★微服务系列
微服务1:微服务及其演进史
微服务2:微服务全景架构
微服务3:微服务拆分策略
微服务4:服务注册与发现
微服务5:服务注册与发现(实践篇)
微服务6:通信之网关
微服务7:通信之RPC
微服务8:通信之RPC实践篇(附源码)
微服务9:服务治理来保证高可用
微服务10:系统服务熔断、限流
微服务11:熔断、降级的Hystrix实现(附源码)
微服务12:流量策略
微服务13:云基础场景下流量策略实现原理
1 背景
在复杂的互联网场景中,不可避免的会出现请求失败的情况。
从程序的的响应结果来看,一般是Response返回5xx状态的错误;从用户的角度去看,一般是请求结果不符合预期,即操作失败(如转账失败、下单失败、信息获取不到等)。
偶发的不可避免的5xx请求错误,产生的原因有很多种,比如:
- 网络延迟或者抖动
- 服务器资源不足(CPU、内存走高、连接池满)
- 服务器故障
- 符合某些特定条件下的服务程序bug(大都非必现)
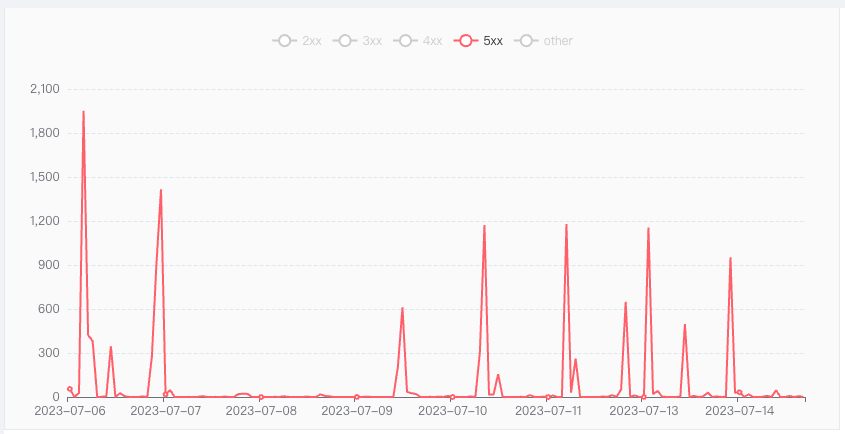
2 系统稳定性等级划分
大部分服务容忍低频、偶发的5xx错误,并使用可用性级别来衡量系统的健壮性,级别系数越高,健壮性越好,如下:
| 等级描述 | 故障时长(年) | 可用行等级 |
|---|---|---|
| 基本可用性 | 87.6h | 99% |
| 较高可用 | 8.8h | 99.9% |
| 非常高的可用性(大部分故障可自动恢复) | 52m | 99.99% |
| 极高可用性 | 5m | 99.999% |
对于强系统可靠性、强结果预期性 要求的系统,如转账、下单、付款,即使微小的可用性降级也是不可接受,用户强烈需要接收到正确的结果。
可以想想你付款的时候发现付款失败有多么惊慌,订外卖的时候获取信息失败有多么沮丧,这些都是用户痛点。
3 异常的治理手段
3.1 采用异常重试实现故障恢复
通过上面的故障原因分析我们知道,排除了必现的程序逻辑错误,大部分环境导致的错误是可以通过重试进行恢复的。
治理的手段主要是采用 异常重试 来实现的,通过重试负载到健康实例上(实例越多重试成功率越高),降低用户感知到的故障频率。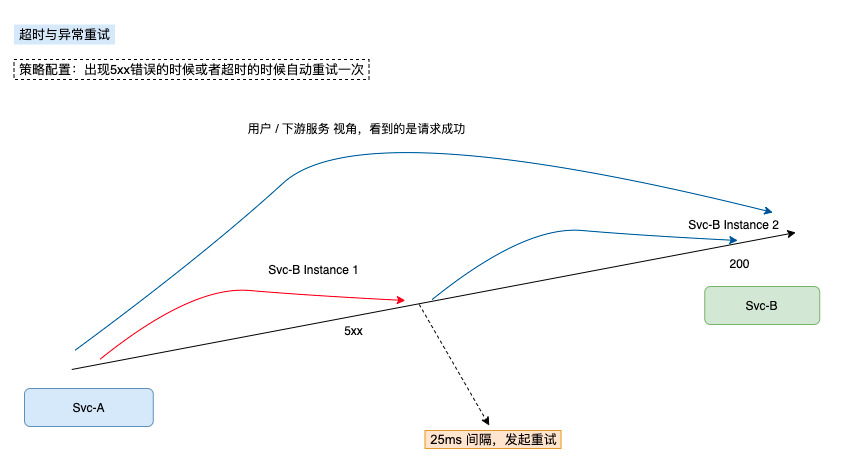
执行过程说明
- 这边以示例服务 Svc-A 向 Svc-B 发起访问为例子。
- 第1次执行失败之后,根据策略,间隔25ms之后发起第2次请求。
