背景
最近在做项目的时候,有一个场景需要进行分页查询某个分类下的商品信息,发现对这块不熟悉,故总结一下
01 表结构
CREATE TABLE `tb_goods` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`item_id` int(11) NOT NULL COMMENT '商品id',
`category_id` int(11) NOT NULL COMMENT '分类id',
`spu_id` varchar(30) NOT NULL COMMENT 'spu_id',
`sku_id` varchar(30) NOT NULL COMMENT 'sku_id',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`last_update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_uniq_item_id`(`item_id`),
UNIQUE KEY `idx_uniq_category_id_spu_id_sku_id`(`category_id`,`spu_id`,`sku_id`),
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品信息表';
插入数据
INSERT INTO `tb_goods` (`id`, `item_id`, `category_id`, `spu_id`, `sku_id`, `create_time`, `last_update_time`) VALUES (1, 1001, 106, '1', '1', '2023-08-08 15:03:31', '2023-08-08 15:07:47'), (2, 1002, 106, '2', '2', '2023-08-08 15:03:31', '2023-08-08 15:07:51'), (3, 1003, 106, '12', '21', '2023-08-08 15:03:31', '2023-08-08 15:07:53'), (4, 1004, 106, '13', '101', '2023-08-08 15:03:31', '2023-08-08 15:04:00'), (5, 1005, 106, '113', '131', '2023-08-08 15:03:31', '2023-08-08 15:04:00'), (6, 1006, 191, '173', '91', '2023-08-08 15:03:31', '2023-08-08 15:07:58'), (7, 1007, 106, '27', '97', '2023-08-08 15:03:31', '2023-08-08 15:04:00'), (8, 1008, 106, '46', '123', '2023-08-08 15:03:31', '2023-08-08 15:04:00'), (9, 1009, 106, '311', '1231', '2023-08-08 15:03:31', '2023-08-08 15:04:00'), (10, 1010, 106, '83', '81', '2023-08-08 15:03:31', '2023-08-08 15:04:00');
02 方案
2.1 使用 limit pageId,size
一开始的方案是使用 limit pageId,size pageId 表示开始的位置,size 表示分页的数量,将商品的分类放在 where 条件里,具体的 sql 如下
select * from tb_goods where category_id = 106 limit 1,4
explain 了一下,发现有用到索引,线上应该很快的

