摘要:本文将从实践案例角度为大家解读强化学习中的梯度策略、添加基线(baseline)、优势函数、动作分配合适的分数(credit)。
本文分享自华为云社区《强化学习从基础到进阶-案例与实践[5]:梯度策略、添加基线(baseline)、优势函数、动作分配合适的分数(credit)》,作者: 汀丶。
1 策略梯度算法
如图 5.1 所示,强化学习有 3 个组成部分:演员(actor)、环境和奖励函数。智能体玩视频游戏时,演员负责操控游戏的摇杆, 比如向左、向右、开火等操作;环境就是游戏的主机,负责控制游戏的画面、负责控制怪兽的移动等;奖励函数就是当我们做什么事情、发生什么状况的时候,可以得到多少分数, 比如打败一只怪兽得到 20 分等。同样的概念用在围棋上也是一样的,演员就是 Alpha Go,它要决定棋子落在哪一个位置;环境就是对手;奖励函数就是围棋的规则,赢就是得一分,输就是负一分。在强化学习里,环境与奖励函数不是我们可以控制的,它们是在开始学习之前给定的。我们唯一需要做的就是调整演员里面的策略,使得演员可以得到最大的奖励。演员里面的策略决定了演员的动作,即给定一个输入,它会输出演员现在应该要执行的动作。
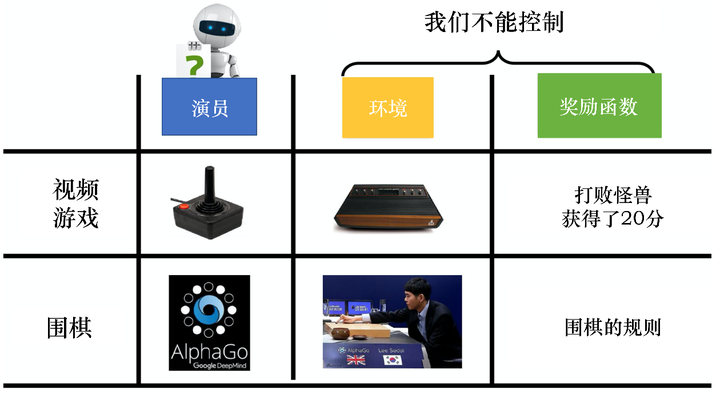
图 5.1 强化学习的组成部分
策略一般记作 ππ。假设我们使用深度学习来做强化学习,策略就是一个网络。网络里面有一些参数,我们用 θθ 来代表 ππ 的参数。网络的输入是智能体看到的东西,如果让智能体玩视频游戏,智能体看到的东西就是游戏的画面。智能体看到的东西会影响我们训练的效果。例如,在玩游戏的时候, 也许我们觉得游戏的画面是前后相关的,所以应该让策略去看从游戏开始到当前这个时间点之间所有画面的总和。因此我们可能会觉得要用到循环神经网络(recurrent neural network,RNN)来处理它,不过这样会比较难处理。我们可以用向量或矩阵来表示智能体的观测,并将观测输入策略网络,策略网络就会输出智能体要采取的动作。图 5.2 就是具体的例子,策略是一个网络;输入是游戏的画面,它通常是由像素组成的;输出是我们可以执行的动作,有几个动作,输出层就有几个神经元。假设我们现在可以执行的动作有 3 个,输出层就有 3 个神经元,每个神经元对应一个可以采取的动作。输入一个东西后,网络会给每一个可以采取的动作一个分数。我们可以把这个分数当作概率,演员根据概率的分布来决定它要采取的动作,比如 0.7 的概率向左走、0.2 的概率向右走、0.1的概率开火等。概率分布不同,演员采取的动作就会不一样。
