IO 神器 Okio
官方 是这么介绍 Okio 的:
Okio is a library that complements java.io and java.nio to make it much easier to access, store, and process your data. It started as a component of OkHttp, the capable HTTP client included in Android. It’s well-exercised and ready to solve new problems.
重点是这一句它使访问,存储和处理数据变得更加容易,既然 Okio 是对 java.io 的补充,那是否比传统 IO 好用呢?
看下 Okio 这么使用的,用它读写一个文件试试:
// OKio写文件
private static void writeFileByOKio() {
try (Sink sink = Okio.sink(new File(path));
BufferedSink bufferedSink = Okio.buffer(sink)) {
bufferedSink.writeUtf8("write" + "n" + "success!");
} catch (IOException e) {
e.printStackTrace();
}
}
//OKio读文件
private static void readFileByOKio() {
try (Source source = Okio.source(new File(path));
BufferedSource bufferedSource = Okio.buffer(source)) {
for (String line; (line = bufferedSource.readUtf8Line()) != null; ) {
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
}
从代码中可以看出,读写文件关键一步要创建出 BufferedSource 或 BufferedSink 对象。有了这两个对象,就可以直接读写文件了。
Okio为我们提供的 BufferedSink 和 BufferedSource 就具有以下基本所有的功能,不需要再串上一系列的装饰类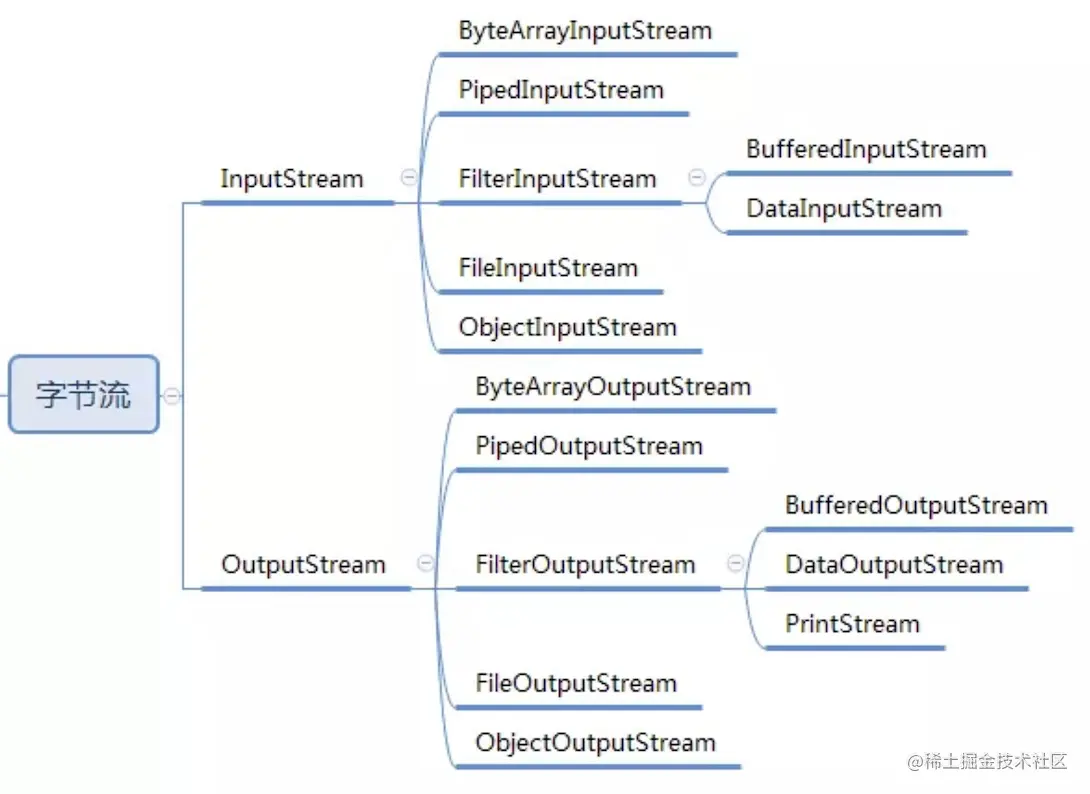
现在开始好奇Okio是怎么设计成这么好用的?看一下它的类设计: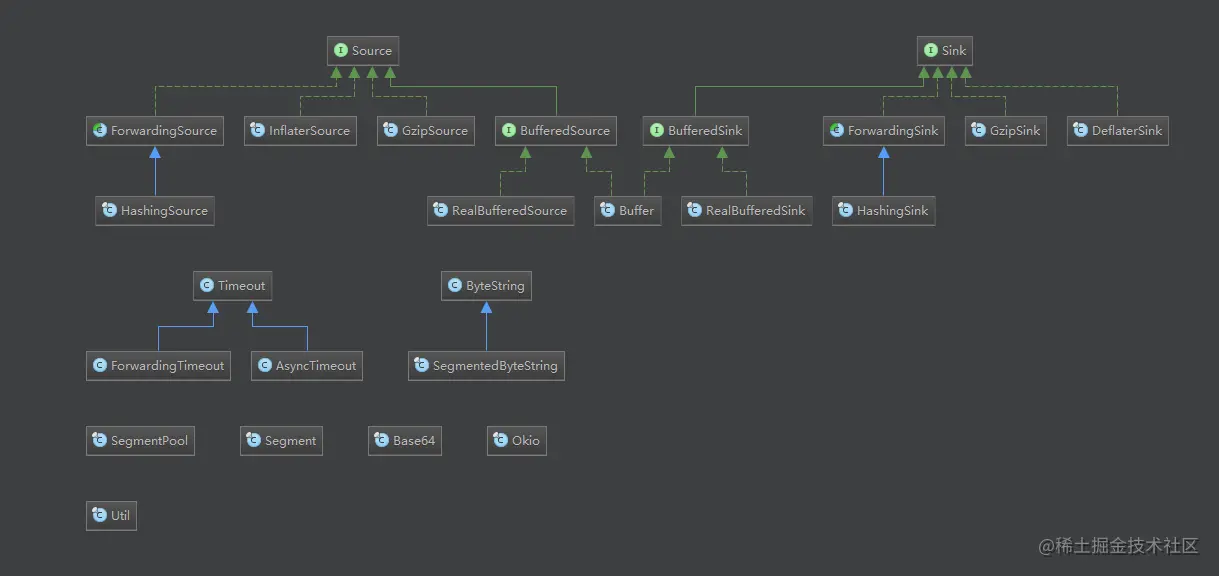
在Okio读写使用中,比较关键的类有 Source、Sink、BufferedSource、BufferedSink。
Source 和 Sink
Source 和 Sink 是接口,类似传统 IO 的 InputStream 和 OutputStream,具有输入、输出流功能。
Sourec 接口主要用来读取数据,而数据的来源可以是磁盘,网络,内存等。
public interface Source extends Closeable {
long read(Buffer sink, long byteCount) throws IOException;
Timeout timeout();
@Override void close() throws IOException;
}
Sink 接口主要用来写入数据。
public interface Sink extends Closeable, Flushable {
void write(Buffer source, long byteCount) throws IOException;