- 会看到有两条日志,日志的trace_id 一致,说明他是同一个调用过程(1个调用过程,包含2次请求,首发1次与重试1次)
- 请求方为同一个实例 Svc-A-Instance1,说明请求发起方一致。
- 被请求方发生了变动,说明调度到新的实例(Svc-B-Instance1 到 Svc-B-Instance2)。
- 返回正常的 200 。
因为我们的负载均衡模式默认是RR,所以实例越多,实际上重试成功的概率会越高。比如有50个实例,其中一个实例出故障,导致执行返回5xx,那么第二次请求的时候一般来说会有 49/50 的成功概率。如下图: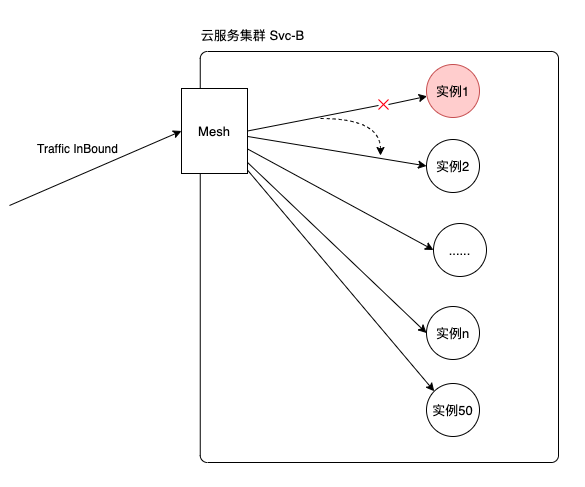
3.2 策略实现(Service Mesh方案)
注释比较清晰了,这边就不解释了。
# VirtualService
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: xx-svc-b-vs
namespace: kube-ns-xx
spec:
hosts:
- svc_b.google.com # 治理发往 svc-b 服务的流量
http:
- match: # 匹配条件的流量进行治理
- uri:
prefix: /v1.0/userinfo # 匹配路由前缀为 /v1.0/userinfo 的,比如 /v1.0/userinfo/1305015
retries:
attempts: 1 # 重试一次
perTryTimeout: 1s # 首次调用和每次重试的超时时间
retryOn: 5xx # 重试触发的条件
timeout: 2.5s # 请求整体超时时间为2.5s,无论重试多少次,超过该时间就断开。
route:
- destination:
host: svc_b.google.com
weight: 100
- route: # 其他未匹配的流量默认不治理,直接流转
- destination:
host: svc_c.google.com
weight: 100
4 总结
云基础场景下的治理手段各种各样,这边讲解了初级版的异常重试,让用户有一个更优良的使用环境。
后续的章节我们逐一了解下超时保护、故障注入、熔断限流、异常驱逐等高级用法。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!
 客服
客服


