摘要
将2D大核的成功推广到3D感知具有挑战性,因为:
- 1.处理3D数据的三次增加的开销;
- 2. 数据的稀缺性和稀缺性给优化带来了困难。
以前的工作通过引入块共享权重,已经迈出了将内核大小从3 × 3 × 3尺度到7×7×7的第一步。但是,为了减少块内的特征变化,它只使用了适度的块大小,并没有获得像21 × 21 × 21这样更大的核。为了解决这一问题,我们提出了一种新的方法,称为LinK,以一种类似卷积的方式实现更大范围的感知接受域,有两个核心设计。第一种方法是用线性核生成器替代静态核矩阵,该生成器只自适应地为非空体素提供权值。第二种方法是在重叠块中重用预先计算的聚合结果,以降低计算复杂度。该方法成功地使每个体素在21 × 21 × 21的范围内感知上下文。在3D目标检测和三维语义分割两个基本感知任务上的大量实验证明了该方法的有效性。值得注意的是,我们在nuScenes (LiDAR track)的3D检测基准的公共排行榜上排名第一,这只是简单地将LinK-based的backbone整合到基本检测器CenterPoint中。我们还将强分割基线的mIoU在SemanticKITTI测试集中提高了2.7%。代码可以在https://github.com/MCG-NJU/LinK上找到。
简介
有一个共识,一个大的感受野对许多下游的视觉任务有积极的贡献。例如,Transformer[2,3]从自注意的全局关系中获益良多,成为分类[2]、分割[4]、检测[5]的领先课题。然而,自注意力并不是通往广阔感受野的唯一途径。之前的工作,如RepLKNet[6]和SLaK[7],研究了通过大型卷积核获得大范围信息的潜力。它们与基于Transformer的方法取得了相似的结果。考虑到卷积算子对现有芯片架构更加友好,大的卷积核方法在实际应用中是有效的。这在3D感知中提出了一个直接的问题:大的卷积核的范式能否推广到3D任务中?
答案是肯定的。LargeKernel3D[1]迈出了第一步,成功地实现了更好的分割和检测指标。时间和空间的消耗是扩展过程中的核心问题,因为它们在3D任务中呈立方增长。LargeKernel3D[1]引入空间共享卷积核,将三维卷积核尺度扩大到7×7×7,限制参数量的快速增长。然而,与2D版相比,后者已经开发了庞大的31×31[6]甚至51×51 [7], 7×7×7似乎还不够大,因此只能受益于有限的上下文。至少有两个原因阻碍了它的尺寸扩展:第一,虽然参数数量在控制之下,但每个体素的总操作量仍在立方级增加;其次,其外部部分可以共享block-wise权重的假设太强而不能在较大的块中良好地工作。因此,如何有效、高效地扩大三维核尺寸仍然是一个具有挑战性的问题。
为了处理这些问题,我们提出了一种名为LinK的新方法,以类似卷积的方式实现更大范围的感知。该方法由两个核心设计组成。第一种方法是用线性核生成模块替换静态核权值,以便仅为那些非空区域提供权值,因为3D输入非常稀疏。同时,该模块是分层共享的,这避免了分配给空白空间的一些权重在一次迭代中未被优化的情况。第二种方法是在重叠的块中重用预先计算的聚合结果,这使得计算复杂度与卷积核大小无关。换句话说,我们可以基于提议的LinK实现任意大小的内核,而开销是一致的。本文方法与其他方法的简单比较如图1所示。

图1。比较标准卷积核、LargeKernel3D的[1]块共享卷积核和来自生成器的LinK卷积核。LinK没有存储密集的核矩阵,而是根据输入数据在线生成稀疏核。可学习参数的数量不会随着内核大小的增加而增加,这使得更大的内核可以按比例增加。
在3D检测和语义分割任务的公共基准上的大量实验证明了LinK的有效性。值得注意的是,我们在著名的3D检测排行榜nuScenes (LiDAR track)[8]上获得了第一名,只需用基于link的骨干取代经典检测方法的骨干。对于分割任务,在SemanticKITTI测试split[9]中,我们将强基线的mIoU提高了2.7%。我们将在下面几节详细介绍。
