★ 微服务系列
1 微服务的注册与发现
我们前面在全景架构中对服务注册与发现做了大致的说明,本章我们着重详细说明微服务下注册与发现的这个能力。
微服务注册与发现类似于生活中的"电话通讯录"的概念,它记录了通讯录服务和电话的映射关系。在分布式架构中,服务会注册进去,当服务需要调用其它服务时,就这里找到服务的地址,进行调用。
步骤如下:
1、你先要把"好友某某"记录在通讯录中。
2、拨打电话的时候通过通讯录中找到"好友某某",并拨通回电话。
3、当好友某某电话号码更新的时候,需要通知到你,并修改通讯录服务中的号码。
从这个过程中我们看到了一些特点:
1、把 "好友某某" 的电话号码写入通讯录中,统一在通讯录中维护,后续号码变更也是更新到通讯录中,这个过程就是服务注册的过程。
2、后续我们通过"好友某某"就可以定位到通讯录中的电话号码,并拨通电话,这个过程理解为服务发现的过程。
而我们微服务架构中的服务注册与发现结构如下图所示:
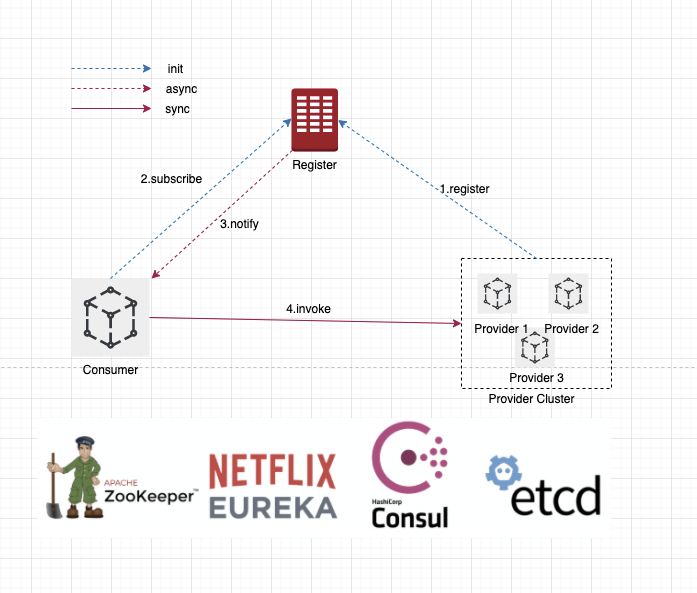
图片中是一个典型的微服务架构,这个结构中主要涉及到三大角色:
provider - 服务提供者
consumer - 服务消费者
register center - 注册中心
它们之间的关系大致如下:
1、每个微服务在启动时,将自己的网络地址等信息(微服务的ServiceName、IP、Port、MetaData等)注册到注册中心,注册中心存储这些数据。
2、服务消费者从注册中心查询服务提供者的地址,并通过该地址调用服务提供者的接口。
3、各个微服务与注册中心使用一定机制(例如心跳)通信。如果注册中心与某微服务长时间无法通信,就会注销该实例。
优点如下:
1、解耦:服务消费者跟服务提供者解耦,各自变化,不互相影响
2、扩展:服务消费者和服务提供者增加和删除新的服务,对于双方没有任何影响
3、中介者设计模式:用一个中介对象来封装一系列的对象交互,这是一种多对多关系的中介者模式。
从功能上拆开主要有三块:服务注册、服务发现,和注册中心。我们一个一个来看。
1.1 服务注册
如图中,为Register注册中心注册一个服务信息,会将服务的信息:ServiceName、IP、Port以及服务实例MetaData元数据信息写入到注册中心。当服务发生变化的时候,也可以更新到注册中心。
