本文主要借demo介绍基于Tendermint的区块链应用开发,这个demo很简单,主要包含以下功能:
- 扔漂流瓶
- 捞漂流瓶
- 之后投放者和打捞者可以相互传递[加密]信息
代码已上传至github。
Tendermint
Tendermint帮我们实现了PBFT,相当于搭了一个共识框架,包含两部分:
- Tendermint-core:PBFT共识算法实现;
- Tendermint-abci:定义了应用须实现的接口和调用规则,还实现了与外部通信的socket-server。官方的这部分源码可以看做是Go-abci,我们也可以根据需要编写其它语言的xxx-abci。
可以将其类比为传统应用的开发框架(如MVC),而我们要做的就是基于abci编写具体的区块链逻辑(为方便和清晰起见,本文用Go编写具体逻辑,自然abci就用官方的了),这就实现了服务端;而用户也需要一个客户端用来与区块链交互。
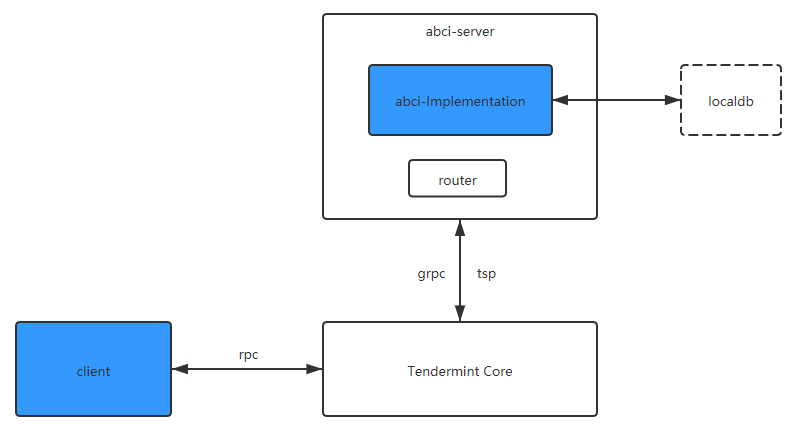
以上,Tendermint、服务端逻辑、客户端,三者组成了一个完整的区块链应用。
数据库
在动手编码之前,要考虑数据存储的问题,选择文本文件还是Oracle呢?区块链网络里大部分是普通电子设备,使用者亦是普通人,让他们事先安装大型数据库显然不现实,更不用说区块链本身不会出现复杂操作数据的业务。另外由于全节点数据的完备性,用不着通过网络去其它设备上查询数据,很多数据库自带的网络服务也不需要(SPV这种,业务单一,完全可以单独开放一个远程接口)。而文本文件、excel之类的,只适合人类使用,根本不能算作数据引擎。我们需要的是一个满足基本CUID的高效的本地数据库,目前大多区块链使用LevelDB作为存储引擎,这是C/C++编写的本地kv数据库,原作者也写了Go实现的版本,其原理可参看 半小时学会LevelDB原理及应用 ,godoc地址:https://godoc.org/github.com/syndtr/goleveldb/leveldb。LevelDB总体上采用了LSM-Tree的设计思想(LSM-Tree的虽说是数据结构,但更偏重于设计思路)。
LevelDB同时只能被一个进程使用。另,以太坊的数据存储于/chaindata目录下,运行后其下会生成一坨.ldb文件,而非网上常说的sst文件,这可能是跟13年的一次版本更新有关,Release LevelDB 1.14。另:LevelDB的k-v模式(顺序读效率不高)不适合relationship,即不适合有一定数据关联度的业务场景。
为方便使用,可以封装一些常用的数据库操作。顺便尝试下提供新操作的几种思路。
- 直接给leveldb.DB增加新方法:然而,给一个类型新增方法只能在该类型同个package中,否则编译时会报“Cannot define new methods on non-local type XXXX”的错误。此时,可以怀念下C#的扩展方法。
// 给leveldb.DB增加Set方法 func (db *leveldb.DB) Set(key []byte, value []byte) { //... err := db.Put(key, value, nil) //... }
- 既然无法在外部修改leveldb.DB的方法集,那么就在当前package建一个继承leveldb.DB的struct,即内嵌一个leveldb.DB类型字段, type GoLevelDB struct { *leveldb.DB } ,然后将上述代码的指针类型改为*GoLevelDB即可,很完美。不过,在封装Get方法的时候出问题了:
func (db *GoLevelDB) Get(key []byte) []byte { //... //Go不支持重载,或者说Go只把方法名作为唯一签名。 //这里原意是调用的父类的Get方法,但该方法被当前类的Get方法覆盖了,参数不一致导致编译失败 res, err := db.Get(key, nil) //... return res }
不支持重载,只能修改子类的方法名,蛋疼;或者改成如下方式。
-
type GoLevelDB struct { db *leveldb.DB }
和第2种的区别就是把is-a改为has-a,也不用担心方法重名的问题。不过我私以为若Go支持重载,第2种方式会好一点,至少不会嵌套太多层。
服务端
abci定义了如下接口:
type Application interface { // Info/Query Connection Info(RequestInfo) ResponseInfo // Return application info SetOption(RequestSetOption) ResponseSetOption // Set application option Query(RequestQuery) ResponseQuery // Query for state // Mempool Connection CheckTx(tx []byte) ResponseCheckTx // Validate a tx for the mempool // Consensus Connection InitChain(RequestInitChain) ResponseInitChain // Initialize blockchain with validators and other info from TendermintCore BeginBlock(RequestBeginBlock) ResponseBeginBlock // Signals the beginning of a block DeliverTx(tx []byte) ResponseDeliverTx // Deliver a tx for full processing EndBlock(RequestEndBlock) ResponseEndBlock // Signals the end of a block, returns changes to the validator set Commit() ResponseCommit // Commit the state and return the application Merkle root hash }
很明显,后面几个方法参与了区块链状态的更迭,我们就来捋捋交易从客户端提交到最终上链的过程(不精确):
- 节点a的客户端发起一笔交易tx;
- 节点a服务端调用CheckTx方法校验tx是否合法,若非法则丢弃,当做什么事都没发生过;
- 若合法,则将tx加入到本地mempool中,并向其它节点广播tx;
- 其它节点接收到tx,同样执行2-3步骤;
- 某轮决议开始,提议者搜集mempool中的txs,并发起投票,达成共识后,各节点调用BeginBlock开始将它们打包;
- 调用DeliverTx执行每笔交易并将其记录到区块中(一笔交易执行一次DeliverTx);
- 调用EndBlock表示打包完成;
- 发起共识决议,提议者将新区块广播给其它验证者;(共识决议在第5步完成)
- 其它验证者接收到区块后,调用DeliverTx执行每笔交易并校验结果,若没问题则广播commit请求(预提交)和新区块;
- 若节点收到超过2/3验证者的commit请求,调用Commit方法,更新整个应用状态。
假如将要打包的tx缓存起来,我们就可以在DeliverTx、EndBlock、Commit三个方法中选择其一实际执行tx,但是一般来说,交易执行都是放在DeliverTx,比较符合语义。EndBlock用于更新共识参数和Val集合,Commit用于更新整个应用状态(apphash),需要注意的是,本次提交的apphash若与上次提交的不同,则会继续产生新的区块(不管有没有新交易,就算设置consensus.create_empty_blocks=false,tendermint也会产生空区块,可参看 Enable no empty blocks #308 。),这似乎是tendermint的有意设计,但不知为何。
另Query方法接收的RequestQuery类型参数有Path和Data两个字段,Path是string类型,Data是[]byte,应该是对应于Http的get、post。示例代码中我是通过正则表达式解析Path查询各类数据,其实若是复杂查询/结构化查询,还是Data字段比较实用。
正则表达式的所谓零宽断言:只匹配位置,而不消费字符。下面举个例子。如 bw*q[^u]w*b,它能匹配“Iraq,Benq”。因为[^u]总是匹配一个字符,所以如果q是单词的最后一个字符的话,后面的[^u]将会匹配q后面的单词分隔符(可能是空格,或者是句号或其它的什么),接着后面的w+b将会匹配下一个单词,于是bw*q[^u]w*b就能匹配整个Iraq fighting。如果在这个例子中,我们只想匹配到Iraq,那么可以采用零宽负向先行断言(?!exp)的方式,bw*q(?!u)w*b,它将不会消费Iraq后面的空格或逗号等字符,因此w*也不会匹配到下一个单词。参看 【详细】正则表达式30分钟入门教程 之位置指定和后向位置指定部分。