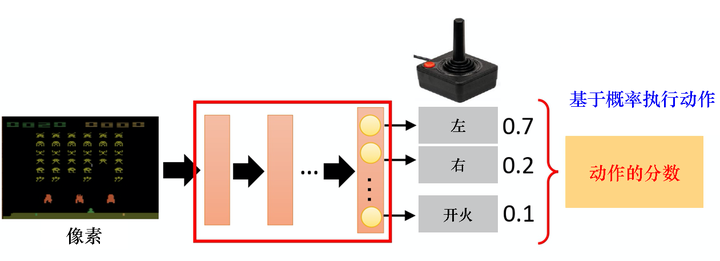
图 5.2 演员的策略
接下来我们用一个例子来说明演员与环境交互的过程。如图 5.3 所示,首先演员会看到一个视频游戏的初始画面,接下来它会根据内部的网络(内部的策略)来决定一个动作。假设演员现在决定的动作是向右,决定完动作以后,它就会得到一个奖励,奖励代表它采取这个动作以后得到的分数。
我们把游戏初始的画面记作 s1s1, 把第一次执行的动作记作 a1a1,把第一次执行动作以后得到的奖励记作 r1r1。不同的人有不同的记法,有人觉得在 s1s1 执行 a1a1 得到的奖励应该记为 r2r2,这两种记法都可以。演员决定一个动作以后,就会看到一个新的游戏画面s2s2。把 s2s2 输入给演员,演员决定要开火,它可能打败了一只怪兽,就得到五分。这个过程反复地持续下去,直到在某一个时间点执行某一个动作,得到奖励之后,环境决定这个游戏结束。例如,如果在这个游戏里面,我们控制宇宙飞船去击杀怪兽,如果宇宙飞船被毁或是把所有的怪兽都清空,游戏就结束了。
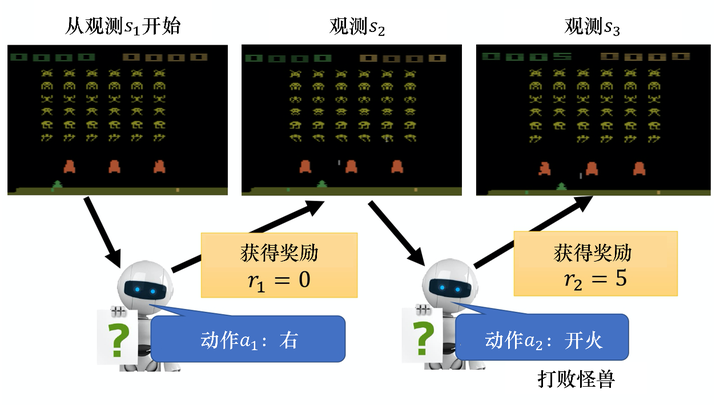
图 5.3 玩视频游戏的例子
如图 5.4 所示,一场游戏称为一个回合。将这场游戏里面得到的所有奖励都加起来,就是总奖励(total reward),也就是回报,我们用RR来表示它。演员要想办法来最大化它可以得到的奖励。
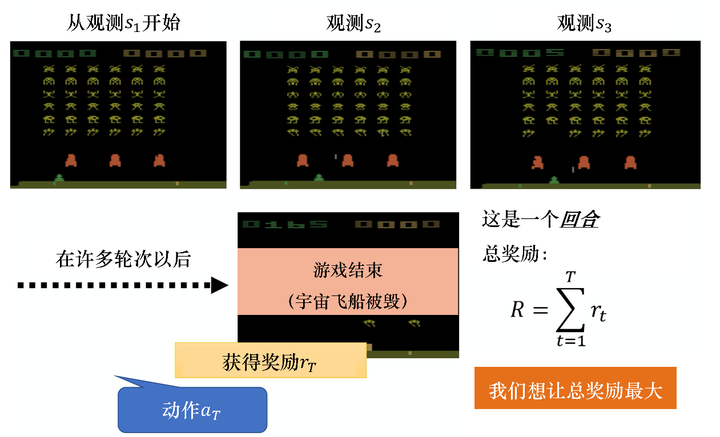
图 5.4 回报的例子
如图 5.5 所示,首先,环境是一个函数,我们可以把游戏的主机看成一个函数,虽然它不一定是神经网络,可能是基于规则的(rule-based)模型,但我们可以把它看作一个函数。这个函数一开始先“吐”出一个状态(游戏画面 s1s1),接下来演员看到游戏画面 s1s1 以后,它“吐”出动作 a1a1。环境把动作 a1a1 当作它的输入,再“吐”出新的游戏画面 s2s2。演员看到新的游戏画面s2s2,再采取新的动作 a2a2。环境看到 a2a2,再“吐”出 s3s3 …这个过程会一直持续下去,直到环境觉得应该要停止为止。
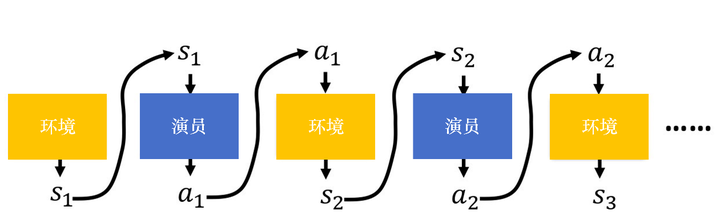
图 5.5 演员和环境