相关工作
略
方法
本节介绍我们方法的所有设计。我们首先从两个背景来阐明3.1节中我们工作的创新之处。然后,在第3.2节中提供了详细的程序。最后,我们将在3.3节中展示如何将提出的主干融合到两个基本的3D感知任务中:目标检测和语义分割。
3.1 背景
3.1.1 三维稀疏卷积入门
基于卷积的方法在预先指定的范围内聚合加权影响。权值由卷积中心的局部相对位置确定。公式1为三维卷积算子的一般处理过程[14,15]。
$$g_p=sumlimits_{ninmathbb{N}}w_ncdot f_{p+n},(1)$$
其中$p$是卷积中心。$mathbb{N}$表示指定范围内的非空邻居。$f_{ast}$和$g_{ast}$分别是输入和输出特征。$w_n$为相对位置$n$对应的核。与二维图像不同,激光雷达数据具有空间稀疏性。这意味着分配给空体素的核将不会参与到卷积计算中,使得它们在反传时不能被更新。这减慢了优化过程。同时,不管输入是什么,每个位置的内核都必须为潜在的调用而存储。这将导致大型3D内核中的参数数量呈立方倍增长。例如,对于一个内核大小为$21^3$,$C_{in}=32,C_{out}=64$的单个卷积层,有超过18M的可学参数在等待调用,尽管在推理过程中它们中的大多数将是空闲的。
3.1.2 Push-Pull策略介绍
卷积运算的核心功能是引入空间相互作用。当卷积窗口在feature map上滑动时,该窗口所覆盖的位置将被kernel计算。重叠区域重复参与计算,引入冗余。针对点云任务中的这一问题,APP-Net提出了一种所谓的APP算子,将空间交互分解为三个步骤:
- 1. 推: $gammaleft(p_{i} rightarrowright. proxy)$,将 $ p_{i}$ 的特征推入各簇 (cluster) 共享的代理(proxy) 中;
- 2. 聚合:在代理中融合簇的信息;
- 3. 拉: $lambdaleft(operatorname{prox} y rightarrow p_{j}right) $,将每个点 $ p_{j}$ 从辅助代理中拉出特征。
3.2 三维线性核
根据3.1.1节,我们可以得出这样的结论:存储每个离散位置的内核值既不节约内存,也不利于三维大型核的优化过程。因此,我们提出采用神经网络模块$w(n)$在线生成核,而不是存储静态核值$w_n$。这使得可学习参数的数量不会随着核大小的增加而增加。此外,空体素不会减慢优化过程。
虽然解决了存储成本和优化问题,但在3D大型内核中采用生成模块仍存在挑战。卷积核和特征图之间的计算引入了立方次增加的开销。为了解决这个问题,我们在以下几个部分提供了两个关键的设计:
- 线性核生成器(Linear Kernel Generator)
- 基于块的聚合(Block Based Aggregation)
整个过程如图2所示:
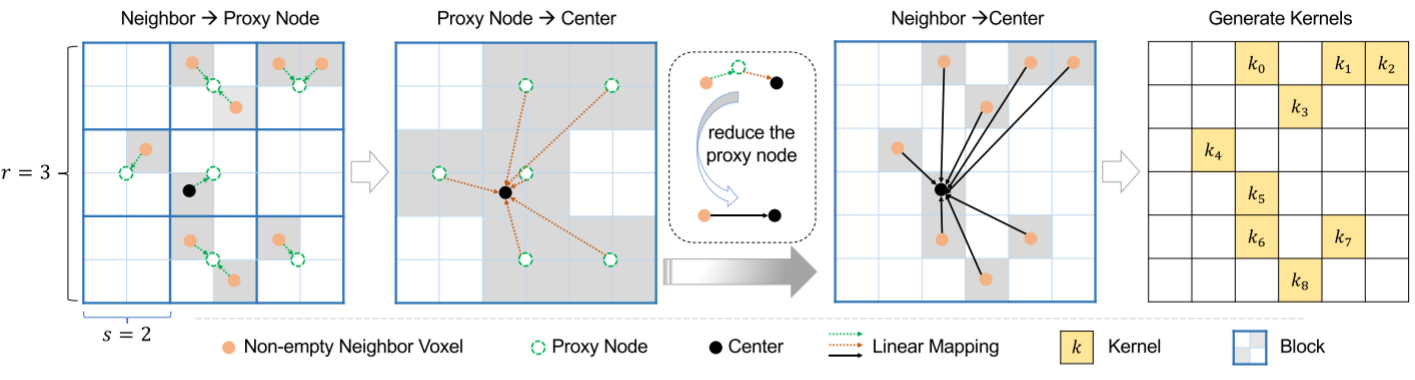
图2。 LinK的过程。 输入被划分成不重叠的块(块大小为$s^3$)。 每个非空体素将其特征推送到block-wise proxy,然后中心体素只从neighbor proxies中提取特征(邻居范围为$r^3$)。 push和pull进程是以一种可简化的方式驱动的(详细信息见3.2.2),这样block-wise proxy就支持对每个潜在调用的重用。 得到的矩阵作为卷积核来对邻居进行加权。
3.2.1 线性核生成器
更大的内核提取输入信息的代价是对每个区域进行更多的处理。我们致力于在重叠区域中寻找可重用的公共部件,以减少开销。
