Story background
回望2018年12月,这也许是程序员们日夜不得安宁的日子,皆因各种前线的系统使用者都需要冲业绩等原因,往往在这个时候会向系统同时写入海量的数据,当我们的应用或者数据库服务器反应不过来的时候,就会产生各种各样诡异的问题,诸如表现出来就是系统变得巨卡无比,无法使用,或者周期性卡顿,令人发指,用户轻则问候系统全家,重则心脏病发。总而言之每天都脑壳疼!归根到底是我们的应用服务器或数据库服务器因为扛不住流量造成的系统BUG问题暴露,诸如OOM等,呈现出机器的三高,这里说的三高并不是高血脂、高血压、高血糖。而是高CPU,高内存,高NETWORK/IO!(本文只讲述应用服务器,暂不讲述数据库服务器造成的问题)PS:为什么不做压测?石丽不允许呀
Begin Transaction
而小鲁班恰好是参与这个问题系统的开发者之一,这天小鲁班起得比较晚,到了公司都快10点了,不过没所谓,最近都没什么新需求要做,小鲁班打开电脑正准备一天的摸鱼旅途。忽然之间门口传来一阵急促的脚步声,小鲁班回眸一看,噢原来是项目经理提着大刀杀来了,询问之原来前线系统又挂了,这些日子里看到系统天天被投诉,其实也责无旁贷,小鲁班心里想系统挂了不是运维的事情么,别鲁班抓老鼠了!不过心里又想TM技术运维好像删库跑路了。没办法,小鲁班临危受命硬着头皮上吧。
回顾一下问题系统的架构,是典型的应用集群服务器。理论上来说,有做应用集群的话,只要有一个应用服务器没死,一个数据库服务器没死,系统还是可以正常运行的,只是处理请求的平均速度有所降低。不管怎么说,只要有一台应用或数据库挂了,基本上都是因为代码存在bug,导致三高,使得机器无法发挥其本来的性能,如果未能及时发现处理,其他集群的服务器机器也很快被同一个BUG拖垮,例如死锁,最终导致没有一台机器能提供服务,集群系统最终走向瘫痪,换句通俗的话来说就是系统bug的存在使得机器生活不能自理,所以更不能向外提供服务。
Try
小鲁班尽管是科班出生的,但对于此类系统线上问题,一时之间还真摸不着头脑,无奈之下只好请教小鲁班的表哥鲁班大师,要知道,鲁班大师可是有着一套教科书式的解决方案,并且可以通过一些途径来定位并解决系统bug,特别是代码原因产生的问题,从根本上杜绝问题,而不是每次出现问题都重启应用服务器就算了,因为知道bug一天不除,系统永远都可能会随时随地go die。
于是小鲁班立马拿起大哥大手机向表哥发了个红包,没想到这TM就把他表哥鲁班大师炸了出来,并取得了
解决方案三部曲
1.查看应用服务器指标(CPU,内存,NETWORK,IO),并保留现场所有线索日志,然后进行问题归类和分析,最后重启或回滚应用,以达到先恢复服务,后解决BUG的目的