@Override void flush() throws IOException;
Timeout timeout();
@Override void close() throws IOException;
}
BufferedSource 和 BufferedSink
BufferedSource 和 BufferedSink 是对 Source 和 Sink 接口的扩展处理。Okio 将常用方法封装在 BufferedSource/BufferedSink 接口中,把底层字节流直接加工成需要的数据类型,摒弃 Java IO 中各种输入流和输出流的嵌套,并提供了很多方便的 api,比如 readInt()、readString()
public interface BufferedSource extends Source, ReadableByteChannel {
Buffer getBuffer();
int readInt() throws IOException;
String readString(long byteCount, Charset charset) throws IOException;
}
public interface BufferedSink extends Sink, WritableByteChannel {
Buffer buffer();
BufferedSink writeInt(int i) throws IOException;
BufferedSink writeString(String string, int beginIndex, int endIndex, Charset charset)
throws IOException;
}
RealBufferedSink 和 RealBufferedSource
上面的 BufferedSource 和 BufferedSink 都还是接口,它们对应的实现类就是 RealBufferedSink 和 RealBufferedSource 了。
final class RealBufferedSource implements BufferedSource {
public final Buffer buffer = new Buffer();
@Override public String readString(Charset charset) throws IOException {
if (charset == null) throw new IllegalArgumentException("charset == null");
buffer.writeAll(source);
return buffer.readString(charset);
}
//...
}
final class RealBufferedSink implements BufferedSink {
public final Buffer buffer = new Buffer();
@Override public BufferedSink writeString(String string, int beginIndex, int endIndex,
Charset charset) throws IOException {
if (closed) throw new IllegalStateException("closed");
buffer.writeString(string, beginIndex, endIndex, charset);
return emitCompleteSegments();
}
//...
