1. 服务级别帮助你定义客户满意的程度和标准,以便你在解决性能、可扩展性挑战等事情与开发内部工具之间做出时间权衡
2. 服务水平指标(SLI)
2.1. 如何衡量客户是否满意
3. 服务水平目标(SLO)
3.1. 为了确保客户满意,能允许SLI达到的最低限度是多少
3.2. 将特定的SLI视为健康服务的目标范围
3.2.1. 必须定义为给定时间范围内的一个具体值,以确保每个人都对SLO的含义保持一致的理解
3.2.2. 如果SLI的指标是服务正常运行的时间,那么在给定的时间范围内,运行时间达到几个9就是SLO
4. 服务水平协议(SLA)
4.1. 我同意的SLO会产生什么后果
4.1.1. SLA是可选的
4.2. 与一个或多个业务客户(付费客户,而非内部利益相关者)签订的协议中包含的SLO,如果未满足该SLA,将受到财务或其他处罚
4.3. 如果团队没有达到其承诺的SLO,则不应继续进行新特性的工作
5. 怎样才能让客户满意
5.1. 目标是定义确保客户满意的最低标准
5.2. 选择指标和目标的目的是随时使用客观指标评估团队是否能够利用新功能进行创新,或者稳定性是否有可能降至客户可接受的水平以下,因此需要更多的关注和资源
5.3. 承诺的“9”越多,就越难实现,团队为实现这一承诺所花费的工程时间也就越昂贵
5.4. 达到3个9的可用性
5.4.1. 一年中的3个9相当于8个多小时的停机时间
5.4.2. 转换到一周则只有10分钟
5.5. 999图
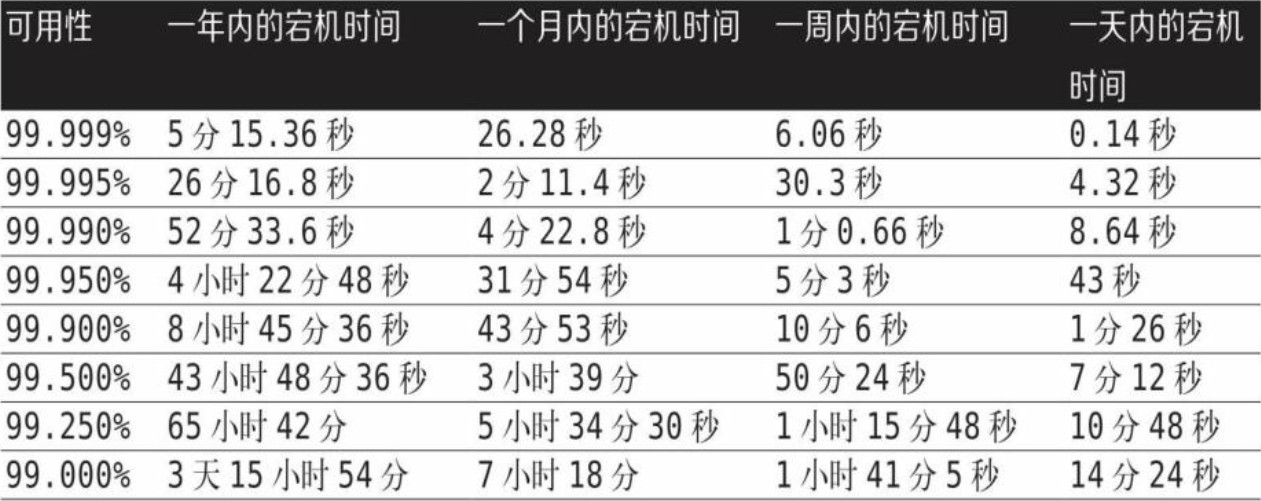
5.6. 工程时间是有限的资源
5.6.1. 选择SLO时必须注意不要过于追求完美
5.6.2. 将工程时间花在新功能上
5.6.3. 将时间花在可恢复性和修复问题上
5.7. 不是产品中的所有特性都需要这么多个9才能让客户满意
5.7.1. 随着产品特性集的增长,将会有不同的SLI和SLO,具体取决于特定功能的影响或其带来的收入
5.8. 区分不同用户的需求,以便可以为他们提供合理的SLI和SLO
5.8.1. 检测数据集何时成为不同用户的不同查询概要文件(query profile)的瓶颈,从而影响性能
6. 有效管理MySQL的一个关键点在于对数据库的健康状况进行良好的监控
7. 可用性
7.1. 能够无错误地响应客户的请求
7.1.1. 明确成功的响应
7.1.1.1. 200响应代码
7.1.2. 成功接受请求并承诺异步完成相关工作的响应
7.1.2.1. 202已接受
7.2. 没有要求必须做到100%,因为我们在一个不可避免失败的世界中运作
7.3. 不应该用一个指标来确定所有要求
7.4. 如果一个供应商的竞争优势是分析MySQL性能的特定任务,那么付费是可以给组织带来回报的
7.4.1. SolarWinds数据库性能管理工具
7.5. Percona监控和管理工具是一个成熟的开源选项
7.5.1. PMM
7.5.2. 仪表盘的组织是由Percona社区在监控MySQL性能方面的长期经验指导的
7.6. 将数据库慢查询日志和MySQL PerformanceSchema的输出信息发送到一个集中的位置,然后可以使用像pt-query-digest(Percona Toolkit包中的工具)这样的成熟工具来分析日志,并更深入地了解数据库实例在哪些方面花费了时间
