作为一个标准的程序员,应该有一些基本的数学素养,尤其现在很多人在学习人工智能相关知识,想抓住一波人工智能的机会。很多程序员可能连这样一些基础的数学问题都回答不上来。
- 矩阵
A(m,n)与矩阵B(n,k)乘积C维度是多少? - 抛一枚硬币,正面表示1,反面表示0,那么取值的数学期望E(x)是多少?
作为一个傲娇的程序员,应该要掌握这些数学基础知识,才更有可能码出一个伟大的产品。
线性代数
向量 向量(vector)是由一组实数组成的有序数组,同时具有大小和方向。一个n维向量a是由n个有序实数组成,表示为 a = [a1, a2, · · · , an]
矩阵
线性映射 矩阵通常表示一个n维线性空间v到m维线性空间w的一个映射f: v -> w 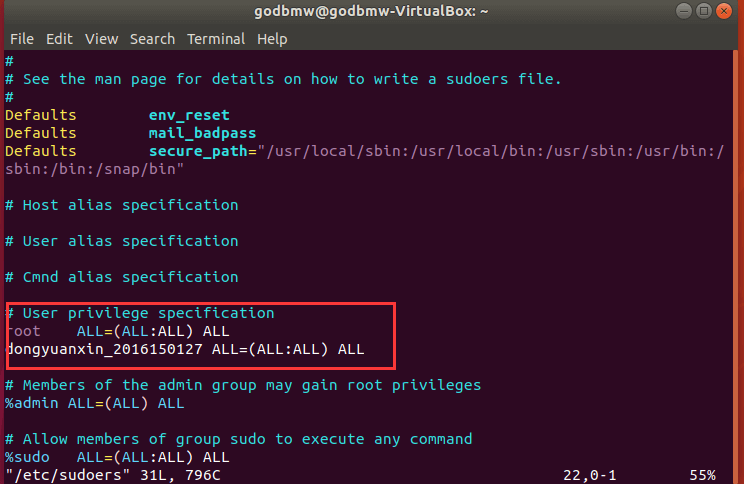
注:为了书写方便,X.T,表示向量X的转置。 这里:X(x1,x2,...,xn).T,y(y1,y2,...ym).T,都是列向量。分别表示v,w两个线性空间中的两个向量。A(m,n)是一个m*n的矩阵,描述了从v到w的一个线性映射。 
转置 将矩阵行列互换。
加法 如果A和B 都为m × n的矩阵,则A和B 的加也是m × n的矩阵,其每个元素是A和B相应元素相加。 [A + B]ij = aij + bij .
乘法 如A是k × m矩阵和B 是m × n矩阵,则乘积AB 是一个k × n的矩阵。
对角矩阵 对角矩阵是一个主对角线之外的元素皆为0的矩阵。对角线上的元素可以为0或其他值。一个n × n的对角矩阵A满足: [A]ij = 0 if i ̸= j ∀i, j ∈ {1, · · · , n}
特征值与特征矢量 如果一个标量λ和一个非零向量v满足 Av = λv, 则λ和v分别称为矩阵A的特征值和特征向量。
矩阵分解 一个矩阵通常可以用一些比较“简单”的矩阵来表示,称为矩阵分解。
奇异值分解 一个m×n的矩阵A的奇异值分解 
其中U 和V 分别为m × m和n×n 的正交矩阵,Σ为m × n的对角矩阵,其对角 线上的元素称为奇异值(singular value)。
特征分解 一个n × n的方块矩阵A的特征分解(Eigendecomposition)定义为 
其中Q为n × n的方块矩阵,其每一列都为A的特征向量,^为对角阵,其每一 个对角元素为A的特征值。 如果A为对称矩阵,则A可以被分解为  其中Q为正交阵。
其中Q为正交阵。
微积分
导数 对于定义域和值域都是实数域的函数f : R → R,若f(x)在点x0 的某个邻域∆x内,极限  存在,则称函数f(x)在点x0 处可导,
存在,则称函数f(x)在点x0 处可导,f'(x0)称为其导数,或导函数。 若函数f(x)在其定义域包含的某区间内每一个点都可导,那么也可以说函数f(x)在这个区间内可导。连续函数不一定可导,可导函数一定连续。例如函数|x|为连续函数,但在点x = 0处不可导。
导数法则
加法法则y = f(x),z = g(x)则
乘法法则
链式法则 求复合函数导数的一个法则,是在微积分中计算导数的一种常用方法。若x ∈ R,y = g(x) ∈ R,z = f(y) ∈ R,则 
Logistic 函数
Logistic函数是一种常用的S形函数,是比利时数学家 Pierre François Verhulst在1844-1845年研究种群数量的增长模型时提出命名的,最初作为一种生 态学模型。 Logistic函数定义为:  当参数为
当参数为(k = 1, x0 = 0, L = 1)时,logistic函数称为标准logistic函数,记 为σ(x)。  标准logistic函数在机器学习中使用得非常广泛,经常用来将一个实数空间的数映射到(0, 1)区间。标准
标准logistic函数在机器学习中使用得非常广泛,经常用来将一个实数空间的数映射到(0, 1)区间。标准logistic函数的导数为: 
softmax 函数
softmax函数是将多个标量映射为一个概率分布。对于K个标量x1, · · · , xK,softmax 函数定义为  这样,我们可以将
这样,我们可以将K个变量x1, · · · , xK转换为一个分布:z1, · · · , zK,满足  当softmax 函数的输入为K 维向量x时,
当softmax 函数的输入为K 维向量x时,  其中,1K = [1, · · · , 1]K×1 是K 维的全1向量。其导数为
其中,1K = [1, · · · , 1]K×1 是K 维的全1向量。其导数为 