在一场游戏里面,我们把环境输出的 ss 与演员输出的动作 aa 全部组合起来,就是一个轨迹,即
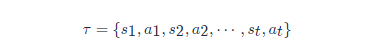
给定演员的参数 θθ,我们可以计算某个轨迹ττ发生的概率为
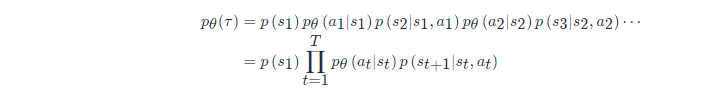

我们要穷举所有可能的轨迹 ττ, 每一个轨迹 ττ 都有一个概率。
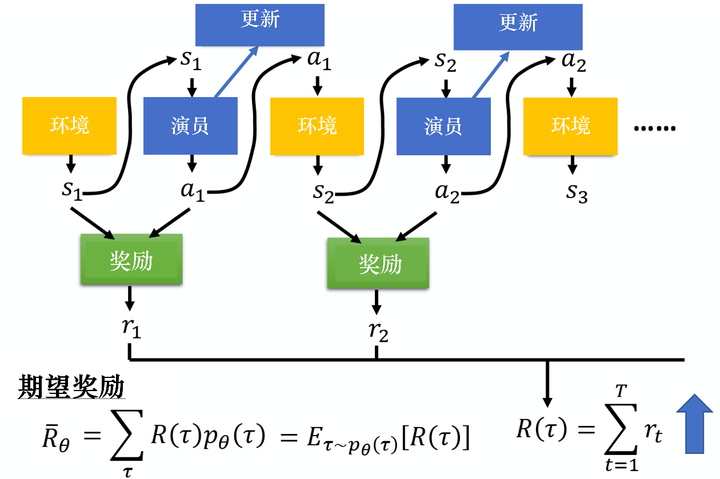
图 5.6 期望的奖励
比如 θθ 对应的模型很强,如果有一个回合 θθ 很快就死掉了,因为这种情况很少会发生,所以该回合对应的轨迹 ττ 的概率就很小;如果有一个回合 θθ 一直没死,因为这种情况很可能发生,所以该回合对应的轨迹 ττ 的概率就很大。我们可以根据 θθ 算出某一个轨迹 ττ 出现的概率,接下来计算 ττ 的总奖励。总奖励使用 ττ 出现的概率进行加权,对所有的 ττ 进行求和,就是期望值。给定一个参数,我们可以计算期望值为
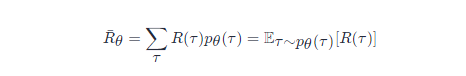




图 5.7 策略梯度
更新完模型以后,我们要重新采样数据再更新模型。注意,一般**策略梯度(policy gradient,PG)**采样的数据只会用一次。我们采样这些数据,然后用这些数据更新参数,再丢掉这些数据。接着重新采样数据,才能去更新参数。
接下来我们讲一些实现细节。如图 5.8 所示,我们可以把强化学习想成一个分类问题,这个分类问题就是输入一个图像,输出某个类。在解决分类问题时,我们要收集一些训练数据,数据中要有输入与输出的对。在实现的时候,我们把状态当作分类器的输入,就像在解决图像分类的问题,只是现在的类不是图像里面的东西,而是看到这张图像我们要采取什么样的动作,每一个动作就是一个类。比如第一个类是向左,第二个类是向右,第三个类是开火。
在解决分类问题时,我们要有输入和正确的输出,要有训练数据。但在强化学习中,我们通过采样来获得训练数据。假设在采样的过程中,在某个状态下,我们采样到要采取动作 aa, 那么就把动作 aa 当作标准答案(ground truth)。比如,我们在某个状态下,采样到要向左。因为是采样,所以向左这个动作不一定概率最高。假设我们采样到向左,在训练的时候,让智能体调整网络的参数, 如果看到某个状态,我们就向左。在一般的分类问题里面,我们在实现分类的时候,目标函数都会写成最小化交叉熵(cross entropy),最小化交叉熵就是最大化对数似然(log likelihood)。