7.7. 在性能倒退的情况下,花费生产之外的精力去调查“发生了什么”远比试图重新创建一个模拟更大代码路径的基准测试套件要具体得多
7.8. 可用性转换为数据库架构的SLI和SLO时
7.8.1. 在处理不可避免的灾难性故障时,哪些功能是不可协商的,哪些功能是“最好拥有的”
7.8.2. 将哪些类型的失败定义为“灾难性的”
7.8.3. “降级功能”是什么样子的
7.8.4. 给定一组可能的故障场景
7.9. 验证可用性的首选方法是从客户端或远程端点来进行访问
7.10. MySQL中有一个Threads_running状态计数器可以作为可用性问题的关键指标
7.11. Thread_running与max_connections的差距,将此差距作为另一个数据点,以检查正在进行的工作是否过载
8. 监控查询延迟
8.1. MySQL引入了许多长期需要的增强功能来跟踪查询运行所需的时间
9. 监控报错
9.1. MySQL客户端在访问运行着的服务的过程中出现错误并不一定意味着服务遭到破坏
9.2. 间歇性错误,通过简单地重试失败的查询就可以解决这些错误
9.3. 错误发生的频率可能是潜在问题的关键指标
9.3.1. 如果报错的频率加快,则是将要出现问题的迹象
9.4. Lock wait timeout
9.4.1. 如果客户端中该报错急剧增加,可能是主节点上的行级锁争用在不断扩大,即事务不断重试但仍然失败
9.4.2. 可能是无法写入的前兆
9.5. Aborted connections
9.5.1. 如果客户端中该报错突然激增,可能表明客户端和数据库实例之间的某个访问层出现了问题
9.5.2. 跟踪这一点会导致大量客户端重试,这会消耗资源
9.6. too many connections
9.7. 操作系统级别的“cannot create new thread
9.8. 应用程序创建和打开的连接数超过了数据库服务器配置中允许的连接数,这个限制可能来自服务器的max_connections变量或者MySQL进程被允许打开的线程数
10. 主动监控
10.1. 不要将所有精力都集中在显示事故发生的指标上,而是应花一些时间来监控可以帮助预防事故的事情
10.2. 磁盘空间使用率增长
10.2.1. 设置多个阈值,其中较低的警告可以设置为仅在工作时间触发,而较高的、更严重的值则作为对非工作时间随叫随到的告警
10.3. 连接数增长
10.3.1. 流量不断增长时,数据库服务器可以支持有限的连接池,这被配置为服务器参数max_connections
10.3.2. 应用程序层打开了大量未使用的连接,导致产生了毫无理由的连接过多的风险
10.3.2.1. 连接的线程数(threads_connected)很高,但运行的线程数(threads_running)仍然很低
10.3.3. 应用程序层正在积极地使用大量的连接,并有导致数据库过载的风险
10.3.3.1. 连接的线程数(threads_connected)和运行的线程数(threads_running)都处于高值并持续增加
10.4. 复制延迟
10.4.1. 能够被视为一种重要的SLI指标,它能引起异常事故
10.4.2. 复制延迟可能会使数据看起来不一致