数学优化
离散优化和连续优化:根据输入变量x的值域是否为实数域,数学优化问题可以分为离散优化问题和连续优化问题。
无约束优化和约束优化:在连续优化问题中,根据是否有变量的约束条件,可以将优化问题分为无约束优化问题和约束优化问题。 ### 优化算法
全局最优和局部最优
 海赛矩阵
海赛矩阵  《运筹学里面有讲》,前面一篇文章计算梯度步长的时候也用到了: 梯度下降算法
《运筹学里面有讲》,前面一篇文章计算梯度步长的时候也用到了: 梯度下降算法 

梯度
梯度的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。
梯度下降法
梯度下降法(Gradient Descent Method),也叫最速下降法(Steepest Descend Method),经常用来求解无约束优化的极小值问题。  梯度下降法的过程如图所示。曲线是等高线(水平集),即函数f为不同常数的集合构成的曲线。红色的箭头指向该点梯度的反方向(梯度方向与通过该点的等高线垂直)。沿着梯度下降方向,将最终到达函数f 值的局部最优解。
梯度下降法的过程如图所示。曲线是等高线(水平集),即函数f为不同常数的集合构成的曲线。红色的箭头指向该点梯度的反方向(梯度方向与通过该点的等高线垂直)。沿着梯度下降方向,将最终到达函数f 值的局部最优解。 
梯度上升法
如果我们要求解一个最大值问题,就需要向梯度正方向迭代进行搜索,逐渐接近函数的局部极大值点,这个过程则被称为梯度上升法。
概率论
概率论主要研究大量随机现象中的数量规律,其应用十分广泛,几乎遍及各个领域。
离散随机变量如果随机变量X 所可能取的值为有限可列举的,有n个有限取值 {x1, · · · , xn}, 则称X 为离散随机变量。要了解X 的统计规律,就必须知道它取每种可能值xi 的概率,即 
p(x1), · · · , p(xn)称为离散型随机变量X 的概率分布或分布,并且满足  常见的离散随机概率分布有:
常见的离散随机概率分布有:
伯努利分布
二项分布
连续随机变量
与离散随机变量不同,一些随机变量X 的取值是不可列举的,由全部实数 或者由一部分区间组成,比如  则称X 为连续随机变量。
则称X 为连续随机变量。
概率密度函数
连续随机变量X 的概率分布一般用概率密度函数p(x)来描述。p(x)为可积函数,并满足: 
均匀分布 若a, b为有限数,[a, b]上的均匀分布的概率密度函数定义为 
正态分布 又名高斯分布,是自然界最常见的一种分布,并且具有很多良好的性质,在很多领域都有非常重要的影响力,其概率密度函数为  其中,
其中,σ > 0,µ和σ 均为常数。若随机变量X 服从一个参数为µ和σ 的概率分布,简记为  当
当µ = 0,σ = 1时,称为标准正态分布。 均匀分布和正态分布的概率密度函数图: 
累积分布函数
对于一个随机变量X,其累积分布函数是随机变量X 的取值小于等于x的概率。  以连续随机变量X 为例,累积分布函数定义为:
以连续随机变量X 为例,累积分布函数定义为:  其中p(x)为概率密度函数,标准正态分布的累计分布函数:
其中p(x)为概率密度函数,标准正态分布的累计分布函数: 
随机向量
随机向量是指一组随机变量构成的向量。如果X1, X2, · · · , Xn 为n个随机变量, 那么称 [X1, X2, · · · , Xn] 为一个 n 维随机向量。一维随机向量称为随机变量。随机向量也分为离散随机向量和连续随机向量。 条件概率分布 对于离散随机向量(X, Y),已知X = x的条件下,随机变量Y = y的条件概率为:  对于二维连续随机向量(X, Y ),已知X = x的条件下,随机变量Y = y 的条件概率密度函数为
对于二维连续随机向量(X, Y ),已知X = x的条件下,随机变量Y = y 的条件概率密度函数为 
期望和方差
期望 对于离散变量X,其概率分布为p(x1), · · · , p(xn),X 的期望(expectation)或均值定义为  对于连续随机变量X,概率密度函数为p(x),其期望定义为
对于连续随机变量X,概率密度函数为p(x),其期望定义为 
方差 随机变量X 的方差(variance)用来定义它的概率分布的离散程度,定义为 
标准差 随机变量 X 的方差也称为它的二阶矩。X 的根方差或标准差。 