2.通过分析排查工具或命令对1步骤中取得的线索日志进行推测分析,或许能定位到bug代码部分,或许能发现JVM某些参数不合理
3.修改bug代码或调节JVM参数,达到修复bug的目的,晚上重新发布应用
不妨画一张图

那么具体是怎么操作的呢
1.首先当然是查看机器的指标啦,Linux则是使用TOP和JPS命令列出进程以及各个进程所占用的CPU和内存使用情况。而windows则是直接打开任务管理器就可以看到,但无论什么操作系统的服务器,我们都可以通过JConsole这个JDK自带的可视化工具远程连接来看到内存的使用趋势,这样一下来,我们就能大致确定是否因为内存出现问题了,例如下图出现的CPU满的问题,但是我们无法知道是什么原因导致的问题。
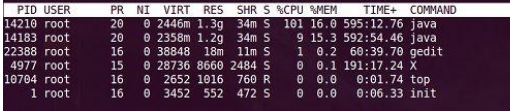
2.要知道是什么原因导致的,我们得要知道目前JVM是用什么垃圾回收器,毕竟有些回收器是CPU敏感有些则不是,通过命令-XX:+PrintFlagsFinal 打印JVM所有参数
或者-XX:+PrintCommandLineFlags通过打印被修改过的参数都可以知道,这个可以帮助我们分析是发生内存问题的原因。

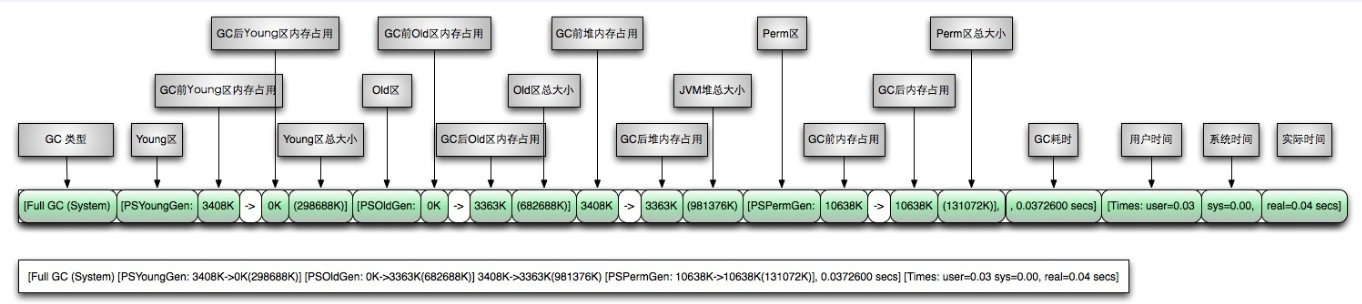
3.然后我们得打印GC日志,通过日志分析,其实可以发现很多线索,比如通过GC发生的次数,来判断堆的大小是否是合理的范围,通过发生GC后,回收的对象容量多少来判断是否存在内存泄漏嫌疑,特别是FGC,系统卡顿是否与STW有关等等
- -XX:+PrintGCTimeStamps
- -XX:+PrintGCDetails
- -Xloggc:/home/administrator/zqs/gc.log
那么日志怎么看呢,如图吧
4.假如发生了内存问题,这个时候需要通过打印内存使用量来定位问题点Jstar
实时查看gc的状况,通过jstat -gcutil 可以查看new区、old区等堆空间的内存使用详情,以及gc发生的次数和时间
执行:cd $JAVA_HOME/bin中执行jstat,注意jstat后一定要跟参数。具体命令行:jstat -gcutil 'java进程PID' 1000

如图所示,发现Eden区、Old区都满了,此时新创建的对象无法存放,晋升到Old区的对象也无法存放,所以系统持续出现Full GC了。
5.如果看不到哪里出问题了,需要把内存镜像导出,然后用专业的工具去分享镜像如MAT
当然了,我们也可以设置当发生OOM的时候,自动导出进程镜像
- -XX:+HeapDumpOnOutOfMemoryError
- -XX:HeapDumpPath=/home/administrator/zqs/oom.hprof