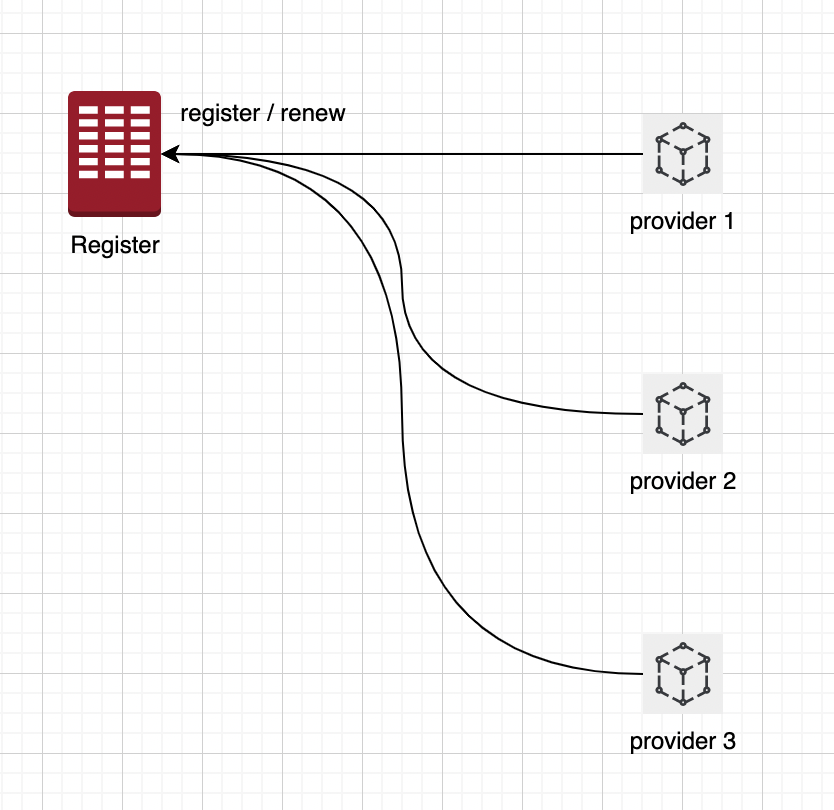
服务提供者(服务实例) 的服务注册模型是一种简单、容易理解、流行的服务注册模型,其在多种技术生态中都有所体现:
1、在K8S生态中,通过 K8S Service服务信息,和Pod的 endpoint(用来记录service对应的pod的访问地址)来进行注册。
2、在Spring Cloud生态中,应用名 对应 服务Service,实例 IP + Port 对应 Instance实例。比较典型的就是A服务,后面对应有多个实例做负载均衡。
3、在其他的注册组件中,比如 Eureka、Consul,服务模型也都是 服务→ 服务实例。
可以认为服务实例是一个真正的实体的载体,服务是对这些相同能力或者相同功能服务实例的一个抽象。
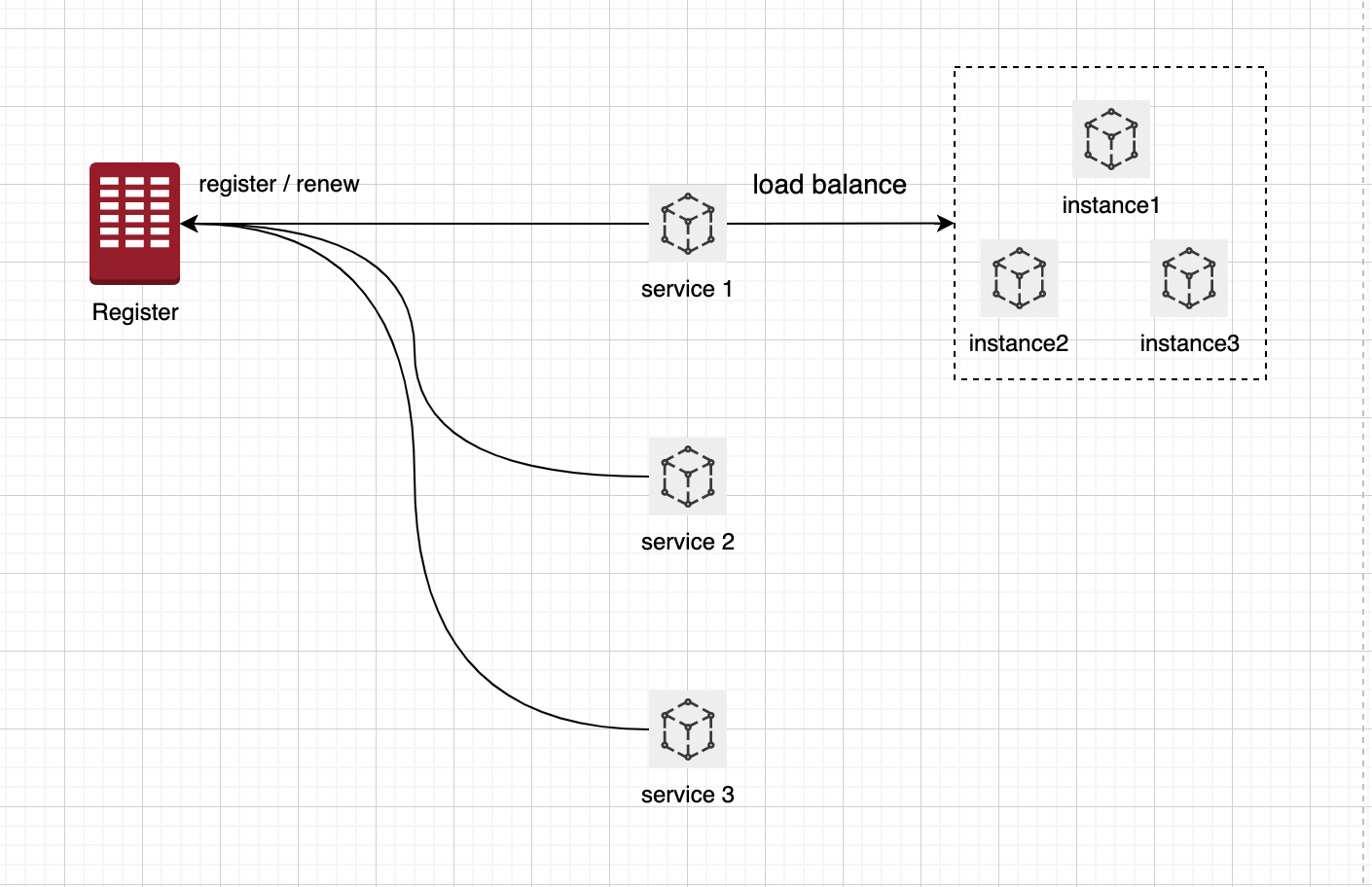
1.2 服务发现
服务发现实际就是我们查询已经注册好的服务提供者,比如 p->p.queryService(serviceName),通过服务名称查询某个服务是否存在,如果存在,
返回它的所有实例信息,即一组包含ip 、 port 、metadata元数据信息的endpoints信息。
这一组endpoints信息一般会被缓存在本地,如果注册中心挂掉,可保证段时间内依旧可用,这是去中心化的做法。对于单个 Service 后面有多个 Instance的情况(如上图),做 load balance。
服务发现的方式一般有两种:
1、拉取的方式:服务消费方(Consumer)主动向注册中心发起服务查询的请求。
2、推送的方式:服务订阅/通知变更(下发):服务消费方(Consumer)主动向注册中心订阅某个服务,当注册中心中该服务信息发生变更时,注册中心主动通知消费者。
1.3 注册中心
注册中心提供的基本能力包括:提供服务注册、服务发现 以及 健康检查。
服务注册跟服务发现上面已经详细介绍了, 健康检查指的是指注册中心能够感知到微服务实例的健康状况,便于上游微服务实例及时发现下游微服务实例的健康状况。采取必备的访问措施,如避免访问不健康的实例。