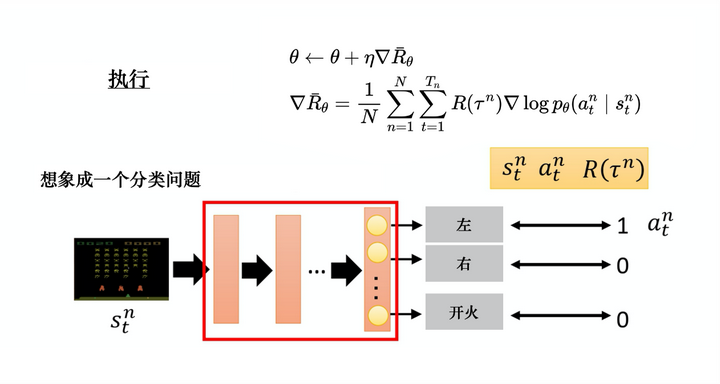
图 5.8 策略梯度实现细节
我们在解决分类问题的时候,目标函数就是最大化或最小化的对象,因为我们现在是最大化似然(likelihood),所以其实是最大化,我们要最大化
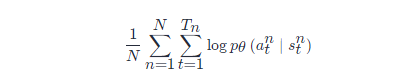
我们可在 PyTorch 里调用现成的函数来自动计算损失函数,并且把梯度计算出来。这是一般的分类问题,强化学习与分类问题唯一不同的地方是损失前面乘一个权重————整场游戏得到的总奖励 R(τ)R(τ),而不是在状态ss采取动作aa的时候得到的奖励,即
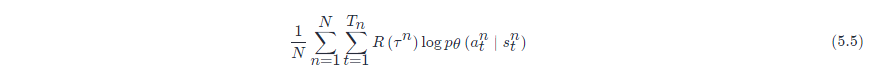
我们要把每一笔训练数据,都使用 R(τ)R(τ) 进行加权。如图 5.9 所示,我们使用 PyTorch 或 TensorFlow 之类的深度学习框架计算梯度就结束了,与一般分类问题差不多。
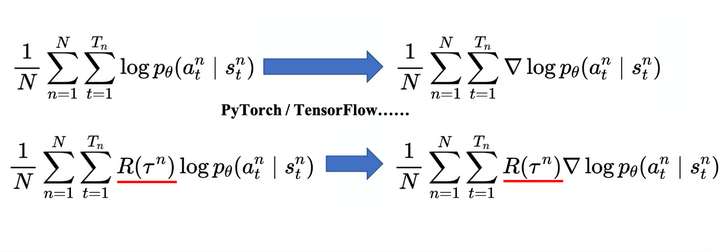
图 5.9 自动求梯度
2 策略梯度实现技巧
下面我们介绍一些在实现策略梯度时可以使用的技巧。
2.1 技巧 1:添加基线
第一个技巧:添加基线(baseline)。如果给定状态 ss 采取动作 aa,整场游戏得到正的奖励,就要增加 (s,a)(s,a) 的概率。如果给定状态 ss 执行动作 aa,整场游戏得到负的奖励,就要减小 (s,a)(s,a) 的概率。但在很多游戏里面,奖励总是正的,最低都是 0。比如打乒乓球游戏, 分数为 0 ~ 21 分,所以R(τ)R(τ)总是正的。假设我们直接使用式(5.5),在训练的时候告诉模型,不管是什么动作,都应该要把它的概率提升。
虽然R(τ)R(τ)总是正的,但它的值是有大有小的,比如我们在玩乒乓球游戏时,得到的奖励总是正的,但采取某些动作可能得到 0 分,采取某些动作可能得到 20 分。
如图 5.10 所示,假设我们在某一个状态有 3 个动作 a、b、c可以执行。根据式(5.6),我们要把这 3 个动作的概率,对数概率都提高。 但是它们前面的权重R(τ)R(τ)是不一样的。权重是有大有小的,权重小的,该动作的概率提高的就少;权重大的,该动作的概率提高的就多。 因为对数概率是一个概率,所以动作 a、b、c 的对数概率的和是 0。 所以提高少的,在做完归一化(normalize)以后,动作 b 的概率就是下降的;提高多的,该动作的概率才会上升。