10.4.3. 即使复制延迟从未达到影响客户体验的程度,如果偶然出现,这仍然是一个比较明显的迹象,说明当前配置下源节点写入设备的性能要强于副本节点,这可能预示系统写容量出现不足
10.5. I/O使用率
10.5.1. “尽可能多地在内存中工作,因为这样更快”
10.5.1.1. 数据库工程师不断努力的目标之一
10.5.2. 不要从磁盘读取太多的数据,否则查询就只能等待那些宝贵的I/O周期
10.5.3. iostat这样的工具可以监控I/O等待
10.5.4. 如果数据库服务器有很多线程位于IOwait状态,则需要监控发出告警,这表示它们正在队列中等待某些磁盘资源可用
10.6. 自增键空间
10.6.1. 自动递增主键在默认情况下被创建为有符号整数,并且可能会耗尽键空间
10.6.2. 为所有使用自增主键的表监控剩余整数空间是一个简单的操作,但几乎可以肯定的一点是,它会在将来为你避免一些重大事故,因为可以提前预测需要更大的键空间
10.6.3. 使用了PMM及其Prometheus导出器(exporter),那么已经自带监控方法,你需要做的就是开启collect.auto_increment.columns设置
10.7. 创建备份/恢复时间
10.7.1. 监控将备份从文件恢复到运行的数据库(该数据库自创建备份以来还一直在复制所有更改)需要多长时间
10.7.2. 功能分片(Functional sharding)是指将服务于特定业务功能的特定表分割到一个专用的集群中,以便单独管理该数据集的正常运行时间、性能甚至访问控制
10.7.3. 水平分片(Horizontal sharding)是指当数据集的大小超过了可以在单个集群中可靠地提供服务的规模时,将它拆分为多个集群,并从多个节点提供数据,这依赖于某种查找机制来定位所需的数据子集
11. 长期性能
11.1. 业务节奏
11.1.1. 业务节奏可能意味着峰值流量时间比“平均值”大几个数量级,如果数据库基础架构没有准备好,将产生很多不良结果
11.1.2. 业务周期可能会因业务所满足的客户需求而大不相同
11.1.3. 了解业务周期以及对业务收入、声誉的影响至关重要
11.2. 业务的长期规划
11.2.1. 为未来的容量做规划
11.2.2. 预见何时需要重大改进,何时增量修改就够了
11.2.3. 为运行基础架构增加的成本做规划
11.3. 提高透明度,重点是跟踪结果而不是输出
11.4. 对平均值说不
11.4.1. 平均值的数据点图很可能会让你产生错误的安全感
11.5. 与百分位为友
11.5.1. 百分位依赖于在给定的时间范围内对数据点进行排序,并根据目标百分位移除最高值的数据点(例如,如果要寻找95百分位,则移除最顶端的5%)
11.6. 使用SLO来指导整体架构
11.6.1. 在业务增长的同时保持良好一致的客户体验不是一件容易的事
11.6.2. 随着业务规模的增长,保持相同的SLO都将变得越来越困难,更不用说制定更雄心勃勃的SLO了
11.6.3. 你希望实现的SLO越严格,工作成本就越高,因为每秒的数据库事务数峰值或数据量也会呈数量级的方式增长
内容来源于网络如有侵权请私信删除
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