主要的检查方式包括:
1、服务Provider 进行 TTL 健康汇报(Time To Live,微服务Provider定期向注册中心汇报健康状态)。
2、注册中心主动检查服务Provider接口。
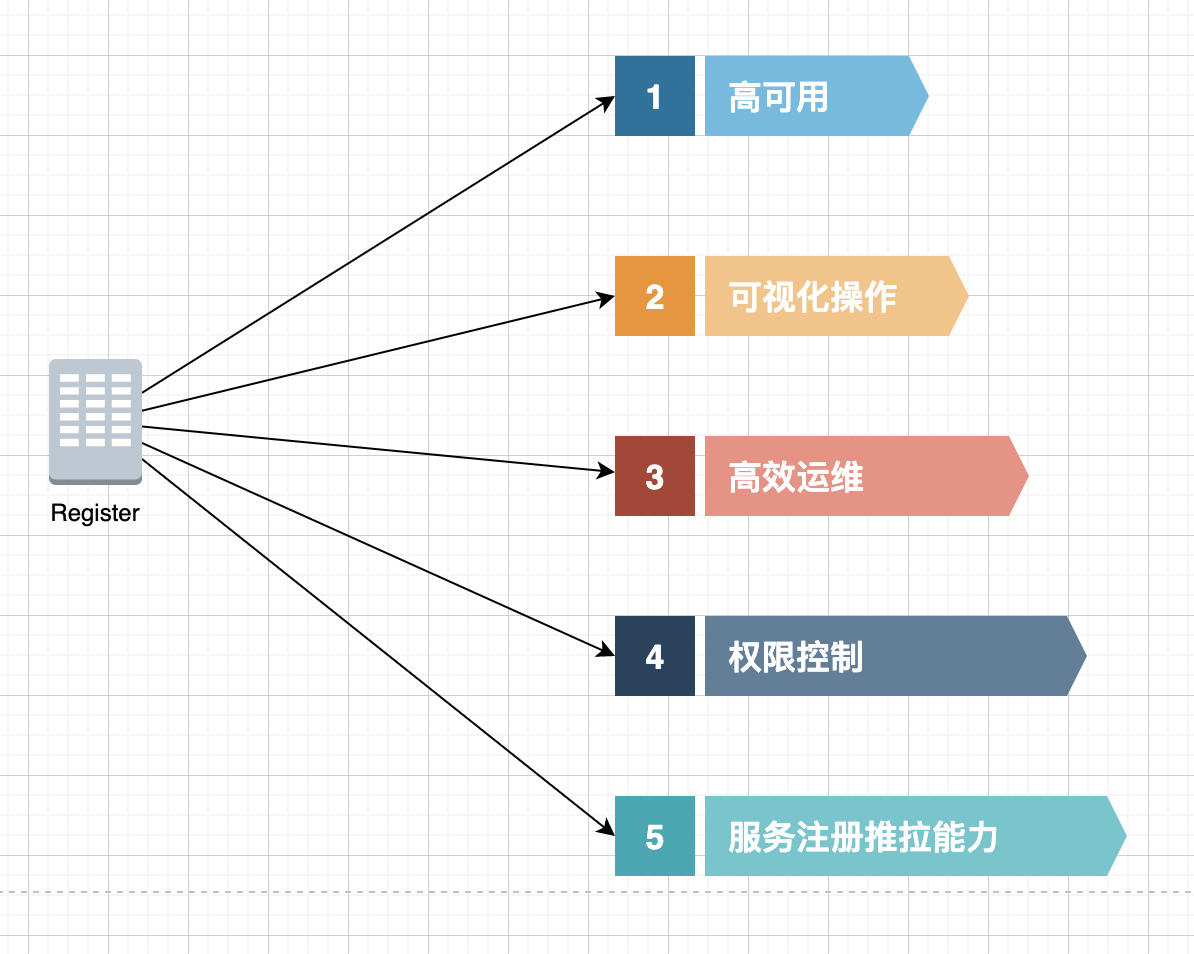
综合我们前面的内容,可以总结下注册中心有如下几种能力:
1、高可用
这个主要体现在两个方面。一个方面是,注册中心本身作为基础设施层,具备高可用;第二种是就是前面我们说到的去中心化,极端情况下的故障,短时间内是不影响微服务应用的调用的
2、可视化操作
常用的注册中心,类似 Eureka、Consul 都有比较丰富的管理界面,对配置、服务注册、服务发现进行可视化管理。
3、高效运维
注册中心的文档丰富,对运维的支持比较好,并且对于服务的注册是动态感知获取的,方便动态扩容。
4、权限控制
数据是具有敏感性,无论是服务信息注册或服务是调用,需要具备权限控制能力,避免侵入或越权请求
5、服务注册推、拉能力
这个前面说过了,微服务应用程序(服务的Consumer),能够快速感知到服务实例的变化情况,使用拉取或者注册中心下发的方式进行处理。
2 现下的主流注册中心
2.1 Eureka
2.1.1 介绍
Eureka是Netflix OSS套件中关于服务注册和发现的解决方案。因为Spring Cloud 在它的微服务解决方案中对Eureka进行了集成,并作为优先推荐方案进行宣传,所以早期有用 Spring Cloud 来建设微服务系统的同学会比较熟悉。
目前大量公司的微服务系统中依旧使用Eureka作为注册中心,它的核心设计思想也被后续大量注册中心产品借鉴。但目前 Eureka 2.0已经停止维护,所以新的微服务架构设计中,不再建议使用。
Spring Cloud Netflix主要分为两个部分:
1、Eureka Server: 作为注册中心Server端,向微服务应用程序提供服务注册、发现、健康检查等能力。
2、Eureka Client: 微服务应用程序Client端,用以和Eureka Server进行通信。
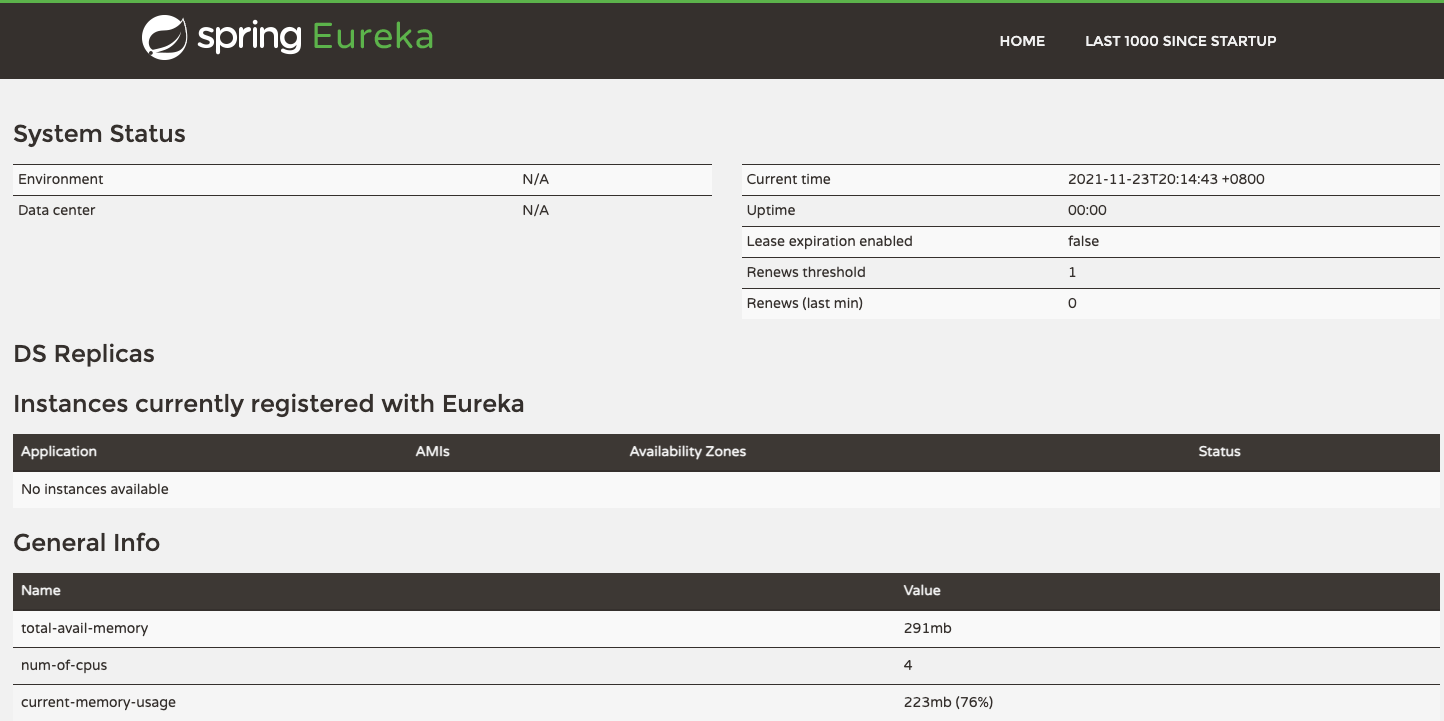
Eureka有比较友好的管理界面,如上图所示:
1、System Status:显示当前Eureka Server信息。
2、Instances Current registered with Eureka:在Eureka Server当前注册的数据,在Spring Cloud生态中,被注册的服务可以呗发现并罗列在这个地方。
3、General Info:基本信息,如cpu、内存、环境等。
2.1.2 整体架构
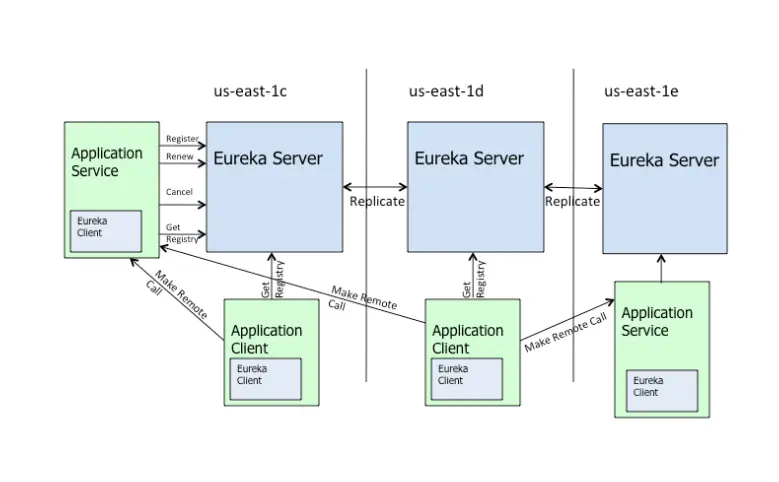
Eureka Server可以运行多个实例来构建集群,解决单点问题,但不同于ZooKeeper的选举leader的过程,Eureka Server采用的是Peer to Peer对等通信。
所以他有如下特点:
1、去中心化的架构:无master/slave区分,每一个Peer都是对等的。在这种架构中,节点通过彼此互相注册来提高可用性,每个节点需要添加一个或多个有效的serviceUrl指向其他节点。每个节点都可被视为其他节点的副本。
2、故障转移/故障恢复:如果某台Eureka Server宕机,Eureka Client的请求会自动切换到新的Eureka Server节点,当宕机的服务器重新恢复后,Eureka会再次将其纳入到服务器集群管理之中。
3、节点复制:当节点开始接受客户端请求时,所有的操作都会进行replicateToPeer(节点间复制)操作,将请求复制到其他Eureka Server当前所知的所有节点中。
同理,一个新的Eureka Server节点启动后,会首先尝试从邻近节点获取所有实例注册表信息,完成初始化。
4、CAP模式:复制算法非强一致性算法,而是当有数据写入时,Eureka Server将数据同步给其他的节点,因此Eureka在CAP提系统(一致性、可用性、分区容错性)是典型的AP系统。
2.1.3 接入Spring Cloud

如上图所示:
1、Provider 服务提供者:服务向注册中心注册服务信息,即 服务 -> 服务实例 数据模型, 同时定时向注册中心汇报健康检查,如果一定时间内(一般90s)没有进行心跳汇报,则会被注册中心剔除。
所以这边注意,注册中心感知到应用下线并进行剔除这个过程可能比较长。