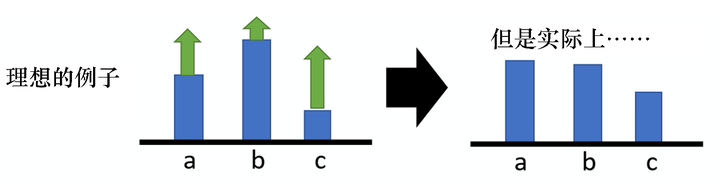
图 5.10 动作的概率的例子
这是一个理想的情况,但是实际上,我们是在做采样本来这边应该是一个期望(expectation),对所有可能的ss与aa的对进行求和。 但我们真正在学习的时候,只是采样了少量的ss与aa的对。 因为我们做的是采样,所以有一些动作可能从来都没有被采样到。如图 5.11 所示,在某一个状态,虽然可以执行的动作有 a、b、c,但我们可能只采样到动作 b 或者 只采样到动作 c,没有采样到动作 a。但现在所有动作的奖励都是正的,所以根据式(5.6),在这个状态采取a、b、c的概率都应该要提高。我们会遇到的问题是,因为 a 没有被采样到,所以其他动作的概率如果都要提高,a 的概率就要下降。 所以a不一定是一个不好的动作, 它只是没有被采样到。但因为 a 没有被采样到,它的概率就会下降,这显然是有问题的。要怎么解决这个问题呢?我们会希望奖励不总是正的。
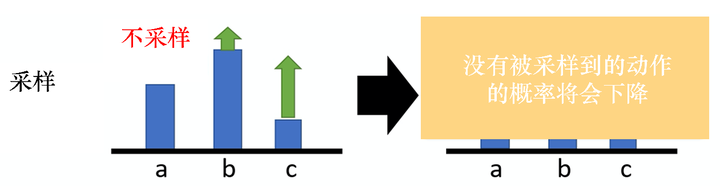
图 5.11 采样动作的问题
为了解决奖励总是正的的问题,我们可以把奖励减 bb,即

2.2 技巧 2:分配合适的分数
第二个技巧:给每一个动作分配合适的分数(credit)。如式(5.7)所示,只要在同一个回合里面,在同一场游戏里面,所有的状态-动作对就使用同样的奖励项进行加权。
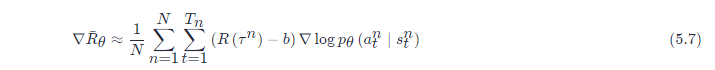

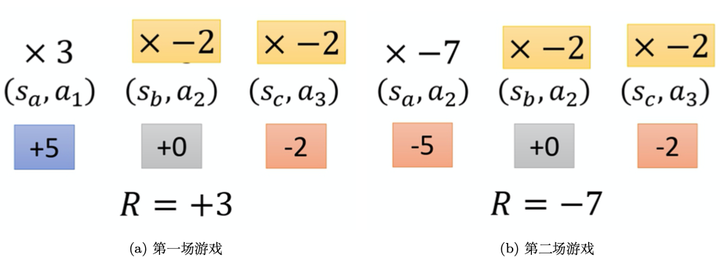
图 5.12 分配合适的分数
分配合适的分数这一技巧可以表达为
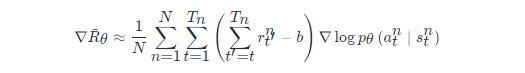
原来的权重是整场游戏的奖励的总和,现在改成从某个时刻 tt 开始,假设这个动作是在 tt 开始执行的,从 tt 一直到游戏结束所有奖励的总和才能代表这个动作的好坏。
接下来更进一步,我们把未来的奖励做一个折扣,即
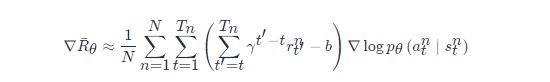

3 REINFORCE:蒙特卡洛策略梯度