客户端
demo采用命令行终端,基于cobra库。
1 var rootCmd = &cobra.Command{ 2 Use: "dbcli", 3 //throw:丢;salvage:捞;reply:回应。 ValidArgs要有定义Run[E],并与Args: cobra.OnlyValidArgs结合才起作用,表示参数值只能是预设值 4 //ValidArgs: []string{"throw", "salvage", "reply", "bbalj"}, 5 //Args主要是用来校验参数的 6 //Args: cobra.OnlyValidArgs, //cobra.ExactArgs(0), 7 // RunE: func(cmd *cobra.Command, args []string) error { //args并不包含flag;os.Args是包含flag的 8 // }, 9 } 10 11 func main() { 12 if err := rootCmd.Execute(); err != nil { 13 fmt.Println(err) 14 os.Exit(-1) 15 } 16 }
原本我想实现交互模式(类似mysql>),但cobra似乎没有提供相关方法,我们只好自己想办法,需要注意的是需要自解析用户输入,比如用户输入有空格,该空格是分隔参数还是参数内部的,要做区分。原本打算参考cobra解析命令行的源码,发现实际解析使用的是spf13/pflag库,而pflag只是加强了go标准库flag,而flag库也并没有涉及到参数值本身的具体解析,这部分工作依靠的是oa库,主要是oa.Args属性,它依赖更底层的代码。


// 摘自go/src/os/proc.go // Args hold the command-line arguments, starting with the program name. var Args []string func init() { if runtime.GOOS == "windows" { // Initialized in exec_windows.go. return } Args = runtime_args() } func runtime_args() []string // in package runtime
如注释所示,windows下是在exec_windows.go中实现,其它操作系统的实现没找到,应该是使用其它语言编写或直接调用的系统api。进exec_windows.go中,发现关键函数readNextArg:
1 // readNextArg splits command line string cmd into next 2 // argument and command line remainder. 3 func readNextArg(cmd string) (arg []byte, rest string) { 4 var b []byte 5 var inquote bool 6 var nslash int 7 for ; len(cmd) > 0; cmd = cmd[1:] { 8 c := cmd[0] 9 switch c { 10 case ' ', 't': 11 if !inquote { 12 return appendBSBytes(b, nslash), cmd[1:] 13 } 14 case '"': 15 b = appendBSBytes(b, nslash/2) 16 if nslash%2 == 0 { 17 // use "Prior to 2008" rule from 18 // http://daviddeley.com/autohotkey/parameters/parameters.htm 19 // section 5.2 to deal with double double quotes 20 if inquote && len(cmd) > 1 && cmd[1] == '"' { 21 b = append(b, c) 22 cmd = cmd[1:] 23 } 24 inquote = !inquote 25 } else { 26 b = append(b, c) 27 } 28 nslash = 0 29 continue 30 case '\': 31 nslash++ 32 continue 33 } 34 b = appendBSBytes(b, nslash) 35 nslash = 0 36 b = append(b, c) 37 } 38 return appendBSBytes(b, nslash), "" 39 }