2、Consumer 服务消费者:服务向注册中心获取所需服务对应的服务实例信息。这边需要注意,Eureka不支持订阅,因此在Spring Cloud生态中,通过定时拉取方式从注册中心中获取所需的服务实例信息。
3、Remote Call 远程调用:Consumer从注册中心获取的Provider的实例信息,通过 Load Balance的策略,确定一个实际的实例,发起远程调用。
2.2 ZooKeeper
2.2.1 介绍
作为一个分布式的、开源的协调服务,ZooKeeper实现了一系列基础功能,包括简单易用的接口。
这些接口被用来实现服务的注册与发现功能。并实现一些高级功能,如数据同步、分布式锁、配置中心、集群选举、命名服务等。

在数据模型上,类似于传统的文件系统,节点类型分为:
1、持久节点:节点创建后,就一直存在,除非执行删除操作,主动删掉这个节点。
2、临时节点(注册中心场景下的主要实现机制):临时节点的生命周期和客户端会话绑定。也就是说,如果客户端会话失效,那么这个节点就会自动被清除掉。
在实际场景下,微服务启动的时候,会创建一个服务临时节点,等把服务停止,短时间后节点就没有了。
Zookeeper有如下特点:
2.2.2 整体架构
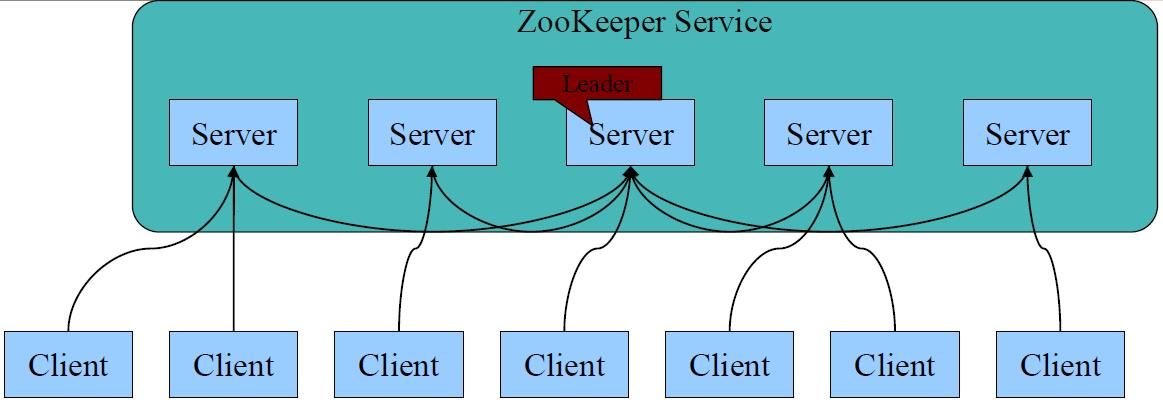
上图是Zookeeper 的服务架构,他有如下流程:
1、 多个节点组成分布式架构,每个Server在内存中存储一份数据;
2、通过选举产生leader,通过 Paxos(帕克索斯)强一致性算法 进行保证,是典型的CP结构。
3、Leader负责处理数据更新等操作(Zab协议);
2.2.3 接入Dubbo生态
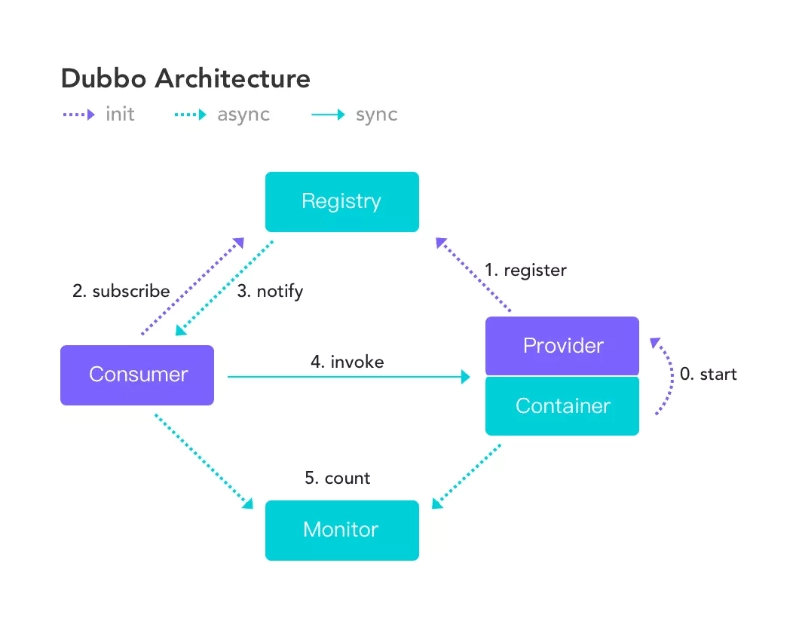
上图中的角色如下:
Provider:提供者,服务发布方
Consumer:消费者, 调用服务方
Container:Dubbo容器.依赖于Spring容器
Registry:注册中心,当Container启动时把所有可以提供的服务列表上Registry中进行注册,告诉Consumer提供了什么服务,以及服务方的位置
Monitor:监听器