把DUMP文件导入MAT会非常直观的展现内存泄漏的可疑点,可以直接看到某个线程占用了大量的内存,找到某个对象,常见的都是集合对象被GC ROOT指向等一直不能被回收

catch
当然以上是内存出现的问题,但是如果是CUP高出现的问题,会比较好搞一些,因为线程是运行在CPU上的,而线程却可以通过分析栈信息获取,而我们写的方法不也是运行到栈上的吗
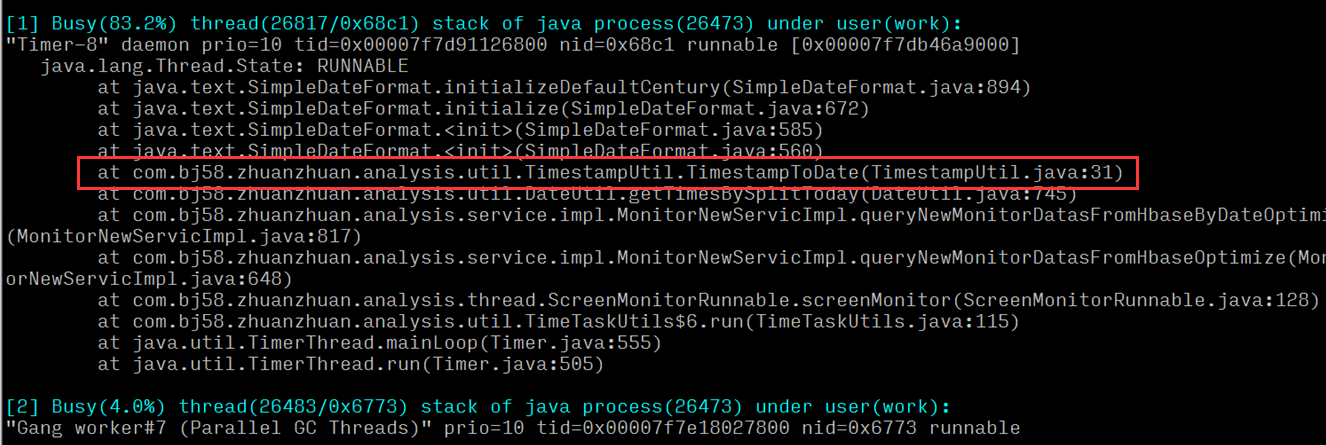
可使用top -H查看线程的cpu消耗状况,这里有可能会看到有个别线程是cpu消耗的主体,这种情况通常会比较好解决,可根据top看到的线程id进行十六进制的转换,用转换出来的值和jstack出来的java线程堆栈的nid=0x[十六进制的线程id]进行关联,即可看到此线程到底在做什么动作,这个时候需要进一步的去排查到底是什么原因造成的,例如有可能是正则计算,有可能是很深的递归或循环,也有可能是错误的在并发场景使用HashMap等。
1.找到最耗CPU资源的java线程TID执行命令:ps H -eo user,pid,ppid,tid,time,%cpu,cmd | grep java | sort -k6 -nr |head -1
2.将找到的线程TID进行十六进制的转换
3.通过命令导出堆栈文件:jstack javapid > jstack.log,根据上一步得到的线程TID,搜索堆栈文件,即可看到此线程到底在做什么动作。如对像锁互锁等,业务逻辑存在计算的死循环等
我们可以得到类似一张这样的图,百度找的,可以定位到某个方法是否存在逻辑漏洞
当然还可以用可视化工具jvisualvm,直接监控进程和线程,并且可以自动分析出一些明显的BUG
End Transaction
小结
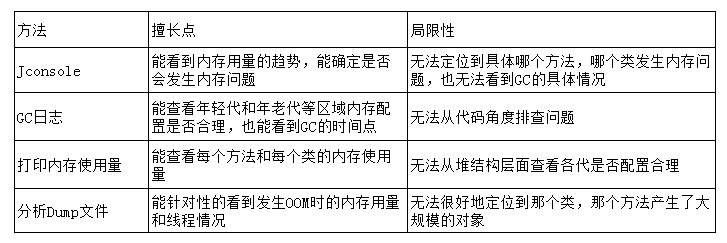
系统突然挂了,怎么排查问题,首先得确定是内存出了问题,那出现内存问题该怎样排查,对于这个问题,经常会听到一些不全面的做法,那就是只通过一种方式来查问题。例如只通过Dump文件来查,或者只通过 Jconsole来查等等其实回答都对,但都不全面。例如,医生在诊断病情时,很多情況下不会只相据B超单或验血单来下结论,他们往往会根据多张化验结果来综合判断。诊断内存问题也应该这样。下面给出了各种方法的擅长点和同限性。
最后总结一波:
1.通过JConose确认发生内存问题
2.在写有可能导致内存问题的代码时候,记录日志,并打印当前内存使用量,用这些信息和GC日志来综合判断
3.通过Dump文件重现OOM的内存镜像 | 如果是CPU问题,可以考虑分析线程DUMP
4.找到问题代码修改
- 还没有人评论,欢迎说说您的想法!
 客服
客服