其中对双引号做了处理,注释中还提供了一个网址How Command Line Parameters Are Parsed,应该是关于这方面的算法说明,日后再看。
序列化
当我们在说序列化的时候,我们在说什么。序列化说白了就是数据转化,或者说一一对应的映射关系。就内存场景来说,一个对象序列化为另一个对象,本质上它们都一样,都是存储在内存中的0、1序列,只是同一个东西不同的数据表达。比如将一个数值序列化(或者说转化)成字符串类型,或者将数值int32转为数值int8,那么内存中的存储空间和存储数据都不会一样,字符串还要看用的什么编码。再如我们将一个对象序列化为byte[],不同的方案会产生不同的结果。比如使用C指针将物理数据直接映射出来,或者以json方式序列化,或者protobuf序列化,会产生不同的byte[];反之亦然。
不管是json编码还是二进制编码,物理上存储的都是二进制,json编码包含于二进制编码,我们可以根据需要自定义二进制编码,一般是为了减少存储占用的空间。比如json编码,对1、2等数值类型是按字符串格式编码(如utf8格式,1编码的就是0x31,12占两个字节0x310x32),而我们自定义二进制,完全可以把12存储在一个字节里面,该字节值就是数值本身;就算不是数值,而是字符串本身编码,我们也可以在utf8编码后再压缩,类似gzip。
go中的序列化方式,可参看 Golang 序列化方式及对比,但是文中gob的测试代码其实可以改良下,将enc/dec两个变量移到循环外,如此可在循环内复用,这将发挥gob上下文的优势。
protobuf的变长编码针对的是数值类型,so应该只对数值字段多的类型有压缩的意义。
go对字符串是utf8编码,基本不用担心中文乱码问题。
vscode-go开发环境
在国内,搭建Go开发环境都不会太顺利,下面我就说说在vscode中搭建环境可能会遇到的问题和解决方法。
Go开发环境需要vscode安装一些插件,而项目中也有引用的类库,这两者都可能涉及到相关站点在墙外的情况,而我们也要分别设置代理。首先,给vscode本身设置代理,使得安装插件没有问题;其次,在命令行窗口设置http_proxy,使得dep顺利进行。也可以在vscode终端窗口设置http_proxy(vscode的终端就是个命令行交互环境,使用的还是操作系统的shell,本质上独立于vscode),但博主发现似乎并不起作用。
在代理什么都设置好后,vscode安装插件时仍可能遇到问题,比如文件中已经存在的golang.orgxtools目录关联的git源码网址不是插件要求的源码网址,原因可能是之前手动到github里下载的tools源码,将tools目录移除重新跑一遍安装插件的步骤即可。
安装goimports时可能会timeout等错误,参考 安装goimports 解决。
项目方面,具体到我们这个demo,遵照tendermint官方文档,make get_tools。我是windows10系统,使用bash命令进入到自带的Ubuntu子系统,就可以使用内置的make了。需要注意的是,若设置了系统变量GOPATH,且是以分号分隔的多个文件夹,那么切换到Ubuntu后,由于linux系统是按冒号分隔的,所以它会把分号当做文件夹名的一部分,导致自动创建一些奇怪目录。如果是其它windows系统,可以安装mingw,定位到安装目录的bin目录下,就可以使用mingw-make操作了(可以将mingw-make重命名为make),可能会报错:
process_begin: CreateProcess(NULL, env bash F:Documentcodetenderminttendermintscriptsget_tools.sh, ...) failed. make (e=2): 系统找不到指定的文件。
如果不是get_tools.sh的路径问题,那就应该是bash冲突了(比如系统中安装了git,同时把git目录也配置到PATH下,实际定位的可能就是git的bash了)。
注意tendermint所需的最低Go版本。