}
RealBufferedSource 和 RealBufferedSink 内部都维护一个 Buffer 对象。里面的实现方法,最终实现都转到 Buffer 对象处理。所以这个 Buffer 类可以说是 Okio 的灵魂所在。下面会详细介绍。
Buffer
Buffer 的好处是以数据块 Segment 从 InputStream 读取数据的,相比单个字节读取来说,效率提高了,是一种空间换时间的策略。
public final class Buffer implements BufferedSource, BufferedSink, Cloneable, ByteChannel {
Segment head;
@Override public Buffer getBuffer() {
return this;
}
@Override public String readString(long byteCount, Charset charset) throws EOFException {
checkOffsetAndCount(size, 0, byteCount);
if (charset == null) throw new IllegalArgumentException("charset == null");
if (byteCount > Integer.MAX_VALUE) {
throw new IllegalArgumentException("byteCount > Integer.MAX_VALUE: " + byteCount);
}
if (byteCount == 0) return "";
Segment s = head;
if (s.pos + byteCount > s.limit) {
// If the string spans multiple segments, delegate to readBytes().
return new String(readByteArray(byteCount), charset);
}
String result = new String(s.data, s.pos, (int) byteCount, charset);
s.pos += byteCount;
size -= byteCount;
if (s.pos == s.limit) {
head = s.pop();
SegmentPool.recycle(s);
}
return result;
}
//...
}
从代码中可以看出,这个 Buffer 是个集大成者,实现了 BufferedSink 和 BufferedSource 的接口,也就是意味着它同时具有读和写的功能。
Buffer 包含了指向第一个和最后一个 Segment 的引用,以及当前读写位置等信息。当进行读写操作时,Buffer 会在 Segment 之间移动,而不需要进行数据的实际拷贝。那 Segment ,又是什么呢?
final class Segment {
//大小是8kb
static final int SIZE = 8192;
//读取数据的起始位置
int pos;
//写数据的起始位置
int limit;
//后继
Segment next;
//前继
Segment prev;
//将当前的Segment对象从双向链表中移除,并返回链表中的下一个结点作为头结点
public final @Nullable Segment pop() {
Segment result = next != this ? next : null;
prev.next = next;
next.prev = prev;
next = null;
prev = null;
return result;
}
//向链表中当前结点的后面插入一个新的Segment结点对象,并移动next指向新插入的结点
public final Segment push(Segment segment) {
segment.prev = this;
segment.next = next;
next.prev = segment;
next = segment;
return segment;
}
//单个Segment空间不足以存储写入的数据时,就会尝试拆分为两个Segment
public final Segment split(int byteCount) {
//...
}
//合并一些邻近的Segment
public final void compact() {
}
}
从 pop 和 push 方法可以看出 Segment 是一个双向链表的数据结构。一个 Segment 大小是 8kb。正是由于 Segment 使 IO 读写操作能如此高效。
和 Segment 紧密相关的还有一个 `SegmentPoll 。
final class SegmentPool {
static final long MAX_SIZE = 64 * 1024;
static @Nullable Segment next;
//当池子里面有空闲的 Segment 就直接复用,否则就创建一个新的 Segment
static Segment take() {
synchronized (SegmentPool.class) {
if (next != null) {
Segment result = next;
next = result.next;
result.next = null;
byteCount -= Segment.SIZE;
return result;
}
}
return new Segment(); // Pool is empty. Don't zero-fill while holding a lock.
}
//回收 segment 进行复用,提高效率
static void recycle(Segment segment) {
if (segment.next != null || segment.prev != null) throw new IllegalArgumentException();
if (segment.shared) return; // This segment cannot be recycled.
synchronized (SegmentPool.class) {
if (byteCount + Segment.SIZE > MAX_SIZE) return; // Pool is full.
byteCount += Segment.SIZE;
segment.next = next;
segment.pos = segment.limit = 0;
next = segment;
}
}
}
SegmentPool 是一个缓存 Segment 的池,它有 64kb 大小也就是 8 个 Segment 的长度。既然作为一个池,就和线程池的作用类似,为了复用前面被回收的 Segment。recycle() 方法的作用则是回收一个 Segment 对象。被回收的 Segment 对象将会被插入到 SegmentPool 中的单链表的头部,以便后面继续复用。
SegmentPool 的作用防止已申请的资源被回收,增加资源的重复利用,减少 GC,过于频繁的 GC 是会降低性能的
可以看到 Okio 在内存优化上下了很大的功夫,提升了资源的利用率,从而提升了性能。
总结
不仅如此,Okio还提供其他很有用的功能:
比如提供了一系列的方便工具
- GZip的透明处理
- 对数据计算md5、sha1等都提供了支持,对数据校验非常方便
作者:树獭非懒
链接:https://juejin.cn/post/6923902848908394510
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