2.2 使用 id 作为条件的一部分
将 id 作为条件的一部分,每次直接从指定的位置开始扫描,扫描到指定的数量后截止
select * from tb_goods where category_id = 106 and id > 0 limit 4
同样 `explain` 试试,目前只用到了
idx_uniq_category_id_spu_id_sku_id 这个索引且数据量很小,看不出区别 通过这次查询的结果还发现了一个问题,
id 为 2 的数据不见了如下图所示,而在表里是有这条数据的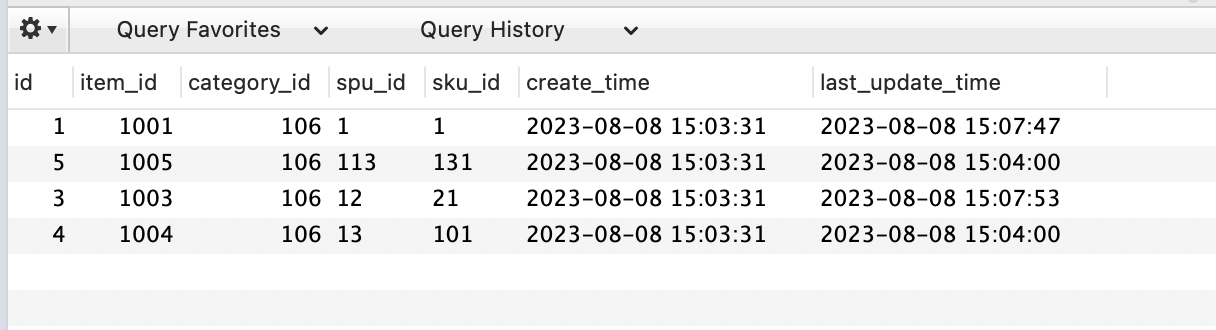
查询结果图
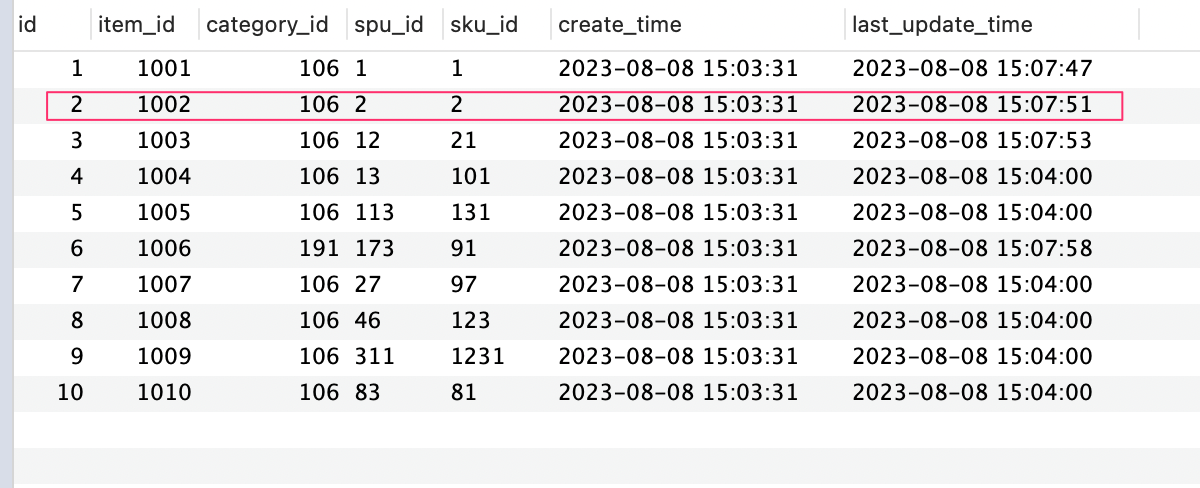
表数据图
这是什么原因导致数据丢失了呢?
查看
explain 中结果发现,这次查询用到的索引是 idx_uniq_category_id_spu_id_sku_id,而此索引
id 为 2 的列是排在后面的,将 limit 的数量调为 7,结果如下图所示: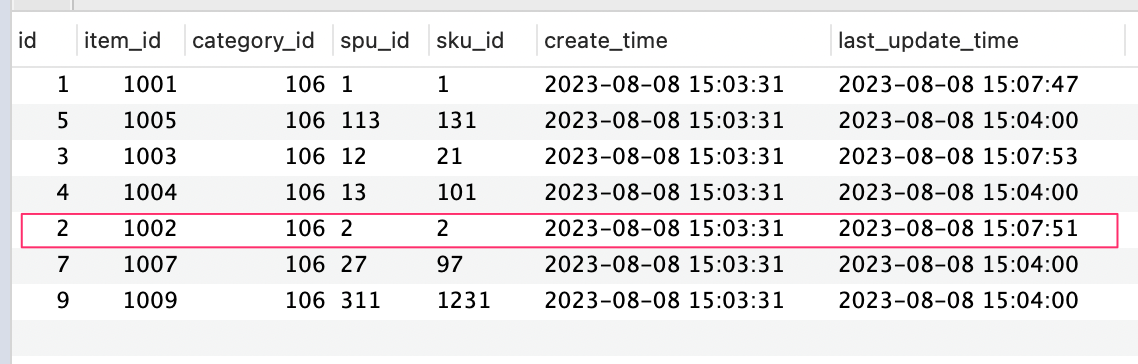
发现
id 为 2 的列刚好排在 id 为 4 的列后面,问题找到了 limit 的值不够大,导致部分列没有找到将
limit 的值设置大一点是不是就可以了?不行的,limit 是每次要进行查询的数量,业务方下次传入的起始位置是上一次的最大
id,这样就会导致 id 为 2 的数据丢失了。如何解决这个问题呢?
添加排序规则, 让
limit 每次返回的数据相当从一个已经排序好的数据集中取固定的数量,对于此需求,每次返回的是id,在排序规则中 添加 id 就是可以了select * from tb_goods where category_id = 106 and id > 0 order by id limit 4

从上图可以看到,在添加排序规则后
id 为 2 的列可以查询到了03 limit 配合 order by 使用的坑
在查阅资料的时候发现
在 mysql 5.6 版本以上,对于 limit 语法,`order by` 排序 带 limit 和不带 limit, order by 排序返回的排序后的列表可能是不同的,如果需要前后返回的数据一致,需要在 order by 中添加能够确定排序结果的列,比如
id3.1 重现 limit 配合 order by 使用 的问题
创建表
CREATE TABLE `ratings` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`category` int(11) NOT NULL COMMENT '分类id',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT='等级表';
插入数据
INSERT INTO `ratings` (`id`, `category`) VALUES (1, 1), (2, 3), (3, 2), (4, 2), (5, 1), (6, 2), (7, 3), (8, 3), (9, 2), (10, 1);
第一次查询不带
limit ,具体 sql 如下:select * from ratings order by category ;
查询结果如下:
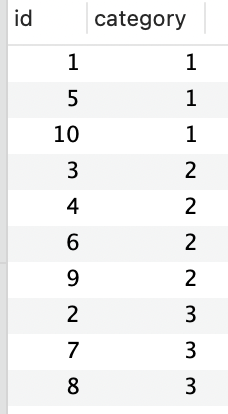
第二次查询带
limit ,具体 sql 如下:select * from ratings order by category limit 5;
查询结果如下:

观察上图可以发现,id 为 10 和 id 为 5 的列的顺序变了
3.2 原因
在MySQL 5.6的版本上,优化器在遇到order by limit语句的时候,做了一个优化,即使用了priority queue
使用 priority queue 的目的,就是在不能使用索引有序性的时候,如果要排序,并且使用了limit n,那么只需要在排序的过程中,保留n条记录即可, 因为 priority queue 使用了堆排序的排序方法,而堆排序是一个不稳定的排序方法,也就是相同的值可能排序出来的结果和读出来的数据顺序不一致
参考资料
内容来源于网络如有侵权请私信删除
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