我们要严格遵循Go的目录规范,若将代码直接置于src目录下,则执行dep相关操作时,会抛出“root project import: dep does not currently support using GOPATH/src as the project root”错误。需要在src下再建一个目录,把代码拷进这个子目录再执行dep。Go遵循约定大于配置的原则,它在项目中引入所有依赖类库的代码,而这些类库也是放置于src目录下,所以需要按子目录分开。另关于依赖项搜寻Support vendor directory as $GOPATH/src/vendor #313 应该有参考价值,另可参看 dep init fails if in not in $GOPATH[...]/src/{somedir..} #148。
dep似乎会将GOPATHsrc下的依赖也复制到vendor下,感觉是不是没这必要。
经验:最好在项目刚开始搭建就 dep init,否则在代码敲了一个阶段后,已经import了多个外部依赖,当这时候再 dep init,如果出现错误,将不会生成Gopkg.toml,如果是因为版本问题导致的错误,你都没办法通过编辑Gopkg.toml的方式解决。比如我就遇到这种情况,dep init -gopath, -gopath表示先去本地GOPATH目录找依赖库,找不到再去网上拉取,结果我的本地库版本不是master分支,而貌似dep默认的就是master,导致“v0.30.2: Could not introduce github.com/tendermint/tendermint@v0.30.2, as it is not allowed by constraint master from project tuoxie/driftbottle.”这样的错误提示(dep也是一根筋,它会把这个库的所有release版本都比对一遍看满不满足constraint)。此时也不是没办法,我们可以把入口函数main所在文件整个注释掉,这样dep就不会遍历代码文件,但仍然会生成Gopkg.toml,这个时候就可以手动编辑约束版本号了。
go install 不会把vendor目录下的所有包无脑打包进exe文件,而是会根据实际依赖打包,这样也使得我们可以多个[子]项目使用同一个vendor,减小磁盘占用和复用已下载的依赖包,而不必担心exe文件过大的问题。
目前vscode调试go尚不能支持交互模式的命令行调试,没有如python那样可以在launch.json设置console属性[为externalTerminal]。
其它
作为区块链最广泛应用的数字货币已经不再像不久以前一样能够随意撩拨投机者的神经,但这项技术在其它更实用的领域或许仍值得期待。比如区块链的共识机制、区块时间戳、防篡改特性,似乎天生是为知识产权保护打造的,然而迄今为止市面上尚未出现让人眼前一亮的产品。前段时间看到一则新闻,说百度上线了一个保护图片版权的区块链项目“图腾”,有兴趣的同学可以去了解下。如果我要实现类似的知识产权链,会考虑文件相似度判别、[使用代币]支付版权费及支付策略(买断or按次付款等)等等,交易媒介和交易标的都在链上,形成闭环。链上闭环可不受外部实体困扰,以区块链二代的明星特性“智能合约”为例,一旦与外部有所关联,就无法保证合约的事务完整性,可参看我之前的观点。
Tendermint里有很多ethereum的影子,比如gas、db的封装等,部分思路和代码应该是参考了ethereum的实现。
ethereum(以太坊)相关概念:
MPT:即Merkle Patricia Tree,是Merkle Tree 和Patricia Tree结合的产物。Patricia Tree又是Trie Tree的一种变化。参考资料:Trie原理以及应用于搜索提示,以太坊MPT原理,你最值得看的一篇。这两篇偏向于原理,若要了解具体细节,可看 干货 | Merkle Patricia Tree 详解。
叔区块
gas:一直很好奇以太坊是怎么做到计算实际使用gas量的,特别是有控制跳转语句的时候,最可靠的方式是实际运行时实时计算gas,那这个应该是由EVM实现的。具体可看 以太坊虚拟机及交易的执行,以太坊智能合约虚拟机(EVM)原理与实现。
数据结构与存储方式:以太坊源码情景分析之数据结构,[以太坊源代码分析] II. 数据的呈现和组织,缓存和更新
个人认为区块链目前普遍存在的问题:
- 升级困难(侧链?)
- 维护困难(当单节点故障时,只能依靠该节点自身能力处理,对于普通用户来说,无疑是棘手的)
- 随着时间的推移,数据量会变得越来越大,全节点将相应变少,最终形成某种意义上的中心化网络
更多资料:
以太坊源码深入分析(7)-- 以太坊Downloader源码分析
转载请注明本文出处:https://www.cnblogs.com/newton/p/9611340.html
- 还没有人评论,欢迎说说您的想法!



 客服
客服


