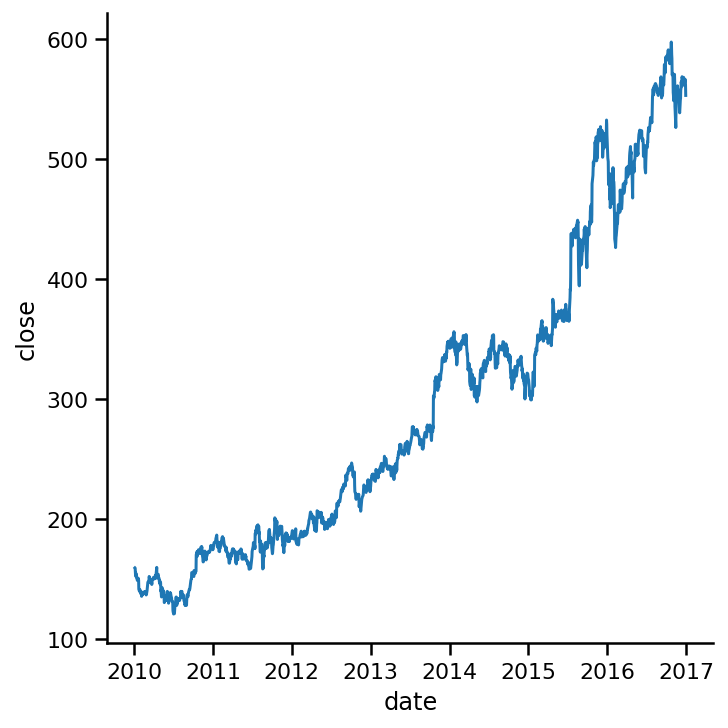
或者,如果需要,可以显示标准偏差而不是置信区间。将ci参数设置为sd:
sns.relplot(x=am_ap_go.index,
y='close',
data=am_ap_go,
kind='line',
ci='sd');
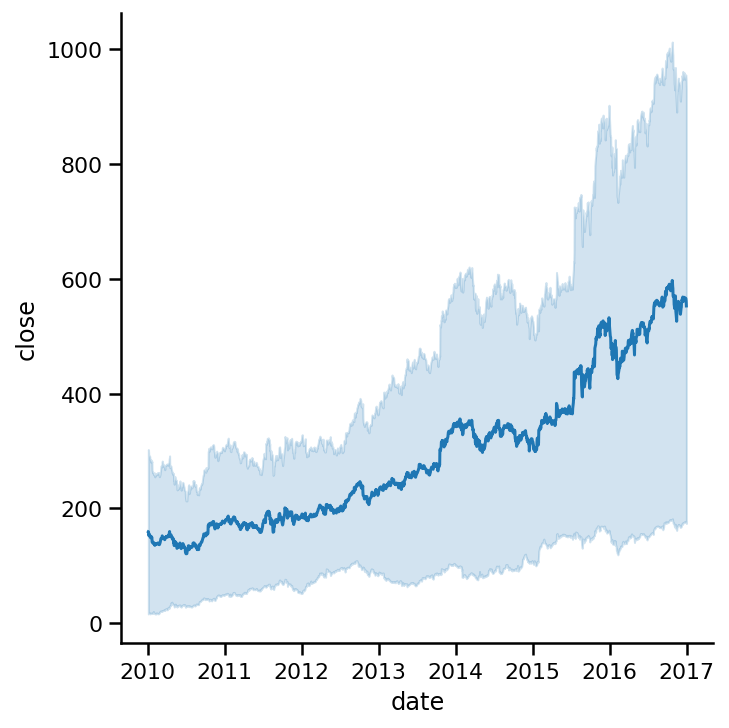
也许这些参数对于我们的示例数据不是很有用,但是当你处理大量真实数据时,它们将非常重要。
最后一点:如果要为线图创建子图,可以使用相同的col和row参数。
结论
最后,我们完成了Seaborn的关系图。线图和散点图是在数据海洋中发现洞察力和趋势的非常重要的视觉辅助工具。因此,掌握它们是很重要的。尽可能使用Seaborn来创建它们。
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