说明:ZooKeeper在注册中心方面对Dubbo生态支持的比较好。服务提供者Providerzai Container启动时主动向注册中心Registry ZooKeeper中注册信息。
服务消费者Consumer启动时向注册中心Registry ZooKeeper中订阅注册中心,当Provider的信息发生变化时,注册中心ZooKeeper会主动向Consumer进行推送通知变更。
这边注意与Eureka的区别,这是主动推送通知,是注册中心下发的操作。
2.3 Consul
2.3.1 介绍
Consul是HashiCorp推出的一款软件,是一个Service Mesh解决方案,提供了功能丰富的控制面功能:
1、Service Discovery(服务发现)
2、Configuration(配置化)
3、Segmentation Functionality
这些功能可以根据需要独立使用,或者将它们一起使用用来构建完整的Service Mesh。
Consul提供的关键功能如下:
1、Service Discovery:服务注册/发现功能。
2、Health Checking:健康检查,丰富的健康检查方式;
3、KV Store:KV存储功能,可应用多种场景,如动态配置存储,分布式协调、leader选举等。
4、Multi DataCenter:多数据中心。
2.3.2 整体架构
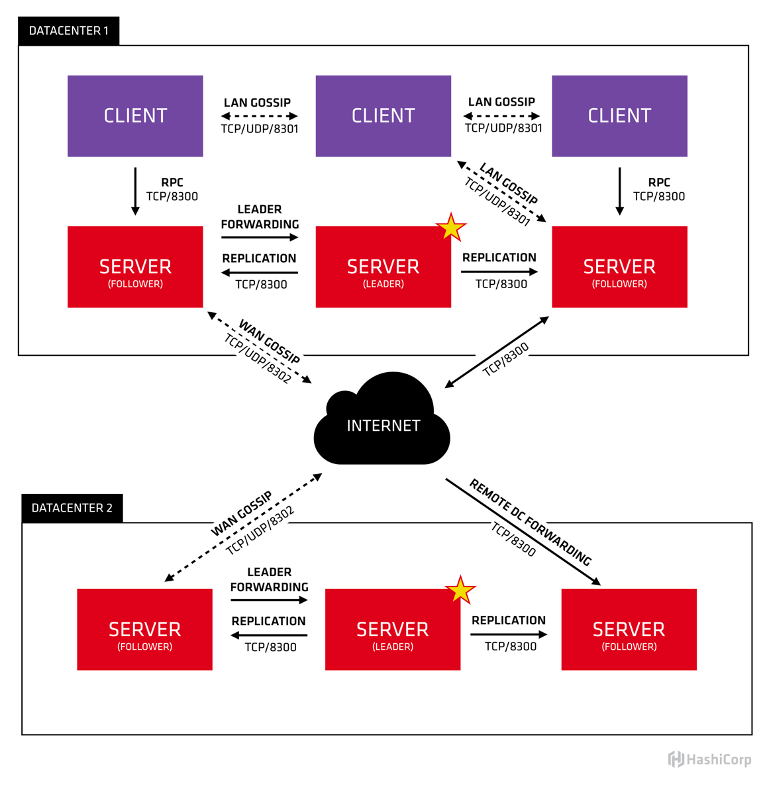
如上图为Consul的架构,这边对技术点做一下说明:
1、Raft: 一种分布式一致性算法,Consul使用该算法保持强一致性,所以也是典型的CP模式
2、Client:Client是一种agent,其将会重定向所有的RPC 请求到Server。Client是无状态的,其主要参与LAN Gossip协议池。其占用很少的资源,并且消耗很少的网络带宽。
3、Server:Server是一种agent,其包含了一系列的责任包括:参与Raft协议写半数(Raft Quorum)、维护集群状态、响应RPC响应、和其他Datacenter通过WAN gossip交换信息和重定向查询请求至leader或者远端Datacenter。
4、Datacenter: Datacenter其是私有的、低延迟、高带宽的网络环境,去除了在公共网络上的网络交互。