如图 5.13 所示,蒙特卡洛方法可以理解为算法完成一个回合之后,再利用这个回合的数据去学习,做一次更新。因为我们已经获得了整个回合的数据,所以也能够获得每一个步骤的奖励,我们可以很方便地计算每个步骤的未来总奖励,即回报 GtGt 。GtGt 是未来总奖励,代表从这个步骤开始,我们能获得的奖励之和。$G_1 代表我们从第一步开始,往后能够获得的总奖励。代表我们从第一步开始,往后能够获得的总奖励。G_2$ 代表从第二步开始,往后能够获得的总奖励。
相比蒙特卡洛方法一个回合更新一次,时序差分方法是每个步骤更新一次,即每走一步,更新一次,时序差分方法的更新频率更高。时序差分方法使用Q函数来近似地表示未来总奖励 GtGt。
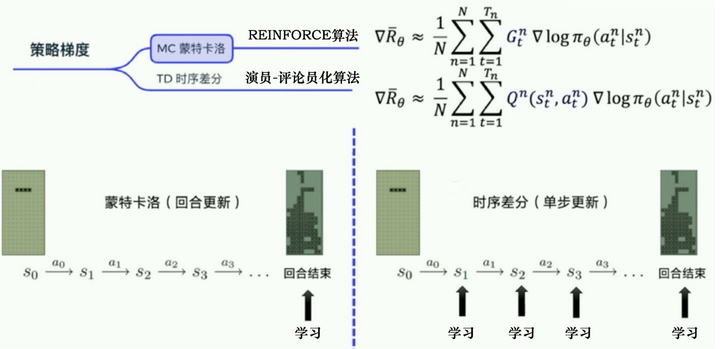
图 5.13 蒙特卡洛方法与时序差分方法


图 5.14 REINFORCE算法
独热编码(one-hot encoding)通常用于处理类别间不具有大小关系的特征。 例如血型,一共有4个取值(A型、B型、AB型、O型),独热编码会把血型变成一个4维稀疏向量,A型血表示为(1,0,0,0),B型血表示为(0,1,0,0),AB型血表示为(0,0,1,0),O型血表示为(0,0,0,1)。
如图 5.15 所示,手写数字识别是一个经典的多分类问题,输入是一张手写数字的图片,经过神经网络处理后,输出的是各个类别的概率。我们希望输出的概率分布尽可能地贴近真实值的概率分布。因为真实值只有一个数字 9,所以如果我们用独热向量的形式给它编码,也可以把真实值理解为一个概率分布,9 的概率就是1,其他数字的概率就是 0。神经网络的输出一开始可能会比较平均,通过不断地迭代、训练优化之后,我们会希望输出9 的概率可以远高于输出其他数字的概率。
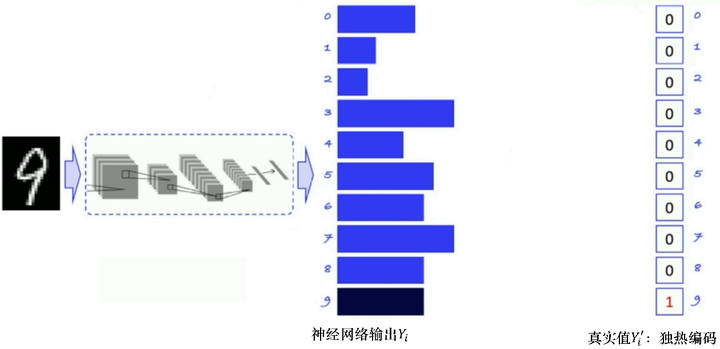
图 5.15 监督学习例子:手写数字识别
如图 5.16 所示,我们所要做的就是提高输出 9 的概率,降低输出其他数字的概率,让神经网络输出的概率分布能够更贴近真实值的概率分布。我们可以用交叉熵来表示两个概率分布之间的差距。

图 5.16 提高数字9的概率
我们看一下监督学习的优化流程,即怎么让输出逼近真实值。如图 5.17 所示,监督学习的优化流程就是将图片作为输入传给神经网络,神经网络会判断图片中的数字属于哪一类数字,输出所有数字可能的概率,再计算交叉熵,即神经网络的输出 YiYi 和真实的标签值 Yi′Yi′ 之间的距离 −∑Yi′⋅log(Yi)−∑Yi′⋅log(Yi)。我们希望尽可能地缩小这两个概率分布之间的差距,计算出的交叉熵可以作为损失函数传给神经网络里面的优化器进行优化,以自动进行神经网络的参数更新。