协方差 两个连续随机变量X 和Y 的协方差(covariance)用来衡量两个随机变量的分布之间的总体变化性,定义为  协方差经常也用来衡量两个随机变量之间的线性相关性。如果两个随机变量的协方差为0,那么称这两个随机变量是线性不相关。两个随机变量之间没有线性相关性,并非表示它们之间独立的,可能存在某种非线性的函数关系。反之,如果X 与Y 是统计独立的,那么它们之间的协方差一定为0。
协方差经常也用来衡量两个随机变量之间的线性相关性。如果两个随机变量的协方差为0,那么称这两个随机变量是线性不相关。两个随机变量之间没有线性相关性,并非表示它们之间独立的,可能存在某种非线性的函数关系。反之,如果X 与Y 是统计独立的,那么它们之间的协方差一定为0。
随机过程
随机过程(stochastic process)是一组随机变量Xt 的集合,其中t属于一个索引(index)集合T 。索引集合T 可以定义在时间域或者空间域,但一般为时间域,以实数或正数表示。当t为实数时,随机过程为连续随机过程;当t为整数时,为离散随机过程。日常生活中的很多例子包括股票的波动、语音信号、身高的变化等都可以看作是随机过程。常见的和时间相关的随机过程模型包括贝努力过程、随机游走、马尔可夫过程等。
马尔可夫过程 指一个随机过程在给定现在状态及所有过去状态情况下,其未来状态的条件概率分布仅依赖于当前状态。  其中X0:t 表示变量集合X0, X1, · · · , Xt,x0:t 为在状态空间中的状态序列。
其中X0:t 表示变量集合X0, X1, · · · , Xt,x0:t 为在状态空间中的状态序列。
马尔可夫链 离散时间的马尔可夫过程也称为马尔可夫链(Markov chain)。如果一个马尔可夫链的条件概率  马尔可夫的使用可以看前面一篇写的有意思的文章: 女朋友的心思你能猜得到吗?——马尔可夫链告诉你随机过程还有高斯过程,比较复杂,这里就不详细说明了。
马尔可夫的使用可以看前面一篇写的有意思的文章: 女朋友的心思你能猜得到吗?——马尔可夫链告诉你随机过程还有高斯过程,比较复杂,这里就不详细说明了。
信息论
信息论(information theory)是数学、物理、统计、计算机科学等多个学科的交叉领域。信息论是由 Claude Shannon最早提出的,主要研究信息的量化、存储和通信等方法。在机器学习相关领域,信息论也有着大量的应用。比如特征抽取、统计推断、自然语言处理等。
自信息和熵
在信息论中,熵用来衡量一个随机事件的不确定性。假设对一个随机变量X(取值集合为C概率分布为p(x), x ∈ C)进行编码,自信息I(x)是变量X = x时的信息量或编码长度,定义为 I(x) = − log(p(x)), 那么随机变量X 的平均编码长度,即熵定义为  其中当p(x) = 0时,我们定义0log0 = 0 熵是一个随机变量的平均编码长度,即自信息的数学期望。熵越高,则随机变量的信息越多;熵越低,则信息越少。如果变量X 当且仅当在x时
其中当p(x) = 0时,我们定义0log0 = 0 熵是一个随机变量的平均编码长度,即自信息的数学期望。熵越高,则随机变量的信息越多;熵越低,则信息越少。如果变量X 当且仅当在x时p(x) = 1,则熵为0。也就是说,对于一个确定的信息,其熵为0,信息量也为0。如果其概率分布为一个均匀分布,则熵最大。假设一个随机变量X 有三种可能值x1, x2, x3,不同概率分布对应的熵如下: 
联合熵和条件熵 对于两个离散随机变量X 和Y ,假设X 取值集合为X;Y 取值集合为Y,其联合概率分布满足为p(x, y),则X 和Y 的联合熵(Joint Entropy)为  X 和Y 的条件熵为
X 和Y 的条件熵为
互信息 互信息(mutual information)是衡量已知一个变量时,另一个变量不确定性的减少程度。两个离散随机变量X 和Y 的互信息定义为  交叉熵和散度 交叉熵 对应分布为p(x)的随机变量,熵H(p)表示其最优编码长度。交叉熵是按照概率分布q 的最优编码对真实分布为p的信息进行编码的长度,定义为
交叉熵和散度 交叉熵 对应分布为p(x)的随机变量,熵H(p)表示其最优编码长度。交叉熵是按照概率分布q 的最优编码对真实分布为p的信息进行编码的长度,定义为  在给定p的情况下,如果q 和p越接近,交叉熵越小;如果q 和p越远,交叉熵就越大。
在给定p的情况下,如果q 和p越接近,交叉熵越小;如果q 和p越远,交叉熵就越大。
文章来源: 博客园
原文链接: https://www.cnblogs.com/data-magnifier/p/14397061.html
- 还没有人评论,欢迎说说您的想法!
 客服
客服