5、Consensus: Consensus一致性在leader 选举、顺序执行transaction 上。当这些事务已经提交至有限状态机(finite-state machine)中,Consul定义consensus作为复制状态机的一致性。本质上使用实现了Raft协议,对于具体实现细节可参考 Consensus Protocol。
6、Gossip:Consul使用了Serf,其提供了Gossip协议多种用途,Serf提供成员关系、失败检查和事件广播。
7、LAN Gossip: Local Area Network Gossip其包含在同一个网络环境或Datacenter的节点。
8、WAN Gossip: Wide Area Network Gossip 其只包含Server节点,这些server分布在不同的datacenter中,其主要通过因特网或广域网相互交流。
9、RPC: 远程过程调用,用于服务之间的通信。
10、CAP抉择:在高可用方面,Consul使用Raft协议作为其分布式一致性协议,本身对故障节点有一定的容忍性,在单个DataCenter中Consul集群中节点的数量控制在2*n + 1个节点,其中n为可容忍的宕机个数,通常为3个节点。
所以是典型的CP模式。
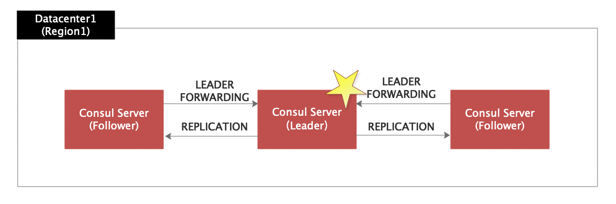
根据Consul 的选举机制和服务原理,我们有两个注意点 :
1、部署Consul Service 节点应该奇数为宜,因为+1的偶数节点和奇数节点可容忍的故障数是一样的,比如上图3和4,另一方面,偶数个节点在选主节点的时候可能会出现二分选票的情况,还得重新选举。
2、Consul Service 节点数不是越多越好,虽然Server数量越多可容忍的故障数越多,但是Raft进行日志复制也是很耗时间的,而且Server数量越多,性能越低,所以结合实际场景,一般建议Server部署3个即可。
有兴趣的同学可以去Consul官网看看它的选举机制,还可以对比下Redis中Sentinel模式。
2.3.3 生态对接
对接Spring Cloud生态
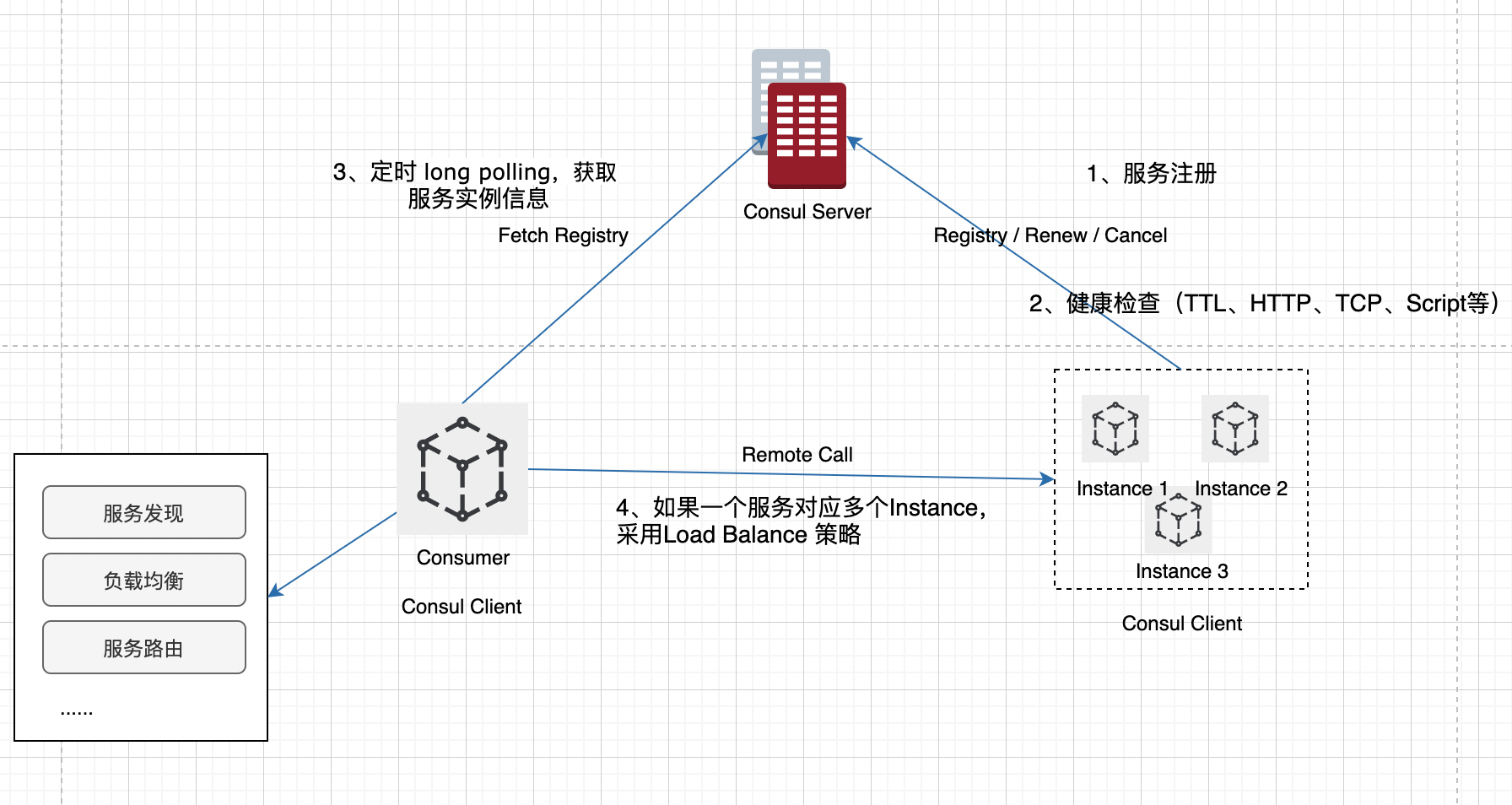