图 5.17 优化流程
类似地,如图 5.18 所示,策略梯度预测每一个状态下应该要输出的动作的概率,即输入状态 stst,输出动作atat的概率,比如 0.02、0.08、0.9。实际上输出给环境的动作是随机选择一个动作,比如我们选择向右这个动作,它的独热向量就是(0,0,1)。我们把神经网络的输出和实际动作代入交叉熵的公式就可以求出输出动作的概率和实际动作的概率之间的差距。但实际的动作 atat 只是我们输出的真实的动作,它不一定是正确的动作,它不能像手写数字识别一样作为一个正确的标签来指导神经网络朝着正确的方向更新,所以我们需要乘一个奖励回报 GtGt。GtGt相当于对真实动作的评价。如果 GtGt 越大,未来总奖励越大,那就说明当前输出的真实的动作就越好,损失就越需要重视。如果 GtGt 越小,那就说明动作 atat 不是很好,损失的权重就要小一点儿,优化力度也要小一点儿。通过与手写数字识别的一个对比,我们就知道为什么策略梯度损失会构造成这样。
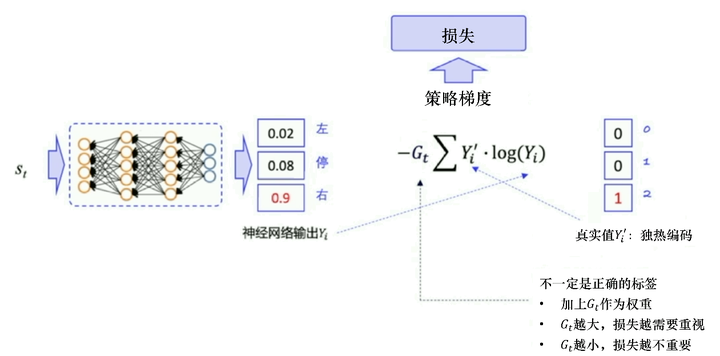
图 5.18 策略梯度损失
如图 5.19 所示,实际上我们在计算策略梯度损失的时候,要先对实际执行的动作取独热向量,再获取神经网络预测的动作概率,将它们相乘,我们就可以得到 logπ(at∣st,θ)logπ(at∣st,θ),这就是我们要构造的损失。因为我们可以获取整个回合的所有的轨迹,所以我们可以对这一条轨迹里面的每个动作都去计算一个损失。把所有的损失加起来,我们再将其“扔”给 Adam 的优化器去自动更新参数就好了。

图 5.19 损失计算
图 5.20 所示为REINFORCE 算法示意,首先我们需要一个策略模型来输出动作概率,输出动作概率后,通过 sample() 函数得到一个具体的动作,与环境交互后,我们可以得到整个回合的数据。得到回合数据之后,我们再去执行 learn() 函数,在 learn() 函数里面,我们就可以用这些数据去构造损失函数,“扔”给优化器优化,更新我们的策略模型。
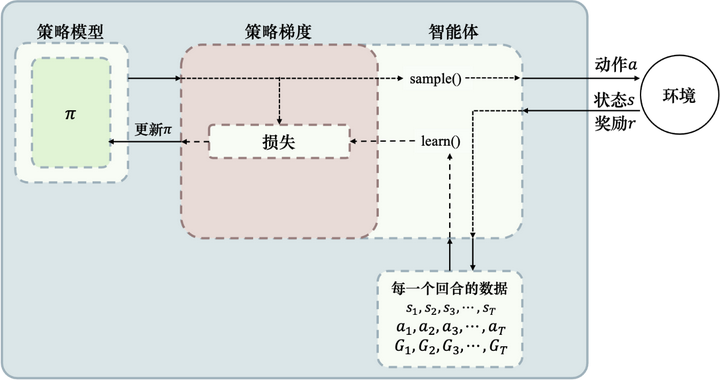
图 5.20 REINFORCE算法示意
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