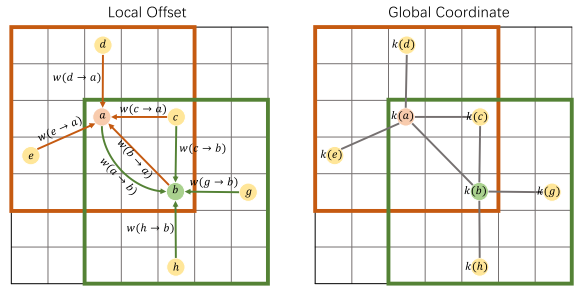
图3。局部偏移建模与全局坐标建模的比较。$w(x−y)$通过建模$x$到$y$的偏移量主动度量$x$如何影响$y$。$k(x)$使用$x$的全局坐标生成$x$的核。当$y$查询邻居特征时,$x$和$y$之间的关系可以由$k(x)$和$k(y)$组成。
我们通过一个toy示例开始分析。给定两个块$A={a,b,c,d,e}$和$B={a,b,c,g,h}$。其中每个元素代表一个体素,重叠区域为$O = {a, b, c}$,如图3所示。我们尝试使用局部偏移将A的特征聚合为a, B的特征聚合为b,重叠部分的影响如下:
$$left{begin{array}{l}{f_{Orightarrow a}=w(a-a)f_{a}+w(b-a)f_{b}+w(c-a)f_{b}}\ {f_{Orightarrow b}=w(a-b)f_{a}+w(b-b)f_{b}+w(c-b)f_{c}}\ end{array}right.$$
由上式公式(3)可知,O中的每个元素对a和b的贡献使用了不同的偏移量,所以我们不能通过建模局部偏移量来重用重叠的聚合结果。
考虑到每个体素的全局坐标是固定且唯一的,我们考虑将局部偏移分解为全局坐标的组合。具体来说,我们首先定义一个新的kernel生成器,如下所示:
$$k(x)=Psi(sigma(x)),(4)$$
其中$sigma(x)=W times x$是一个线性映射函数,$Winmathbb{R}^{C_{in}times3}$。$Psi(*)$是一个激活函数。受APP-Net[26]的启发,我们采用了三角函数作为激活函数,例如:
$${k^{(0)}(x)=cos(sigma(x)),k^{(1)}(x)=sin(sigma(x))},(5)$$
由和积公式得到如下关系式:
$$k^{(0)}(x-y)=cos(sigma(x))cdotcos(sigma(y))+sin(sigma(x))sin(sigma(y))=k^{(0)}(x)k^{(1)}(y)+k^{(1)}(x)k^{(0)}(y),(6)$$
其中$x$和$y$是全局坐标,$x−y$是局部偏移。公式(6)将局部偏移量分解为全局位置。
然后对重叠区域计算以下两个辅助聚合:
$$left{begin{array}{l}f_O^{(0)}=k^{(0)}(a)cdot f_a+k^{(0)}(b)cdot f_b+k^{(0)}(c)cdot f_c,\ f_O^{(1)}=k^{(1)}(a)cdot f_a+k^{(1)}(b)cdot f_b+k^{(1)}(c)cdot f_c.end{array}right.quad(7)$$
$f_O^{(0)}$和$f_O^{(1)}$在A和B之间可重用,因为它们是基于固定的全局位置计算的。为了得到中心体素a重叠区域的最终聚合,我们通过以下方式利用辅助聚合:
$$f_{Oto a}=f_O^{(0)}cdot k^{(0)}(a)+f_O^{(1)}cdot k^{(1)}(a)=sumlimits_{pinmathcal{Q}}k^{(0)}(p-a)cdot f_{a+(p-a)}cdot(8)$$
结合公式(7)和公式(6),$f_{Oto a}$对局部偏移量进行建模。公式(8)是公式(1)中卷积算子的一个实例(使用$k^{(0)}(ast )$替换$w(ast )$)。为了强调核心部分的线性映射,我们将此过程称为Linear Kernel Generator。
3.2.2 基于块的聚合
上面的线性核可以重用重叠的区域。然后又出现了一个新的问题:如何设置重叠区域?受ViT[2]的激励,我们将整个输入空间划分为几个非重叠块。具体来说,对于输入场景点云$Pinmathbb{Z}^{Ntimes3}$,我们将每个体素$p$的坐标使用块大小$s$来量化,并计算相应的哈希编码$l$,如下所示:
$$l=Hash(lfloorfrac{p(0)}{s}rfloor,lfloorfrac{p(1)}{s}rfloor,lfloorfrac{p(2)}{s}rfloor).quad(9)$$
拥有相同哈希码的体素将被分组到相同的块中。块集合表示为$B = {B_0, B_1,cdots, B_m}$。根据公式(7),我们进行了如下的block-wise proxy聚合来实现重用:
$$left{begin{array}{l}f_{B_i}^{(0)}=sum_{xin B_i}k^{(0)}(x)cdot f_x,\ f_{B_i}^{(1)}=sum_{xin B_i}k^{(1)}(x)cdot f_x.end{array}right.quad(10)$$
&begin{cases}pmb{g}_{mathbb{B}_i}^{(0)}=sum_{jinmathbb{B}_i}f_{B_j}^{(0)},\ pmb{g}_{mathbb{B}}^{(1)}=sum_{jinmathbb{B}_i}f_{B_j}^{(1)}.end{cases}&&& (11) \
end{aligned}$$
3.2.3 内核生成的增强
为了增强表示,从不同的角度提出了两种简单的策略来改进内核生成。为了增强模型的能力,我们在基于cos和基于sin的激活模型的基础上,引入了两种改进方法:通道级的可学习参数$alpha$来调整频率,以及$text{单位项}+x$来保留空间信息。
增强的激活函数如下:
$$Psi'(x)=Psi(alphacdot x)+xquad(13)$$
分组共享权重。通过基于块的聚合,有效的感受野得到了显著的扩大。由于每个体素只对核的生成做出一次贡献,大的核范围使得学习每个偏移量的核很困难。为方便优化,我们采用分组共享策略。具体来说,对于$C_{i n}$个输入通道,我们只生成$frac{C_{i n}}{#g r o u p s}$通道的核,并让每个$#groups$通道共享相同的权重。因此,每个权重将有更多的机会被更新。我们在实践中使用$#groups = 2$。
3.3 网络结构
3.3.1 LinK模块
由于LinK以逐通道的方式聚合空间信息,我们在将输入特征发送给LinK算子之前对其进行$1times1times1$卷积,以引入通道混合[53,54]。同时,按照之前的做法[1,6],我们添加了一个并行的$3times3times3$卷积分支,以保留详细的结构。这个操作也稳定了优化过程。得到的架构如图5所示。与LargeKernel3D[1]中的选择不同,我们没有为$3times3times3$分支采用$dilation > 1$。我们将BatchNormalization[55]替换为LayerNormalization[56],以加强这些信息通道。
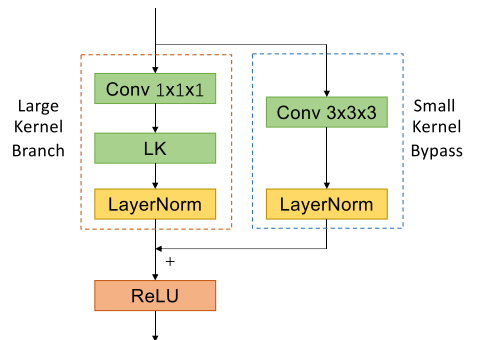
图5。LinK模块的结构。LK分支负责较大的内核大小,而Conv3 × 3 × 3旁路弥补了微妙的局部结构。
3.3.2 Applications in Perception Tasks
LinK被纳入两个基本的感知任务:三维物体检测和三维语义分割。我们选择了两个有代表性的架构,这两个任务,并直接取代他们的SparseConv为基础的骨干为基于LinK的骨干,并保持其分割头和检测器的原始设计。详细架构如图4所示。

图4。(a)基于LinK的骨干结构;(b)构建的三维语义分割网络;(c)构建的3D目标检测网络。
4. 实验
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