Consul作为注册中心,集成在Spring Cloud生态。可以看出,跟Eureka对接到Spring Cloud 生态的过程很像。
但是这边的健康检查更丰富,可以有多种不同的的Check方式:
- Script check(Script+ Interval)
- 基于HTTP请求
- 基于tcp请求
- 基于grpc请求
2.4 总结对比
| 指标 | Eureka | Zookeeper | Consul | Etcd |
| 一致性协议 | AP | CP(Paxos算法) | CP(Raft算法) | CP(Raft算法) |
| 健康检查 | TTL(Time To Live) | TCP Keep Alive | TTLHTTPTCPScript | Lease TTL KeepAlive |
| watch/long polling | 不支持 | watch | long polling | watch |
| 雪崩保护 | 支持 | 不支持 | 不支持 | 不支持 |
| 安全与权限 | 不支持 | ACL | ACL | RBAC |
| 是否支持多数据中心 | 是 | 否 | 是 | 否 |
| 是否有管理界面 | 是 | 否(可用第三方ZkTools) | 是 | 否 |
| Spring Cloud 集成 | 支持 | 支持 | 支持 | 支持 |
| Dubbo 集成 | 不支持 | 支持 | 支持 | 不支持 |
| K8S 集成 | 不支持 | 不支持 | 支持 | 支持 |
这边是对业内4种注册中心各纬度上的对比,Eureka是典型的AP类型,Zookeeper和Consul是典型的CP类型。如何选择取决你的业务是倾向A:高可用性 还是 C:强一致性。
当然,业务是复杂的,在真正的技术选型时,还是要根据自己的实际业务现状来判断。有一些倾向,比如你的系统是Spring Cloud体系下,那优先选择Eureka、Consul。
如果业务会更多向云原生对齐,则Consul、Etcd会是比较优先的选择。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!
 客服
客服


